
의사결정나무는
한 단계 거쳤을 때마다 좀 더 정리되게 집합을 나눈 나무입니다.
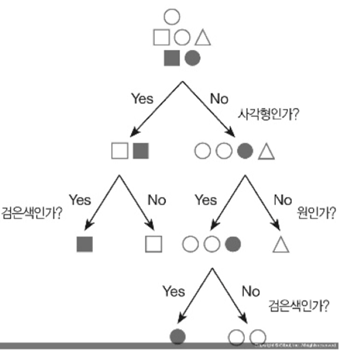
이러한 나무는 ‘cart’라는 알고리즘을 통해 구현이 가능합니다.
cart알고리즘은 집합을 분리해가며 지니지수(집합 원소의 무질서도 척도)를 확인하고,
가장 지니지수가 낮은 경우(무질서도가 작아서 정리가 잘 된 경우)를 찾으면 분리를 멈춥니다.
그렇게 집합 분리를 계속하면 위 그림과 같이 ‘의사결정나무’ 형태를 만들 수 있습니다.
맨 처음 집합에서 지니지수가 낮은 쪽으로 쪼개서 -> 사각형 집합을 만들고
사각형 집합에서 지니지수가 낮은 쪽으로 쪼개서 -> 검은색 사각형 집합을 만든다.
이렇게 생각하면 됩니다.
이번 실습에는 cart알고리즘을 이용해서 Bank데이터를 분석해보겠습니다.
Script)
# 데이터 불러오기
bank <- read.csv(file='https://goo.gl/vE8GyN')
# 데이터 구조파악
str(bank)
head(bank)
# 요약 통계량 확인
summary(bank)
# personalLoan을 팩터형으로 강제 변환한다.
bank$PersonalLoan<-as.factor(x=bank$PersonalLoan)
# 팩터형으로 변환하면 테이블 형태로 나타낼 수 있다.
table(bank$PersonalLoan)
# 지니지수를 이용한 cart알고리즘은 rpart패키지에 존재한다.
install.packages("rpart")
library(rpart)
# 간단한 모델 만들기
# personalLoan변수를 맞출건데 .(나머지 전체 변수)를 사용한다. Data는 bank라고하는 데이터 프레임에서 가져온다.
fitTree<-rpart(formula=PersonalLoan~.,data=bank)
print(fitTree)
plot(fitTree)
# 시각화한 자료에 문구를 추가한다
text(fitTree)
은행이 Personal Loan(개인 융자)를 해주기 위해서는 고객들의 정보가 필요합니다.
고객의 < 수입,가족,교육,채무 이행/불이행 > 등의 정보를 확인하고 대출의 여부를 결정하지요!
우리의 목표는 고객의 정보에 근거해서 채무 이행을 했는지 안 했는지를 확인하는 ‘의사결정나무’를 만드는 것입니다.
위 스크립트에서, bank(은행 고객 데이터 모음)의 PersonlLoan(개인 융자)속성은 여러 데이터를 가지고
그 데이터는 0과 1로 나뉩니다.
0은 채무 불이행이고, 1은 채무 이행입니다.

채무 이행을 했는지 안 했는지 맞춘다는 것은 PersonalLoan변수를 맞춘다는 것이고
고객의 정보에 근거한다는 것은 나머지 전체 변수(나이,소득,가족 등)를 이용한다는 것입니다.
cart알고리즘이 포함된 rpart함수를 이용하면 쉽게 해결이 가능합니다.
fitTree<-rpart(formula=PersonalLoan~.,data=bank)
// PersonalLoan(채무 이행도)를 조사하는 트리(의사결정나무)를 만드는데
‘.(나머지 전체 변수)’를 이용해서 만든다. 데이터는 bank에 있다.
결과)

소득이 113.5 이상이고 교육이 1.5 이상이면 채무 이행을 한다.
소득이 113.5 이상이고 교육이 1.5 이하지만 가족이 2.5명 이상이면 채무 이행을 한다.
등등의 결과가 나오게 됩니다.
은행이 단순히 고객의 정보를 보고 평가하는 것보다
위의 ‘의사결정트리’를 보고 어떤 사람이 채무를 하고 어떤 사람이 채무 불이행을 하는지 알면
더 완전한 융자 시스템을 갖추게 됩니다!
지금까지 데이터 마이닝의 ‘의사결정나무’를 알아 보았습니다.