
※ Deep Learning From Scratch (밑바닥부터 시작하는 딥러닝)에 대한 정리 자료입니다.
NLP
Nature Language Processing의 약자로, 사람이 의사소통하는 언어를 컴퓨터가 알도록 하는 분야이다.
= Techniques =
1. Thesaurus (백과사전): 컴퓨터가 DB를 보고 언어의 의미를 파악한다.
– 장점: 유사한 단어들을 묶어서 저장하는 WordNet을 이용하면 번역 따위가 가능하다.
– 단점: 새롭게 나오는 단어들을 빠르게 반영하기 힘들다.
2. Corpus (말뭉치): 여러 가지 단어로 이루어진 문장을 알려주고, 어떤 단어의 앞 혹은 뒤에 무슨 단어가 오는지 통계적으로 파악한다.

ex) you랑 goodbye 사이에는 say가 통계적으로 많이 나온다.
3. Word2Vec: 단어에 매칭되는 벡터가 무엇인지 딥러닝으로 추론하는 방식이다.
지금부터 Corpus 방식에 대해 알아보겠다.
먼저 문장을 Vectorization해서 저장한다.
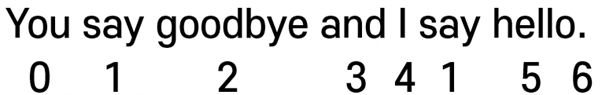
[0 1 2 3 4 1 5 6] 벡터를 Corpus라고 부른다.
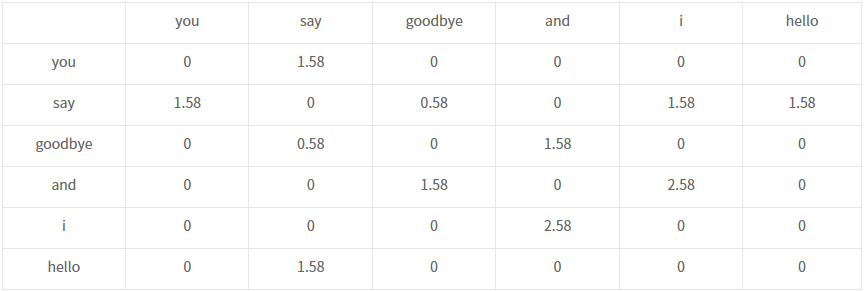
Corpus로 co-occurrence matrix(동시발생 행렬)를 구성해서 이용하게 된다.
(단어 앞,뒤에 어떤 단어가 올 수 있는지 확인할 수 있는 행렬, 특징: 대각선은 0(Aii=0), 대칭 행렬(Aij=Aji))
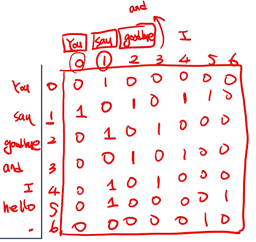
이렇게 co-occurence matrix를 이용하면, 각 단어를 벡터화시킬 수 있다.
예를 들어, You는 [0 1 0 0 0 0 0]이고 I는 [0 1 0 1 0 0 0]이다.
이 벡터들은 코사인 유사도를 통해 얼마나 비슷한지 확인이 가능하다.
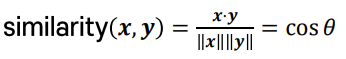
x 단어 벡터와 y 단어벡터가 이루는 각을 θ라고 할 때,
θ가 작을수록 두 벡터는 평행하므로 비슷하다.
그런데 θ가 작을수록 cos(θ)는 커지게 된다.
또한 내적 공식에 의해 cos(θ)는 x·y/||x||*||y||로 표현된다.
따라서 x·y/||x||*||y||가 클수록 두 단어(x,y)가 비슷하다.
You를 x, I를 y라고 한다면 Similarity는 1/1*√2가 되므로,
cos(θ)=1/√2를 만족하는 θ가 45도가 된다는 것이고, 이 값으로 추론해볼 때
두 단어는 그렇게 유사하지는 않다.
지금까지 소개한 내용을 코드로 확인하고 싶으면 다음 링크를 참조: [링크]
그러나 co-occurence matrix의 문제점이 존재한다.
예를 들어, the, car, drive를 비교하면 the와 car보다 car와 drive의 관련성이 훨씬 깊다. 하지만, the와 car의 동시 발생 횟수가 car와 drive의 동시 발생 회수보다 더 많다. 이는 the가 워낙 고빈도 단어이기 때문이다. 그럼 결국 동시 발생 행렬로 구한 “the”벡터와 “car”벡터의 코사인 유사도가 커지게 된다. 즉 서로 관련없는 단어의 유사도가 커지게 된 것이다.
따라서 나온 방식이 Pointwise Matmul Information(PMI)이다.

이는 x,y가 동시에 일어날 확률을 x가 일어날 확률과 y가 일어날 확률을 곱한 값으로 나눈 것이다.
예를 들어, 문장의 단어가 만 개 있다고 하겠다. (N=10,000)
‘the’와 ‘car’의 PMI와 ‘car’와 ‘drive’의 PMI는 아래와 같이 계산된다.
“the”=1000, “car”=20, “drive”=10
“the car”=10, “car drive”=5
PMI(“the”,”car”)=log2{(10/10000)/(1000/10000)*(20/10000)}=log25
PMI(“car”,”drive”)=log2{(5/10000)/(20/10000)*(10/10000)}=log2250
-> “car”는 “the”보다 “drive”와 훨씬 관련이 크다
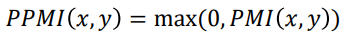
만약 log의 지수가 0이 오면 –무한대가 되므로 MAX(0,PMI)를 해서 PPMI(Positive PMI)를 반환한다.
따라서 PPMI 값들로 행렬을 구성하고, 행렬의 각 행을 단어 벡터로 사용하자는 것이 취지이다!
하지만 동시발생행렬이나 PPMI 행렬이나 단어의 개수에 따라 벡터의 차원 수가 너무 커질 수 있다.
따라서 SVD에서 일부 U(mxr)만을 이용해서 벡터를 표현할 수도 있지만, 결국 시간복잡도가 O(n3)이 되어 사용되기가 어렵다고한다.
따라서 현재는 딥러닝을 이용한 Word2Vec이라는 방법이 자주 사용된다.
Word2Vec의 학습 알고리즘 중 CBOW에 대해 알아보겠다.
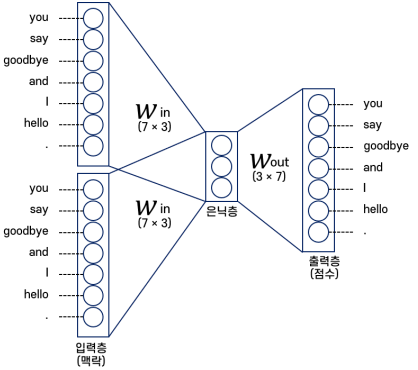
CBOW에서 단어 벡터는 Win을 사용한다.
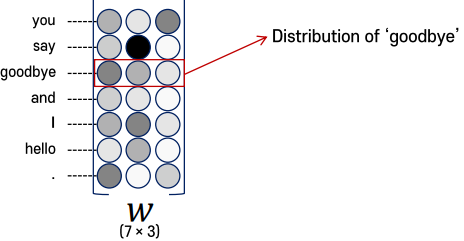
즉 은닉층에서 노드의 수가 벡터의 크기를 결정하는 것이다.
CBOW 모델은 두 단어 사이에 어떤 단어가 오는지 예측하는 방식으로 학습된다.
따라서 그림으로 나타내면 다음과 같다.
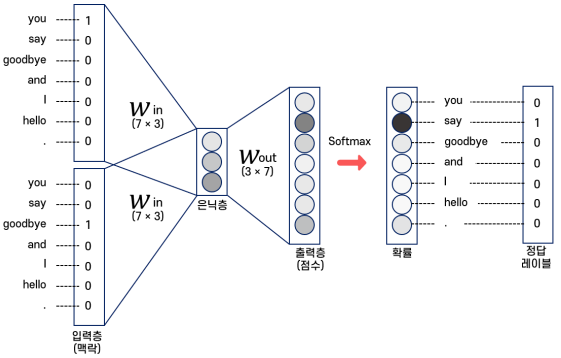
그래서 결국 CBOW는 맥락과 정답에 해당하는 원핫벡터를 모두 제작한 다음에야 이용할 수 있다.
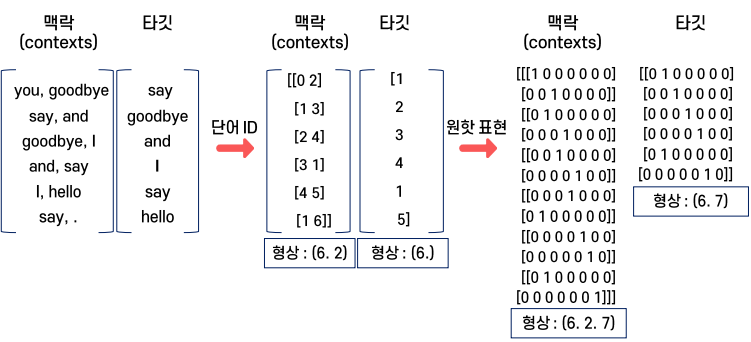
CBOW의 Forward 과정을 간략화하면 다음 코드와 같다.
# You say good bye and I hello . # You:0, goodbye:2 -> one-hot C0=np.arrray([1,0,0,0,0,0,0]) C1=np.array([0,1,0,0,0,0,0]) # weight W_in = np.random.randn(7,3) W_out = np.random.randn(3,7) # h0=C0*Win, h1=C1*Win (In layer) h0=np.dot(C0,Win) h1=np.dot(C1,Win) # h=0.5*(h0+h1) h=0.5*(h0+h1) s=np.dot(h,w_out) # C0(1,0,0,0,0,0,0) -> h0(h01,h02,h03) # C1(0,1,0,0,0,0,0) -> h1(h11,h12,h13) => h=(h0+h1)/2 -> output(0,0,1,0,0,0,0)
은닉층에서 입력 벡터가 두 개가 되므로, 두 벡터 원소를 각각 더하고 2로 나누는 방식으로 새로운 벡터를 만든다.
이 새로운 벡터를 이용해서 출력층의 벡터를 형성하는 것이다.
학습이 완료되면, Win의 각 행을 단어벡터로 사용한다.