
연관분석: 데이터 간의 연관성을 파악하는 것,
마케팅에서 (고객의 장바구니에 들어있는 품목 간의 관계를 탐구하는) 장바구니 분석에 주로 사용되는 기법
연관성: 사건A가 일어났을 때 사건B가 일어나면 연관성이 있다고 합니다.
이는 마치 규칙 같다고 해서 연관 규칙이라고도 하고, 기호로 A=>B (If A, then B)와 같이 표시합니다.
마케팅 관점에서 보면,
A, B는 고객이 구매한 아이템들의 집합 (아이템 집합)입니다.
A (컵라면,참치캔,새우깡) -> B (맥주)
(컵라면,참치캔,새우깡) 아이템을 사는 고객은 (맥주)아이템도 산다는 의미를 가집니다!
연관분석 효과) 효과적인 매장 진열, 패키지 상품 개발 등에 활용됨
연관분석은 지식의 발견을 위한 알고리즘이며 답이 정해져 있지 않은 비지도학습입니다!
컴퓨터에게 어떻게 연관성을 알려줘야 할까요?
연관성을 측정하는 아래의 세 가지 식을 알려주면 됩니다!
지지도 (support) : Itemset을 포함하는 거래의 수 / 전체 거래 수
ex) 맥주와 기저귀가 동시에 판매된 거래 수/ 전체 거래수
고객1 {참치캔,맥주,기저귀}
고객2{맥주,기저귀,새우깡}
고객3{양파링,신라면,새우깡}
=> 2/3
= P(A) : 맥주와 기저귀(A)가 동시에 판매된 거래 비율 [ 2/3 ]
신뢰도 (confidence) : A와 B가 포함된 거래 수/ A가 포함된 거래 수 (비율로 계산해도 같음)
ex) 맥주(A)와 기저귀(B)가 동시에 판매된 거래 수 / 맥주(A)만 판매된 거래 수
=> 2/2
= P(A ∩ B) / P(A) = P(B|A)
: 맥주(A)와 기저귀(B)가 같이 판매된 거래 비율 / 맥주(A)가 판매된 거래 비율 [ (2/3) / (2/3) ]
향상도 (lift): B가 거래되는 비율 중 A와의 관계가 고려되어 거래되는 비율 (수가 아니라 비율로 계산)
ex) 신라면(A)이 판매됐을 때 새우깡(B)도 판매된 비율 / 새우깡(B)이 판매된 비율
=> P(B|A) / P(B) = P(A ∩ B) / P(A) * P(B)
: [ { (1/3) / (1/3) } / (2/3) ] = [ (1/3) / (1/3 * 2/3) ]=3/2
ex) 신라면(A)이 판매됐을 때 참치캔(B)도 판매된 비율 / 참치캔(B)이 판매된 비율
=> [ { (0/3) / (1/3) } / (1/3) ] = [ (0/3) / (1/3 * 1/3) ] = 0
Lift > 1 : A와 B가 연관이 있다. (독립이 아니다)
Lift < 1 : A와 B가 연관이 없다. (독립이다)
이 공식을 이용해서 연관성을 어떻게 측정할 수 있을까요?
예시를 통해 알아 봅시다!
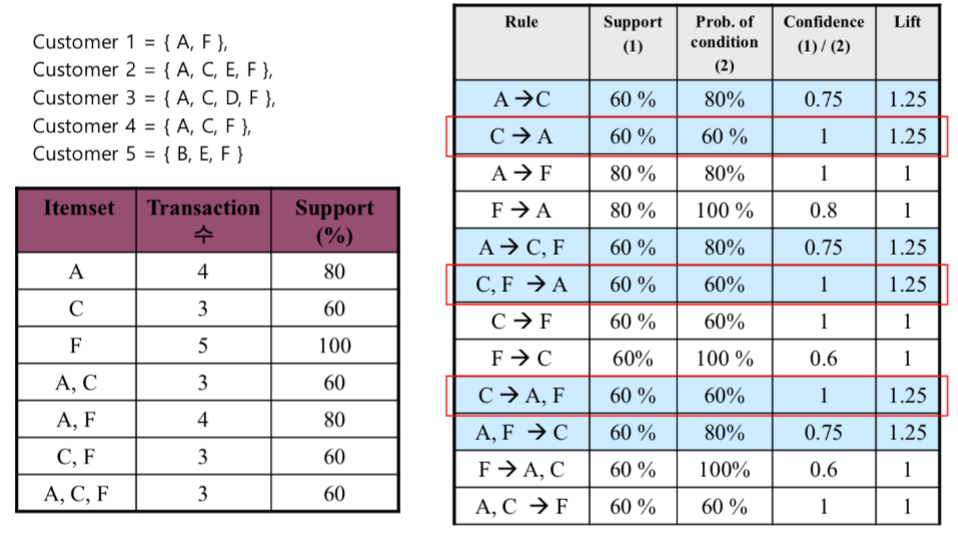
위와 같은 테이블이 있을 때 [첫 번째 빨간 색 박스] 부분만 어떻게 된건지 살펴 봅시다!
1) C->A
지지도( C,A 구매 비율 구하기! ):
C,A를 포함하는 거래의 수 / 전체 거래 수 => (3/5) = 60%
신뢰도 ( C를 구매한 사람 중 A도 구매한 사람의 비율 구하기! )
: A와 C가 포함된 거래 수/ C가 포함된 거래 수 => (3/3) =1
향상도 ( C와 A가 연관이 있는지 없는지 구하기! )
: C가 거래되는 비율 중 A와의 관계가 고려되어 거래되는 비율 => P(A ∩ C) / P(A) * P(C) = 3/5 / (4/5 * 3/5) = 1.25
이제 아이템 간 연관성 경우의 수를 알아 봅시다!
아이템 품목이 7개라고 할 때,
품목 집합의 개수만 (2^7-1)개가 됩니다.
{a},{b},…{a,b,c,d,e,f,g} — 2^7-1개
그럼 연관성 경우의 수는 (2^7-1)의 n배로 많아지네요!
이 모든 경우를 고려하는 것은 너무 힘드니, 알고리즘으로 문제를 해결합니다!
Apriori 알고리즘
: 연관분석에서 모든 아이템 간 연관성 경우의 수를 찾는 것은 힘드니, 최소 지지도,신뢰도,향상도를 넘는 아이템 품목 집합을 만들고 연관성을 분석하는 학습 알고리즘!
개별 품목 중에서 최소 지지도를 넘는 모든 품목을 찾는다.
그 안에서 최소 지지도를 넘는 2가지 품목 집합을 찾는다.
그 안에서 최소 지지도를 넘는 3가지 품목 집합을 찾는다.
위의 방법을 반복적으로 하여 최소 지지도가 넘는 빈발 품목 집합들을 찾는다.
찾은 집합들로 연관성 분석을 한다.
아래 예시를 통해 이해해봅시다!
[ c,e,f,k,n,s ] — 아이템 품목 5개!!

1) 3번 이상 발생하는 모든 품목을 찾는다.
=> [ c,e,f,k,n ]
2) 위 품목으로 2가지 품목 집합을 만든다.
=> (c,e), (c,f), (c,k), (c,n), (e,f), (e,k), (e,n), (f,k), (f,n), (k,n)
2) 위에서 3번 이상 발생하는 아이템만 추려서 (2가지 품목 집합)을 찾는다!
=> (c,k), (c,n), (e,f), (f,n), (k,n)
3) 위 집합으로 (3가지 품목 집합)을 만든다!
=> (c,k,n), (c,f,n), (e,f,n), (f,n,k)
: (2개 요소 집합)을 2개 합쳐서 (3개 요소 집합)을 만든다면, 요소 하나는 공통되는게 있어야 됨!
3) 위에서 3번 이상 발생하는 아이템만 추려서 (3가지 품목 집합)을 찾는다!
=> (c,k,n)
최종) (c,k), (c,n), (e,f), (f,n), (k,n) , (c,k,n) 간 연관성 분석만 한다!
ex) (c,k) -> (c,k,n) 에 대한 지지도, 신뢰도, 향상도 구하기!!
이를 R 프로그래밍으로 확인해봅시다!
# Arules에 내장되어 있는 Groceries데이터 분석
# Groceries는 식료품에 대한 (아이템 품목 집합) 데이터
install.packages("arules")
library(arules)
# 데이터 로딩함수(data) 사용해서 데이터 불러오기
data(Groceries)
# 데이터 살펴 보는 함수
inspect(Groceries)
# 아이템 빈도수 추출
itemFrequency(Groceries)
# 어느 정도 비율이 되는 아이템만 표시
itemFrequencyPlot(Groceries,support=0.1)
# 발생 건수 상위 10개만 추출
itemFrequencyPlot(Groceries,topN=10)
#Apriori 알고리즘 사용
# 최소 지지율 0.01, 최소 신뢰도 0.25, 최소 아이템 2
myrules <-apriori(data=Groceries,parameter=list(support=0.01,confidence=0.25,minlen=2))
inspect(myrules)
summary(myrules)
# 최소 지지율, 최소 신뢰도를 올리고 알고리즘 사용 -> 데이터 줄어들음
myrules2 <-apriori(data=Groceries,parameter=list(support=0.03,confidence=0.3,minlen=2))
inspect(myrules2)
summary(myrules2)
# 결과 저장
write(myrules,file="groceryrules.csv",sep=",",quote=TRUE,row.names=FALSE)
결과)
inspect(Groceries)

inspect(myrules) = ‘groceryrules.csv’

첫 줄 해석)
“hard cheese”를 산 사람 중 “whole milk”를 산 사람의 비율은 40퍼이고 신뢰도는 1.6으로 연관이 있습니다.
두번째 줄 해석)
“butter milk”를 산 사람 중 “other vegetables”를 산 사람의 비율은 37퍼이고 신뢰도는 1.9로 연관이 있습니다.
지금까지 데이터 마이닝의 ‘연관분석’을 알아 보았습니다.