
지도 학습: 기계 학습을 통해 답을 내면 이 답이 맞았는지 틀렸는지를 컴퓨터가 알 수 있는 학습
< 답이 있는 데이터를 가지고 답을 맞출 수 있는 패턴을 찾는 것 >이라고도 말합니다.
이는 학생이 답지를 보고 답을 맞추기 위해 머리 쓰는 것과 비슷합니다.
답이 있는 상황에 잘 맞춘 다음에,
답이 없는 새로운 문제에 대해서도 잘 맞추는게 좋은 알고리즘이라고 합니다.
실제로 학습 중 알고리즘의 성능 평가, 일반화능력 평가를 할 때
답이 있는 상태에서 얼마나 잘 맞췄는지 평가
(답이 없는)새로운 데이터가 왔을 때 답을 얼마나 잘 맞추는지 평가
이렇게 두 가지를 합니다.
그리고 알고리즘 평가를 할 때는 ‘혼돈행렬’을 이용합니다.
혼돈행렬: 알고리즘이 얼마나 맞았나 틀렸는지를 평가하는 행렬
혼돈행렬을 예시와 함께 설명하겠습니다.

위는 기계가 얼마나 암 검사를 잘 하는지,
그 알고리즘을 평가하는 혼돈행렬입니다.
혼돈행렬을 이용하면 (정확도,정밀도,재현율)을 구할 수가 있습니다.
정확도 (Accuracy) = 알고리즘이 전체 판정한 것 중 맞은 비율
=> 70 / 100
정밀도 (Precision) = 알고리즘이 암이라고 판정한 환자 중 실제 암 환자 비율
=> 30 / 50
재현율 (Recall) = 실제 암 환자 중 알고리즘이 암이라고 판정한 환자 비율
=> 30/40
위 세 개는 알고리즘을 평가할 때 중요한 수치가 됩니다.
추가해서 두 개의 평가 수치가 있습니다.
거짓긍정율: 원래 암 환자가 아닌데 알고리즘이 암 환자라고 한 비율 (20/60)
거짓부정율: 원래 암 환자였는데 알고리즘이 정상이라고 한 비율 (10/40)
예시를 알아 봤으니 더 자세히 혼돈행렬을 알아 봅시다!

TP: Positive라고 예측했는데 정말 Positive인 것
TN: Negative라고 예측했는데 정말 Negative인 것
FP: Positive라고 예측했는데 Negative인 것
FN: Negative라고 예측했는데 Positive인 것
Accuracy : 전체에서 맞춘 비율
=> n11 + n22 / n11 +n12 + n21 + n21 < 대각선 합/전체 합 >
Precision: Positive라고 예측한 것 중에 정말로 Positive인 비율
=> n11 / n11 +n21 < 1행 1열 / 1열 세로 합 >
Recall: 실제 positive중에 알고리즘이 positive라고 한 비율
=> n11 / n11 +n12 < 1행 1열 / 1행 가로 합 >
[ P.s. 정밀도와 재현율 공식이 헷갈리면 ‘정세재가’로 외우면 좋음!! ]
거짓 긍정율: 진짜 negative중에 알고리즘이 positive라고 한 비율
=> n21 / n21+n22 < 2행 1열 / 2행 가로 합 >
거짓 부정율: 진짜 positive중에 알고리즘이 negative라고 한 비율
=> n12 / n11+n12 < 1행2열 / 1행 가로 합 >
[ P.s. 거짓 긍정율이 앞이 negative, 거짓 부정율은 앞이 positive ]
이를 R 프로그래밍으로 확인해봅시다!
(의사결정나무 실습에 사용한 cart 기계학습 알고리즘을 평가할 것입니다!)
Script)
# 학습이 얼마나 잘 됐는지 살펴보기 # class를 안 넣으면 0과 1사이의 값도 나오는데 우리는 0 or 1값을 원함 predlmsi<-predict(object=fitTree,newdata=bank,type='class') # 혼돈 행렬 만들기 ctable<-table(bank$PersonalLoan,predlmsi) ctable # Accuracy(정확도) 계산 accuracy=(ctable[1,1]+ctable[2,2])/length(predlmsi) # Precision(정밀도) 계산 precision=ctable[1,1]/(ctable[1,1]+ctable[2,1]) # Recall(재현율) 계산 recall=ctable[1,1]/(ctable[1,1]+ctable[1,2]) accuracy;precision;recall;
( table함수를 사용하면 혼돈행렬을 만들 수 있습니다! )
결과)
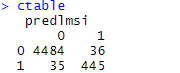
혼돈행렬 (Confusion Table)

위에서 아래로 차례대로 (정확도,정밀도,재현율)입니다.
거의 다 1에 수렴하니 학습이 잘 됐다고 할 수 있겠네요!!
지금까지 데이터 마이닝의 ‘혼돈행렬’을 알아 보았습니다.