
빅데이터란 기존 데이터베이스 관리도구로 데이터를 수집, 저장, 관리할 수 있는 역량을 넘어서는 정형 혹은 비정형 데이터를 저장하고 이로부터 가치를 추출 및 결과를 분석하는 기술을 의미한다.
(기존 데이터베이스 시스템에 저장할 수 있는 역량을 넘어서는 데이터를 저장, 관리, 분석하는 기술)
5V: Volume(양), Variety(다양성), Velocity(데이터 생성 속도), Value(가치), Veracity(진실성)
Hadoop
Hadoop: 빅데이터 분산 처리 및 데이터 관리 플랫폼 (HDFS + MapReduce)
HDFS: Hadoop Distributed File System: 대용량 데이터를 분산된 서버에 저장하도록 설계된 파일 시스템
MapReduce: 분산 처리를 위한 프레임워크 (HDFS에 나눠 저장된 파일을 분산처리하기 위한 모델)
HDFS에서 파일을 WRITE하는 과정
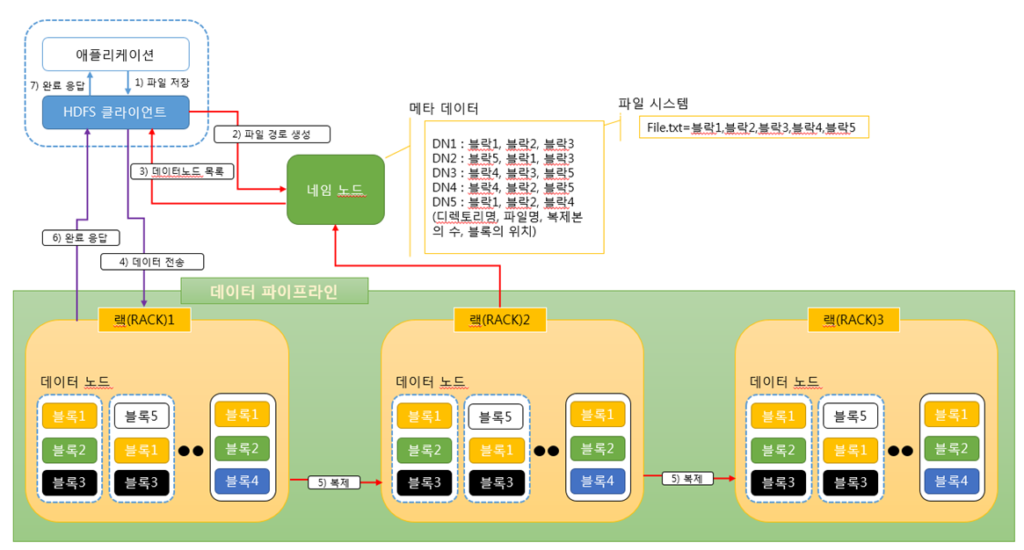
1. 애플리케이션은 HDFS 클라이언트를 통해 파일을 저장한다.
2. HDFS 클라이언트는 네임 노드를 통해 파일 경로를 생성한다.
3. 네임 노드는 데이터 노드 목록을 반환한다.
4. HDFS 클라이언트는 랙에 데이터를 전송한다.
5. 랙은 주변 랙에 데이터를 복제한다.
6. 랙은 HDFS 클라이언트에게 완료 응답을 보낸다.
7. HDFS 클라이언트는 애플리케이션으로 완료 응답을 보낸다.
HDFS에서 파일을 READ하는 과정

1. 애플리케이션이 HDFS 클라이언트를 통해 파일을 조회한다.
2. HDFS 클라이언트는 네임 노드를 통해 블록 위치를 조회한다.
3. 네임 노드는 데이터 노드 목록을 반환한다.
4. HDFS 클라이언트는 랙에 블록을 요청한다.
5. 랙은 HDFS 클라이언트로 데이터를 전송한다.
6. HDFS 클라이언트는 애플리케이션으로 데이터를 전송한다.
MapReduce에서 데이터를 처리하는 과정
Map: 흩어져 있는 데이터를 Key, Value 형태로 연관성있는 데이터로 분류함
Reduce: Map에서 출력된 데이터 중에서 중복 데이터를 제거하고 원하는 데이터를 추출함

Input -> Splitting -> Mapping -> Shuffling -> Reducing -> Final Result
Apache Spark
Apache Spark: 대용량 데이터 처리 및 분석을 위한 분산 클러스터링 연산 프레임워크
1. 성능: 인메모리 기반의 Map&Reduce를 통해 하둡의 MR보다 빠른 성능 구현
2. 다수의 언어 인터페이스 지원
3. 범용성 (여러 어플리케이션에서 적용 가능)
4. 데이터 활용성 (HDFS 등 다양한 데이터 소스에 사용 가능)
5. 클러스터링 리소스 관리
데이터 스토리지를 미포함하나 하둡의 HDFS를 사용 가능하다.
RDD(Resilient Distributed Dataset): Spark의 핵심 자료구조
1) In-Memory 데이터 처리: 디스크 기반보다 매우 빠른 속도, 그러나 fault 복구 문제
2) Fault-tolerant: Update를 없애고 메모리에 read-only만 함 (immutable), Lineage(계보)를 두어 RDD에 적용된 순서를 저장 -> 복구에 용이
3) Lazy-execution: 데이터를 생성할 때만 Lineage를 통해 최적 수행
4) Partitioned: 데이터를 파티션으로 나누어 클러스터 노드에 분산 처리함
5) Job Scheduling: Lineage를 바탕으로 데이터의 배치와 파티션 분배를 미리 계산
Spark SQL Query Execution flow
SQL이 주어졌을 때, DataFrame 형태의 데이터를 Catalyst optimizer를 거쳐서 최적의 plan을 만든 후, RDD 연산이 수행되도록 Java bytecode 생성
NoSQL
Web으로 인해 폭발적으로 많은 데이터가 생성되었다. 이전에 존재하지 않았던 블로그 데이터 등과 같은 비정형 데이터가 생산되었고 이러한 데이터를 저장하기 위한 수단이 필요했다.
Not Only SQL
: 기존 관계형 DBMS가 갖고 잇는 특성 뿐만 아니라 다른 특성들도 부가적으로 지원, Key-Value pair로 데이터를 저장
특징: No Schema, Join 지원 x, 클러스터링 기법 사용, ACID 보장 x, 쿼리 언어 지원 X

NoSQL – Redis
Redis: 인메모리 Key-Value 데이터베이스
– 특징: 다양한 데이터 타입 지원, 싱글 스레드 기반, 해시 구조로 구성됨, 클러스터링을 통해 scalable하게 구성 가능
– 장점: 인메모리 데이터베이스이므로 처리 속도가 빠르다, 메신저 서비스에서 활용하기 좋다, 대부분의 프로그래밍 언어에서 사용 가능하다
– 단점: 메모리 사이즈보다 큰 데이터 셋을 저장할 수 없다, 인메모리 데이터베이스이므로 데이터 지속성을 유지하는데 비용이 많이 소모된다 (디스크에 로그 작성함), 복잡한 데이터를 운용하기에는 적합하지 않다 (로그 작성 시 속도에 영향을 주므로)
Redis는 인메모리 데이터베이스이므로 서버가 비정상적으로 종료되면 데이터가 날아갈 위험이 있다. 그래서 별도의 Log을 디스크에 저장함으로써 데이터 지속성을 유지한다.
RDB(Redis Database): Redis에 저장된 데이터들을 Binary Dump 형식 Log로 저장하는 방식
AOF(Append Only File): Redis에서 수행된 커맨드들을 Log로 저장하는 방식
Redis는 분산 시스템을 구성하기 위해 클러스터링을 제공함
장점: Load Balancing (여러 Redis node에 데이터를 분산하여 저장), Fault Tolerance (데이터 처리 중에 Redis node가 failure가 발생하여 비정상적으로 종료되더라도 계속 처리 가능)
Memcached와의 비교
Memcached는 데이터 타입이 String이며 Persistency를 지원하지 않는다. Redis는 트래픽이 몰리는 경우 성능이 감소하지만 Memcached는 성능을 안정적으로 유지한다. 만일 데이터가 자주 변하지 않고 원본 데이터가 다른 곳에 저장되었다면 Memcached를 사용하는 것이 좋다고 한다.
NoSQL – RocksDB
RocksDB: SSD 저장 장치 기반 서버에 최적화된 Key-Value 저장소
– 특징: Log-Structured Merge-Tree (LSM Tree) 구조 사용, 멀티 스레드 기반, Read 성능 개선을 위해 BloomFilter 사용, Transaction 지원, SQL 지원 X,

Memtable: 인 메모리 데이터 구조, 데이터가 기록될 때 최초로 저장되는 공간, Memtable에 데이터가 일정 용량까지 기록되면 변경이 불가능한 Immutable Memtable로 변경, 변경되면 SSTable로 변경되어 Disk로 Flush됨
SSTable: Immutable Memtable의 데이터를 Key순으로 정렬하여 저장한 파일, 디스크 영역의 레벨에 상주함
LSM Tree의 세 가지 Compaction: Leveled Compaction, Universal Compaction, FIFO Compaction
RocksDB의 Leveled Compaction 과정

1. 상위 레벨의 크기가 임계점을 넘게 되면 하위 레벨로 내려줄 SST 파일을 선택한다
2. 하위 레벨의 SST파일 중 선택된 상위 레벨의 SST파일의 Key 범위가 겹치는 파일들을 선택하여 병합 정렬을 진행한다.
3. 병합 정렬을 통해 생성되는 SST 파일들을 하위 레벨에 기록한다.
4. 선택되었던 상위 레벨의 SST 파일은 삭제한다.
BloomFilter
원소가 집합에 속하는지 여부를 검사하는데 사용되는 자료구조,
긍정 오류(FP)는 발생하지만 부정 오류(FN)은 절대 발생하지 않는 특징이 있음
BloomFilter를 통한 조회
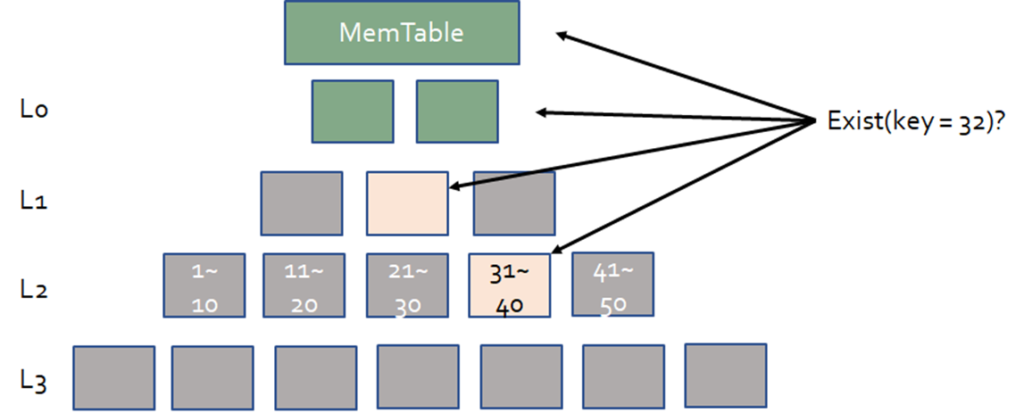
1. Get 명령어가 요청된 경우 찾고자 하는 Key가 Memtable에 있는지 조회함
2. Memtable에 없는 경우 L0에 있는 SST파일을 조회함
3. L1부터는 BloomFilter의 값이 true인 SST파일만 읽음, 조회한 파일 중 원하는 Key가 있으면 해당 Key-Value pair를 반환함, 없으면 하위 레벨로 이동하여 이 과정을 반복함
-> BloomFilter를 사용하면 읽어야 할 SST 파일 수를 줄여 Read 성능을 개선할 수 있음
LevelDB와의 비교
LevelDB는 코드 복잡도가 RocksDB보다 단순하며 싱글 스레드 기반이다. 그러나 읽기 및 쓰기 속도가 느리고 트랜잭션을 지원하지 않는다. 생성되는 DB 크기도 더 작다.