
앙상블 기법은 동일하거나 서로 다른 학습 알고리즘을 사용해서 여러 모델을 생성하는 개념 입니다.
여러 모델을 이용하면, 한 가지 모델을 이용하는 것보다 성능이 향상될 것이라는 생각으로 생겨 났습니다!
앙상블에는 배깅과 부스팅이 있는데, 배깅 먼저 알아 보겠습니다.
배깅은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 생성하고 결과물을 집계(Aggregration)하는 방법입니다.
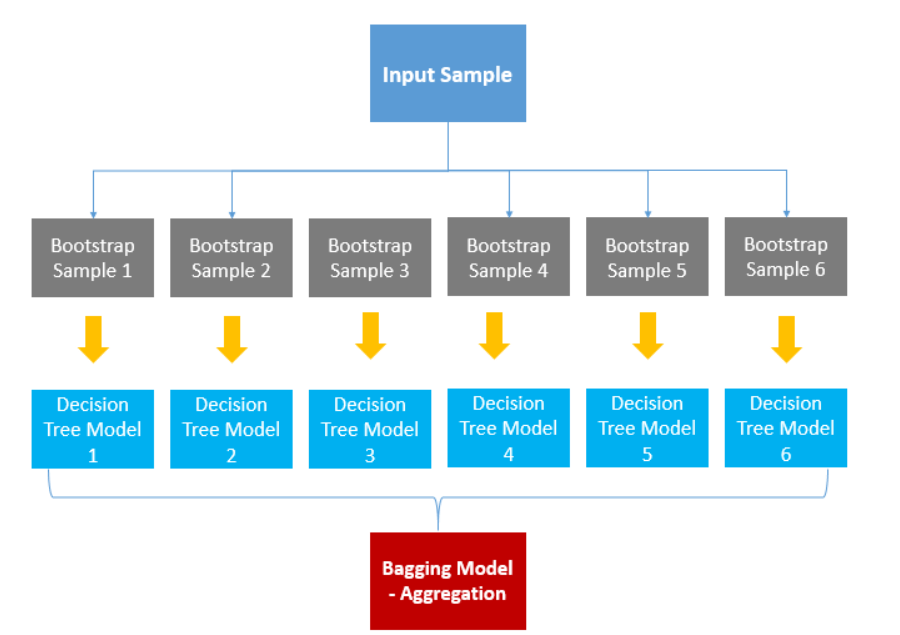
샘플을 여러 번 뽑을 때는 무작위 복원 추출(랜덤 추출)을 이용합니다.
데이터 세트 중 무작위로 70%를 sample1, 다시 데이터 세트 중 70%를 sample2,… 이런 식으로 샘플을 뽑습니다.
(복원 추출: 한 번 추출되도 다음에 추출 가능)
집계는 Voting(투표)를 이용해서 진행합니다.
10개의 결정 트리 모델이 있다고 합시다. 7개는 A로 예측했고, 3개는 B로 예측했다면 투표에 의해 7개의 모델이 선택한 A를 최종 결과로 예측한다는 것입니다.
배깅의 R 예시는 아래와 같습니다.
library(ipred) mybag<-bagging(default~.,data=train,nbagg=25) credit_pred<-predict(mybag,train) table(credit_pred,train$default)

배깅의 대표적인 알고리즘으로는 ‘랜덤 포레스트’가 있습니다!
앞에서 설명한 배깅과 랜덤 포레스트의 차이가 한 가지 있다면, 각 샘플이 만든 모델마다 다른 변수를 사용한다는 점입니다.
예를 들어 배깅은 (나이,성별,수입,거주지)변수를 각 샘플이 모두 가지고 있습니다.
그러나 랜덤 포레스트는 A샘플은 (나이,성별,수입)만 쓰고 B샘플은 (성별,수입,거주지)등을 쓰는 방식으로 샘플마다 아예 다른 데이터를 가집니다.
결국 랜덤 포레스트는 각 모델마다 다른 변수를 사용하기 때문에 앙상블 효과가 더 잘 나타난다고 합니다!
랜덤 포레스트의 R 예시는 아래와 같습니다.
libray(randomForest)
rf<-randomForest(default~.,data=credit)
rf
# 다른 방법
library(caret)
ctrl<-trainConctrol(method="repeatedcv",
number=10,repeats=10)
# 변수 수 설정
grid_rf<-expand.grid(.mtry=c(2,4,8,16))
m_rf<-train(default~.,data=credit,method="rf",
metric="Kappa",trConctrol=ctrl,
tuneGrid=grid_rf)
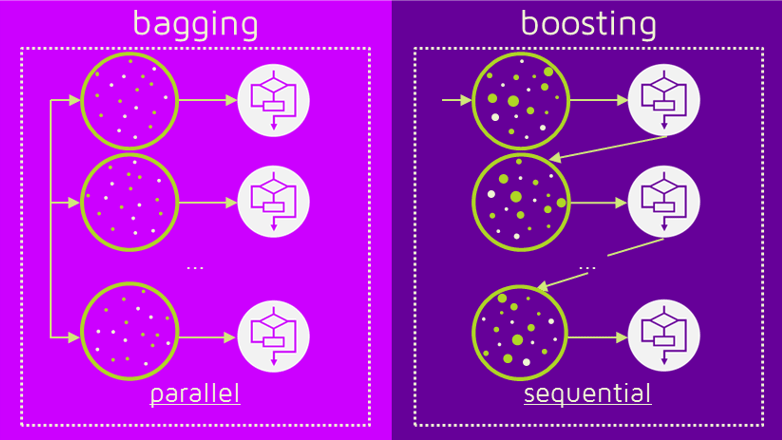
배깅은 sample1과 sample2가 서로 독립적으로 결과를 예측합니다. 여러 개의 독립적인 결정 트리가 각각 값을 예측한 뒤, 그 결과 값을 집계해 최종 결과 값을 예측하는 방식입니다.
즉 배깅은 병렬로 학습합니다.
그러나 앞으로 설명할 부스팅은 순차적으로 학습하는 차이를 보입니다.
부스팅은 순차적으로 학습을 하면서 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델을 만들 때 영향을 줍니다. 그리고 다음 모델이 만들어지면 가중치는 재분배됩니다.
이 가중치는 오답에 대해 높은 수치를 보이고, 정답에 대해 낮은 수치를 보입니다.
아래는 부스팅의 방식과 효과입니다.
처음에 학습을 해서 데이터에 가중치가 분배되면, 다음에 학습할 때는 가중치가 높은(오답인) 데이터를 먼저 처리해서 모델을 만듭니다.
즉 순차적으로 학습을 할 때마다, 가중치 높은(오답인) 데이터를 먼저 처리하다보니 오류가 점점 줄어들고 결국 정확도가 높은 모델이 완성됩니다.
부스팅의 R 예시는 아래와 같습니다.
# 순차적 반복 학습을 100번해서 오류를 줄여 나가겠다! m_c50_bst<-C5.0(default~.,data=train,trials=100)
지금까지 데이터 마이닝의 ‘모델 성능 향상’을 알아 보았습니다.