
오토인코더는 입력과 동일한 출력을 만드는 것을 목적으로 하는 신경망입니다.
그러기 위해 입력 데이터를 더 낮은 차원으로 인코딩하고 다시 원래의 데이터로 디코딩합니다.
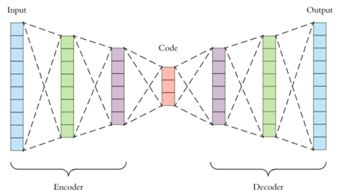
인코더는 ‘입력 데이터’를 ‘잠재변수’로 만드는 역할을 합니다.
입력 데이터를 더 낮은 차원으로 변형시키면서 특징을 추출한다고 생각하면 됩니다.
더 낮은 차원으로 변형될수록 중요한 특징들만 선별되는 방식입니다.
잠재변수는 입력 데이터를 압축한 결과입니다.
입력 데이터를 이루는 중요한 특징들이 이 변수 안에 있다고 생각하면 됩니다.
디코더는 ‘잠재변수’를 해석해서 나온 데이터를 출력하는 역할을 합니다.
오토인코더 이용
1. 압축된 특징 학습
예를 들어 ‘개와 고양이 분류 문제’가 있다고 가정하겠습니다.
입력 데이터는 ‘동물의 길이’, ‘동물의 몸무게’, ‘주인의 키’, ‘주인의 성별’이 들어간다고 하겠습니다.
그렇다면 잠재변수는 어떤 형태가 될까요?
입력 데이터가 압축되면서 ‘주인의 키’와 ‘주인의 성별’이 사라진 형태가 됩니다.
즉 필요 없는 잉여 특징(redundant feature)이 제거됩니다.
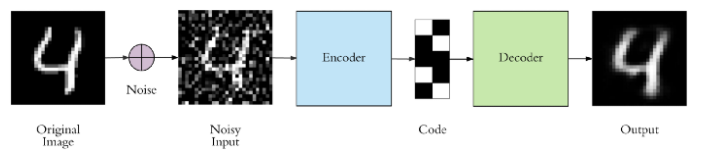
2. Denoising
Denoising은 ‘노이즈가 있는 데이터’에서 노이즈를 제거하는 것입니다.
Denoising Autoencoder는 ‘더러운 데이터’ 즉, 노이즈가 첨가된 데이터가 들어왔을 경우를 대비해서 모델이 스스로 잘 복구시키도록 일부러 원본 이미지에 노이즈를 첨가한 후 모델을 학습시키는 방식입니다.
Gaussian 분포에서 샘플링하는 노이즈는 학습할 때마다 노이즈 데이터가 바뀔 것이고 이렇게 계속적인 학습이 이루어진다면 모델은 다양한 노이즈가 첨가된 데이터들을 학습시키게 됩니다. 결국 어떤 노이즈가 포함된 데이터가 와도 강인한 효과를 보일 수 있습니다. (모델의 Regularization(일반화))
3. 전이학습 (Transfer Learning)
A라는 목적을 위해 학습된 파라미터를 B라는 다른 목적을 위해 사용하는 것을 ‘전이학습’이라고 합니다.
예를 들어 고양이 분류를 위해 학습된 모델의 파라미터를 호랑이 분류 모델에 적용한다면
loss값이 낮은 상태에서 학습을 진행할 수 있습니다. (특징이 비슷하기 때문에 학습을 조금만 더 하면 호랑이 특징을 찾을 수 있음)
오토인코더 기준으로 생각하면,
디코더 부분을 삭제하고 인코더의 출력(잠재 변수)을 분류기의 입력으로 사용하는 모델을 생각할 수 있습니다.
(데이터 재구축)을 위해 학습된 파라미터를 (분류)라는 다른 목적을 위해 사용하는 것입니다.
기존 방식(분류기에 이미지 벡터를 입력으로 넣음)과 비교한다면
이미지의 좋은 특징만 추출해서 분류에 이용하는 것이므로 성능이 더 좋을 수밖에 없습니다.

아래는 전이학습 과정입니다.

4. 비정상적인 데이터 검색
정상 데이터로 학습된 오토 인코더가 있다고 가정하겠습니다.
이후 다른 정상 데이터를 입력으로 준다면 출력이 비슷하게 나올 것입니다.
하지만 비정상 데이터를 입력으로 준다면 출력이 매우 다르게 나올 것입니다.
학습된 파라미터가 정상 데이터를 기준으로 처리하기 때문입니다.
따라서 결과 데이터와 입력 데이터의 차이가 threshold를 초과하면 비정상으로 분류하는 프로그램도 만들 수 있습니다.
Good Reconstruction

숫자 이미지가 기록된 mnist데이터입니다.
위 이미지를 입력으로 준다면 좋은 reconstiction결과를 확인할 수 있습니다.
왜냐하면 압축할 때 검은 색 배경은 사용하지 않고 흰 색 글자의 특징을 찾으려고 하는데,
마침 픽셀들이 중앙에 잘 배치돼서 특징 파악이 편한 것입니다.
결국 Good Reconstruction을 위해서는 Good Data가 필요하다는 의미입니다.
감사합니다.