
※ Deep Learning From Scratch (밑바닥부터 시작하는 딥러닝)에 대한 정리 자료입니다.
Optimizer는 딥러닝에서의 최적화 기법이다.
딥러닝에서 최적화란 손실함수(E(W,b)를 최소로 만드는 Weight와 bias를 찾는 과정이다.
함수를 가장 빠르게 감소시키는 방향인 -Gradient 방향으로 Weight와 bias를 업데이트하는 것이 일반적이다.
(wn+1,bn+1) = (wn,bn) – n * ▽L(wn,bn)
이러한 방식을 Gradient Descent라고 하며, 최적화에서 가장 기초적인 방법이다.
SGD
그러나 딥러닝의 모델 입력에는 배치 사이즈만큼 들어가므로,
배치 단위로 Gradient Descent를 하게 된다.
즉 일부 데이터만을 이용해서 Gradient를 구하고 평균지어서 모델을 업데이트하는 방식이다.
이것을 SGD(Stochastic Gradient Descent)라고 부른다.
class SGD:
"""확률적 경사 하강법(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
Gradient는 Loss Function 등고선에서 수직인 방향이기 때문에,
Weight가 전역최적점을 찾아가는 과정은 아래와 같이 그려진다.
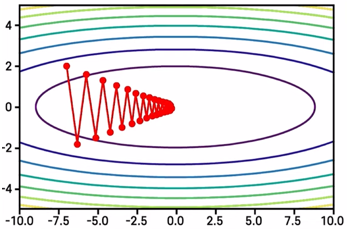
그러나 SGD에는 단점이 존재한다.
손실함수가 무엇이냐에 따라, 함수의 시작점이 무엇이냐에 따라 Gradient가 너무 가파를 수 있고 결국 학습이 느리게 되는 문제가 발생한다.
Momentum
Momentum은 SGD가 학습이 느린 단점에 의해 만들어진 최적화 방식이다.
W = W – lr * ∂L/∂W 이었던 SGD식이
W = W + v
v = av – lr * ∂L/∂W로 변경된다.
위 수식에서 a를 momentum이라고 하며, 결국 W를 구할 때 av항까지 더하면서 더 빠르게 학습이 가능하다.
class Momentum:
"""모멘텀 SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
이 방식을 이용한 최적화를 그림으로 그리면 다음과 같다.
SGD보다 전역최적점을 더 빠르게 찾는 것을 확인할 수 있다.

그러나 Momentum에도 단점이 존재한다.
learning rate가 무엇이냐에 따라 SGD보다 더 안 좋은 결과를 초래할 수 있다.
AdaGrad
학습을 할 때는 learning rate가 굉장히 중요한데, Adaptive Sense로 learning rate를 줄여나가겠다는 아이디어가 AdaGrad이다.
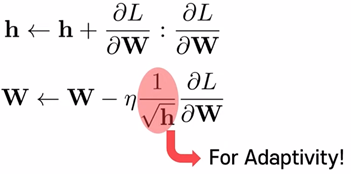
Adaptive Sense는 1/√h에 해당한다.
따라서 learning rate는 n * 1/√h로 대체된다.
h에는 gradient의 크기가 저장되는데, (h의 초기값은 0)
n * 1/√h는 h가 크면 값이 작아지고, h가 작아지면 값이 커지는 효과가 있다.
따라서 Gradient의 크기가 너무 크면 lr을 줄이고, 크기가 너무 작으면 lr를 높이는 방식이다.
gradient의 크기를 구할 때는 Frobenius Norm(:)을 사용한다.
이는 L2 norm을 matrix로 확장시켰다고 생각하면 된다.
Frobenius Norm (:)
A=[1,2; 3,4]일 때 A:A는 ||A||F=(1+22+32+42)`1/2
-> 모든 성분의 제곱의 합에 루트를 씌운 것
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
AdaGrad의 그림은 다음과 같다.
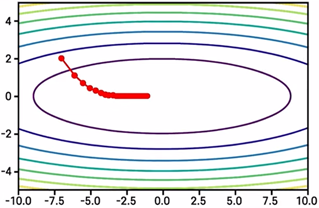
그러나 AdaGrad에도 단점이 존재한다.
학습 중 h가 너무 커지면, lr가 0과 가까워지면서 학습이 더 이상 진행되지 않을 수 있다.
RMSProp
RMSProp은 Gradient의 크기가 엄청 크면 lr이 0이 되서 학습이 안 되는 문제를 해결하기 위해 제안되었다.
여기서는 현재 구한 Gradient의 크기와 이전에 구한 Gradient의 크기(h)를 convex combination으로 세팅하였다.
이렇게 하면 현재 Gradient의 크기만 고려하지 않으므로 AdaGrad의 단점을 해결할 수 있다고 한다.
convex combination
λ와 1-λ를 각 항에 곱해서 더하는 형태
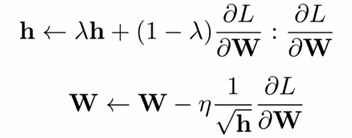
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
하지만 λ는 Hyper Parameter이므로 기존 방법에 비해 더 신경써야 된다는 문제점이 있다.
Adam
Adam은 현재 딥러닝에서 가장 많이는 최적화 방법이다.
이것은 Momentum과 RMSProp을 합친 Optimizer라고 생각하면 된다.

class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)