
이번 포스트는 모델의 성능을 평가하는 여러 가지 방법을 소개합니다.
1) 혼돈행렬
: 알고리즘이 얼마나 맞았나 틀렸는지를 평가하는 행렬
(머신러닝 관점)알고리즘대로 학습된 모델에 데이터를 넣었을 때, 결과가 실제와 비교해서이 얼마나 맞았나 틀렸는지를 평가하는 행렬
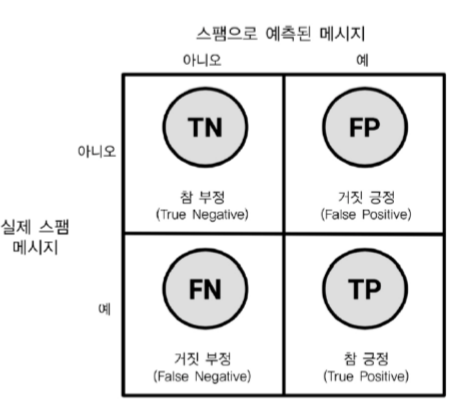
정확도: (전체에서 얼마나 맞췄는가) TN + TP / TN +FP + FN + TP
정밀도: (예측한 Positive 중 실제 Positive) TP / FP + TP
재현율: (실제 Positive 중 예측한 Positive) TP/ FN+TP
거짓 긍정율: (실제 Negative인데 예측하기는 Positive) FP / TN + FP
거짓 부정율: (실제 Positive인데 예측하기는 Negative) FN / FN + TP
True Positive rate: (실제 Positive 중 예측한 Positive) TP/ FN+TP <재현율>
False Positive rate: (True Positive rate의 분자만 수정) FP/ FN + TP
2) 카파 통계량
: ‘우연히 맞춘 것보다 얼마나 잘 맞추는가’ 를 나타낸 값
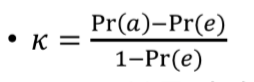
Pr(a): 분류기가 실제 일치하게 맞추는 비율
Pr(e): 무작위로 했는데 우연히 실제 값과 같은 비율
K: 카파 통계량
우연히 찍어서 맞출 확률을 배제하고 알고리즘을 평가해야 공평한 평가입니다.
고로 분모에서 Pr(a)에서 Pr(e)를 빼고, 분자도 1에서 Pr(e)를 뺍니다.
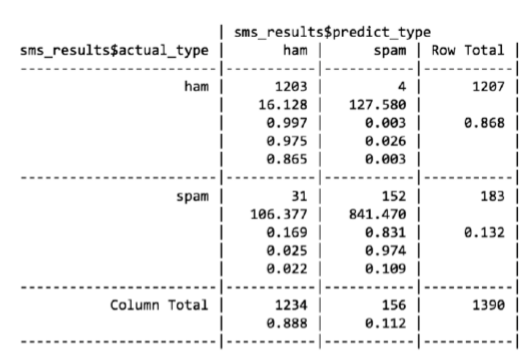
Pr(a) = (ham으로 예측한게 맞은 비율) 0.865 + (spam으로 예측한게 맞은 비율) 0.109
Pr(e) = (실제 햄 * 햄으로 예측) 0.868 * 0.888 + (실제 스팸 * 스팸으로 예측) 0.132 * 0.112
K = Pr(a) – Pr(e) / 1- Pr(e)
rslt<-table(sms_results$actual_type,sms_results$predict_type) # 혼돈행렬 생성 pr_a<-sum(diag(rslt))/sum(rslt) # 모델의 accuracy # diag는 대각선 값 pr_e<-sum(colSums(rslt)*rowSums(rslt)/sum(rslt)^2) # 모델이 랜덤으로 찍었을 때 맞출 확률 kappa<-(pr_a-pr_e)/(1-pr_e)
3) F-척도
: 모델의 성능을 구할 때, (정밀도와 재현율)을 하나의 값으로 해서 평가할 때 사용

위 (나이브 베이즈 예시)에서 스팸을 Positive라고 할 때, F-척도를 구해 보겠습니다.
정밀도: 152(TP) / 152(TP) + 4(FP) = 0.97
재현율: 152(TP) / 152(TP) + 31(FN) = 0.83
F-척도: 2 * 0.97 * 0.83 / 0.83 + 0.97 = 0.89
4) 민감도와 특이도
: 민감도 – Positive를 얼마나 잘 맞추는지 (True Positive rate)
특이도 – Negative를 얼마나 잘 맞추는지 (True Negative rate)
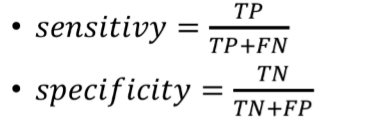
민감도 (sensitivity) : TP / TP+FP
특이도 (specificity) : TN / FP+TN
Positive는 보통 맞추려는(관심있는) 문제입니다.
고로 민감도는 관심있는 문제를 얼마나 잘 맞추는지, 특이도는 관심없는 문제를 얼마나 잘 맞추는지라고 합니다.
library(caret) sensitivity(sms_results$predict_type,sms_results$actual_type,positive="spam") specificity(sms_results$predict_type,sms_results$actual_type,negative="ham")
민감도와 특이도는 트레이드 오프 관계에 있습니다.
(트레이드 오프: 두 목표 가운데 하나를 달성하려고 하면 다른 목표 하나를포기하거나 달성 시기를 늦추는 경우를 뜻합니다.)
5) Roc Curve
: 거짓 긍정을 피하면서 참 긍정을 탐지하는 것 사이의 트레이드 오프를 관찰하기 위한 그래프
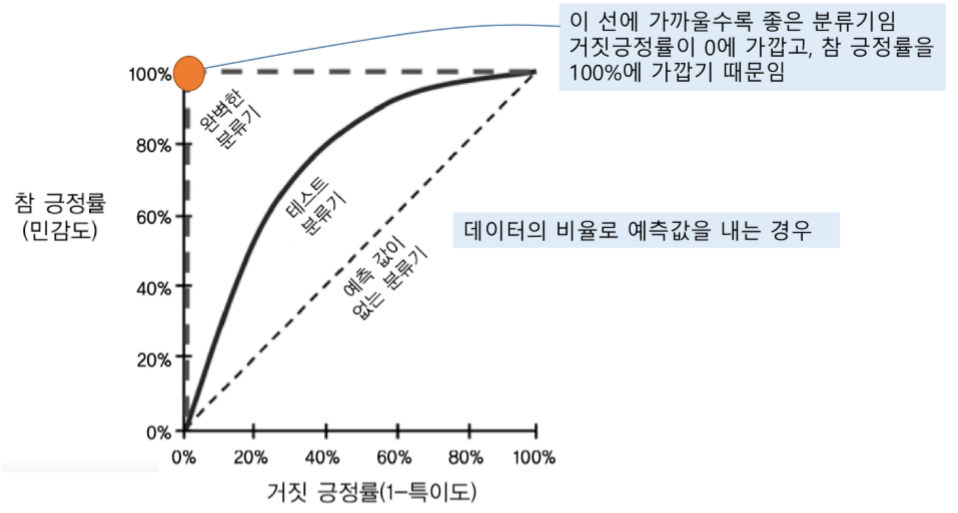
학습 없이 (하나로)찍은 모델의 성능: 예측값이 없는 분류기 – 맞추는게 40%면 틀리는 것도 40%
학습 한 뒤 완벽해진 모델의 성능: 오렌지 색 분류기 – 맞추는게 100%
x축은 0에 가까우면 y축은 1(100%)에 가까우면 좋습니다!
AUC – 테스트 분류기의 아래 부분 면적을 의미합니다.
If) 테스트 분류기 = 예측 값이 없는 분류기
=> AUC는 0.5
If) 테스트 분류기 = 완벽한 분류기
=> AUC는 1
나이브 베이즈 모델로 ROC Curve 보기)
library(ROCR)
# 나이브 베이즈 모델에 시험 데이터 넣기
sms_test_prob<-predict(m,sms_dtm_test,type="raw")
# prediction함수를 통해서 spam을 positive로 해서 TP과 FP 구하기
pred<-prediction(predictions = sms_test_prob[,2],
labels=sms_raw_test$type)
# performance함수를 통해서 다양한 metric관점으로 모델 평가 가능
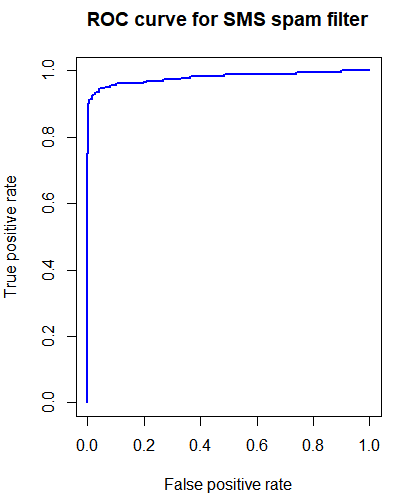
perf<-performance(pred,measure="tpr",x.measure="fpr")
# perf로 ROC Curve보기
plot(perf,main="ROC curve for SMS spam filter",col="blue",lwd=2)
# auc값 계산
perf.auc<-performance(pred,measure='auc')
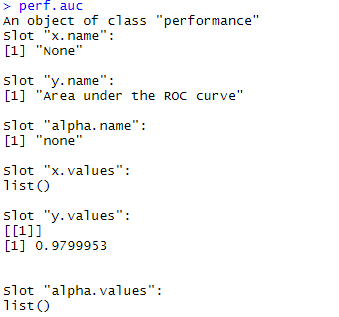
auc 면적의 값은 0.97로 전체의 97%를 의미합니다.
6) 학습 방법
overfitting은 학습 데이터에 대해 과하게 학습하여 실제 데이터에 대한 오차가 증가하는 현상입니다.
예를 들어, 갈색 강아지를 보며 강아지의 특성을 학습한 사람이 검은색이나 흰색 강아지를 보고는 그것을 강아지라고 인식하지 못 하는 현상이 overfitting과 유사한 경우입니다.
즉 우리는 모델을 만들고 이것이 과대적합인지 적정적합인지 가늠해야 됩니다.
그러나 가지고 있던 데이터 세트를 모두 넣어서 모델을 훈련시키면 가늠할 수가 없습니다.
데이터를 이용해서 판단을 하는데 모든 데이터가 이미 사용됐기 때문이죠!
이러한 과적합도 막고, 모델 평가도 가능하게 하는 방법 2가지가 있습니다.
1- Hold-out 방법
데이터 세트를 train, validation, test로 나눕니다.
(train은 50~60%, validation은 20~30%, test도 20~30%)
train 세트를 가지고 모델을 훈련 시킵니다.
validation 세트를 가지고 모델이 과적합인지 훈련을 더해야 되는지 검증합니다.
test 세트를 가지고 모델을 평가합니다.
아래는 credit데이터 세트를 train, validation, test데이터로 나누는 2가지 방법입니다.
# order함수: 오름차순하기 위한 요소들의 번호 나열 # 0.7 0.9 0.5 # -> 3 1 2 random_ids<-order(runif(1000)) # runif는 0~1 사이의 난수를 만듦 credit_train<-credit[random_ids[1:500],] credit_validate<-credit[random_ids[501:750],] credit_test<-credit[random_ids[751:1000],] # 데이터의 비율에 맞춰서 75%를 뽑아냄 # validation은 따로 있음 <주로 교차 검증 방법으로 쓰임> in_train<_createDataPartition(credit$default,p=0.75,list=FALSE) credit_train<-credit[in_train,] credit_test<-ctrdit[-in_train,]
2- 교차 검증
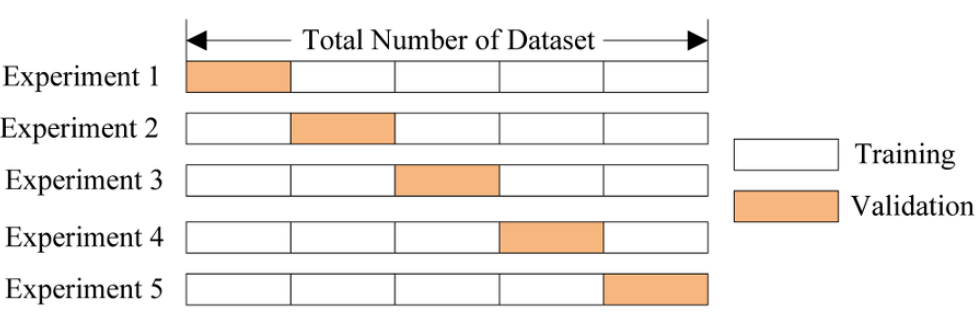
훈련 데이터를 k조각으로 쪼개고 k-1조각은 모델을 훈련하는데 사용합니다.
나머지 한 조각은 validation으로 만들어서 만들어진 모델을 검증합니다.
이렇게 검증을 1회 하고 나면 다음에는 다른 조각을 validation으로 만들고 나머지 조각들로 모델을 훈련합니다.
이 과정을 k번 반복합니다.
만들어진 k개의 모델에서 최적의 오류를 기반으로 최적 모델을 찾습니다.
이후 최적 모델을 바탕으로 전체 training set의 학습을 진행합니다.
학습이 끝나면 test데이터로 학습 모델을 평가합니다.
교차 검증은 조각을 어떻게 나누느냐에 따라서 오차가 다르게 발생합니다.
그렇기 때문에 교차 검증을 repeats번 반복 후 평균을 이용한 방법이 많이 쓰입니다.
지금까지 데이터 마이닝의 ‘모델 성능 평가’를 알아 보았습니다.