
※ Deep Learning From Scratch (밑바닥부터 시작하는 딥러닝)에 대한 정리 자료입니다.
가중치 초기화 (Weight Init)
학습을 진행할 때, 가중치 초깃값의 설정은 매우 중요하다. 유명한 가중치의 초깃값 설정 방법으로 Xavier와 He가 제시한 방법이 있다.
Xavier는 평균이 0이고 표준편차가 √(1/n)인 정규분포로 가중치를 초기화하는 것이 좋다고 주장한다.
(n은 각 은닉층의 노드 개수)
He는 평균이 0이고 표준편차가 √(2/n)인 정규분포로 가중치를 초기화하는 것이 좋다고 주장한다.
사실 이러한 주장이 나오기 전에는 표준정규분포(평균이 0, 표준편차가 1)를 사용하자는 의견도 나왔다.
W=np.random.randn(node_num, node_num) *1 # 가중치 분포의 표준편차 = 1
그러나 각 층의 활성화 값(Sigmoid(XW+b))들을 시각화해보니 0 혹은 1에 몰려있는 그림이 나왔다.

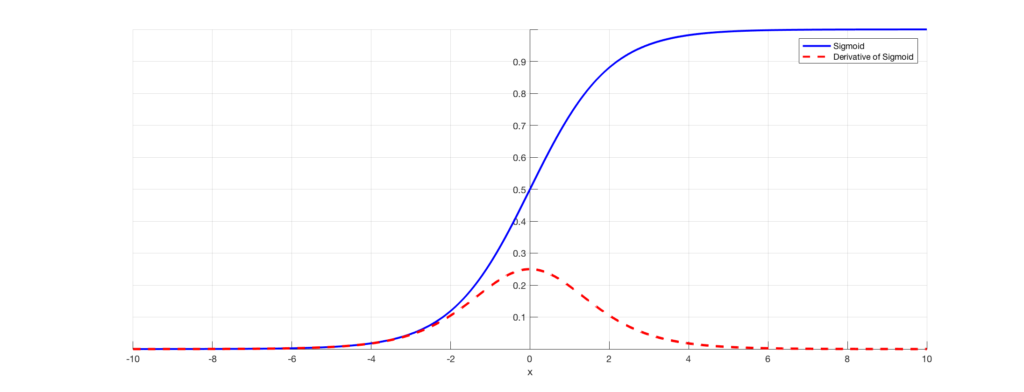
Sigmoid 함수는 출력이 0혹은 1이 되면 미분이 0에 다가간다. 그래서 데이터가 0과 1에 치우쳐 분포하게 되면 역전파의 기울기 값이 점점 작아지다가 사라진다. 이것이 기울기 소실(Gradient Vanishing)이라고 알려진 문제이다. 층을 깊게 하는 딥러닝에서는 기울기 소실은 심각한 문제가 될 수 있다.
결국 위 방법으로는 올바른 학습이 될 수 없다는 것이 확인되었다.
따라서 Xavier가 제시한 방법으로 시각화를 해보았다.
W=np.random.randn(node_num,node_num)/np.sqrt(node_num) # 가중치 분포의 표준편차 = √(1/n)
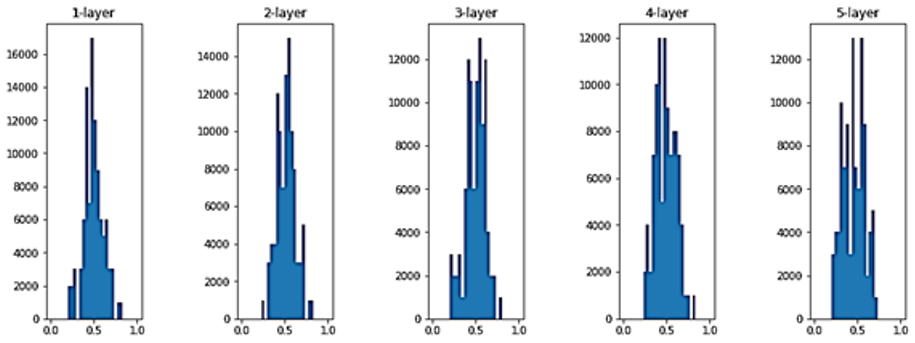
이 방법을 써보니 활성화 값들이 골고루 퍼져 있어서 학습이 잘 되었다고 한다.
또한 He가 제시한 방법도 마찬가지였다.
또한 연구 결과, Sigmoid를 이용할 때는 Xavier가 제시한 방법이 더 좋았다고 하고,
ReLU를 이용할 때는 He가 제시한 방법이 더 좋았다고 한다!
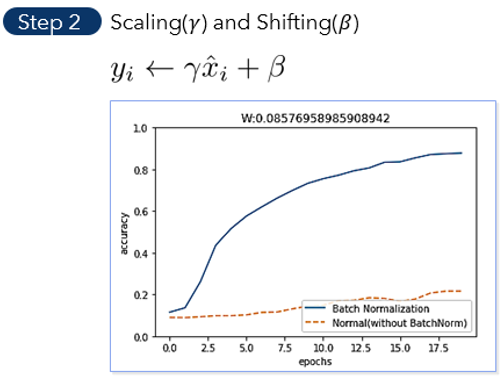
Batch Normalization
딥러닝 각 층의 입력 데이터는 잘 분포돼있어야 더 성능이 좋다. 왜냐하면 데이터가 밀집해있으면 다양성이 떨어지고 결국 비슷한 데이터들로만 학습하는 효과가 발생하기 때문이다.
따라서 나온 방법이 Bach Normalization이다.
이는 Affine한 결과를 잘 분포시키기 위해 표준화를 하는 것이다.
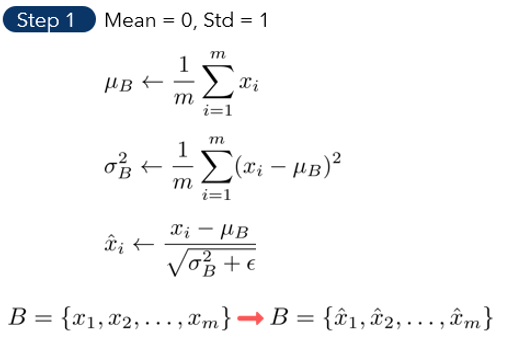
1. 평균을 빼고 표준편차로 나누는 표준화 공식을 이용한다.
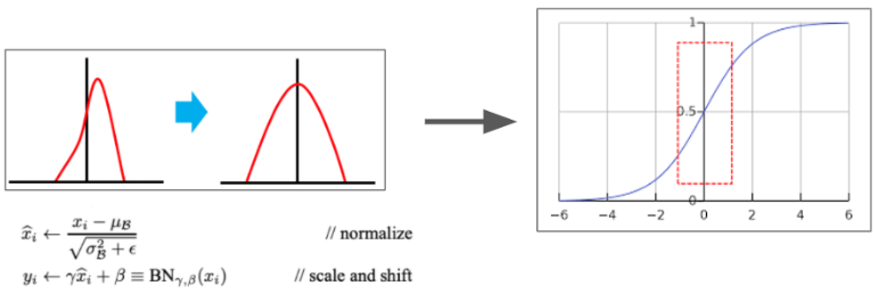
2. Normalizaton을 거치고 바로 Activation Function의 input으로 사용할 경우, 정의역이 위 빨간색 점선 박스쪽으로 이동된다. 그러면 linear한 형태의 Activation Function이 될 수 있다. 따라서 Non-linearity를 높이기 위해 데이터의 분포에 절절하게 scale & shift를 시킨다. scale을 해주는 것이 r이고, shifting을 해주는 것이 B이다.
오버피팅 대처 (Avoid Overfitting)
오버피팅이 발생하는 가장 근본적인 이유는 Parameter가 너무 많기 때문이다.
분류 모델이라고 가정하면, Parameter들로 이루어진 모델의 수식(ex. σ(W2(σ(W1X+b1))+b2))은 결정 경계가 되는데, 이 결정 경계가 학습 데이터에만 치중된 복잡한 Non-linear 형태가 되면 오버피팅이 발생하는 것이다.

따라서 오버피팅을 대처하는 대표적인 두 가지 방법에 대해 소개하겠다.
1. Regularization
먼저 L2 규제 방법은 손실함수(L(w))에 λ * L2 norm의 제곱을 더하는 것이다. (1/2n으로 나누는 것은 자유)
min L(w) + λ * g(w) // g(w)=||w||2
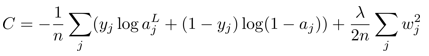
g(w)가 2차 함수 형태이므로 최종 Loss는 λ의 크기에 따라서 2차 함수에 가까워진다. 따라서 local optima에서 학습이 멈추는 현상이 줄어든다.
또한 이 방법은 경사하강법을 할 때 진가가 드러난다.
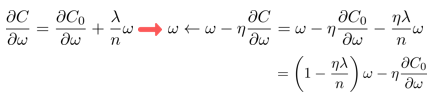
기존 gradient descent와의 차이점은, weight를 어느정도 줄인 다음에 -gradient방향으로 업데이트하겠다는 것이다. 이렇게 하면 모델의 일반화 성능이 높아진다. (=) 오버피팅이 줄어든다.
weight를 줄이는 것과 일반화 성능이 무슨 상관일까?
: weight가 너무 커지면 해당 weight랑 연결된 특정 노드가 결과에 많은 영향을 끼칠 수 있다. 예를 들어 고양이 분류 모델에서 특정 노드가 ‘고양이의 올라간 꼬리’에 대해 학습을 한다면, 이 노드로부터 결과가 나온다고 했을 때, 고양이의 꼬리가 내려간 이미지가 입력이 들어오면, 고양이가 아니라고 말할 수도 있다. 즉 일반화 성능이 낮아진다. 따라서 전체적으로 weight를 낮추고 업데이트를 하는 것이 일반화 측면에서 더욱 좋다!
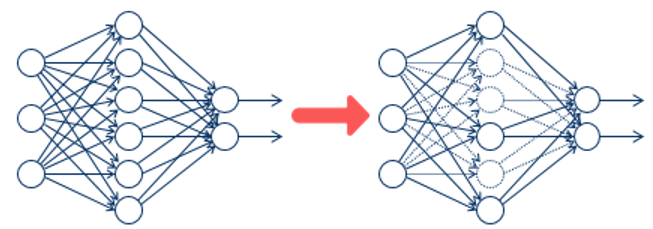
2. Dropout
Layer에서 랜덤하게 노드를 제거하는 것이다. (%만큼)
노드를 제거함으로써 L2 규제에서 weight를 줄이는 것과 비슷한 효과를 보인다!
머신러닝 vs 딥러닝
왜 적은 데이터일 때는 머신러닝을 사용하는 것이 좋을까?
: 딥러닝은 복잡한 모델을 지니기 때문에 적은 데이터가 입력으로 오든 많은 데이터가 입력으로 오든 데이터의 패턴(결정 경계 혹은 회귀 곡선)이 복잡하다. 그런데 데이터가 적은데 패턴이 복잡하면 오버피팅이 발생할 확률이 더 크다. 따라서 머신러닝을 쓰는 것이 더 좋다.