
문자열 포함 관련 함수
# forbidden에 해당하는 문자를 포함하지 않았는가
# word가 letter(forbidden의 문자)를 하나라도 포함하면 False
def avoids(word,forbidden):
for letter in forbidden:
if letter in word:
return False
return True
avoids('sh','shit') # False
# available에 해당하는 문자만 포함하는가
# available이 letter(word의 문자)를 하나라도 포함 안 하면 False
def uses_only(word,available):
for letter in word:
if letter not in available:
return False
return True
uses_only('hi','hi_hello') # True
# required에 해당하는 문자열을 모두 포함하는가
# word가 letter(required의 문자)를 하나라도 포함 안 하면 False
def uses_all(word,required):
for letter in required:
if letter not in word:
return False
return True
uses_all('hi_hello','hello') # True
enumerate 함수
(인덱스,값)조합으로 튜플을 만들고 이러한 튜플들을 저장하는 zip을 만듦
for index,element in enumerate('abc'):
print(index,element)

중복된 원소가 있는지 찾기
def has_duplicates_set(t):
s=set(t)
if(len(s)<len(t)):
return True
else:
return False
has_duplicates_set([1,2,3,1])
def has_duplicates_dict(t):
d=dict()
for i in t:
d[i]=d.get(i,0)+1
if(len(d)<len(t)):
return True
else:
return False
has_duplicates_dict([1,2,3,1])
n명의 사람들 중 적어도 두 사람의 생일이 같을 확률
import random
iteration=1000
n=23
freq=0
# iteration번 시행
for itr in range(iteration):
birth=set()
# 생일 추가 - 생일 검색
for i in range(n):
new=random.randint(1,365)
# (새로운 생일이 온건지 검사), 같은 것이 있으면 다음 시행 진행
if(new in birth):
freq+=1
break
birth.add(new)
print(freq/iteration)
문자의 빈도수를 딕셔너리에 저장하기
# 키로 정렬
def f1(x):
return x[0]
# 값으로 정렬
def f2(x):
return x[1]
def most_frequent(str):
d=dict()
for c in str:
d[c]=d.get(c,0)+1
d=sorted(d.items(),key=f2,reverse=True)
for d_one in d:
print(d_one,end='')
print()
most_frequent('aabbbcccdddd')
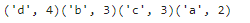
이분탐색으로 사전에 담긴 단어의 인덱스 찾기
def in_bisect(list,str):
low=0; high=len(list)-1;
while(low<=high):
mid=(low+high)//2
comp=list[mid].strip()
if(comp==str):
return mid
elif(comp<str):
low=mid+1
else:
high=mid-1
if(low>high):
return None
f=open('words.txt')
list=[]
for x in f:
list.append(x)
list.sort()
in_bisect(list,'zone')
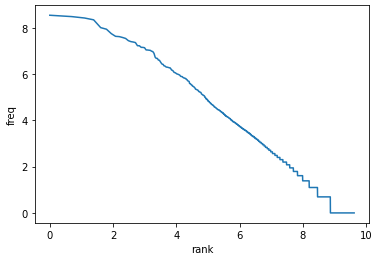
텍스트 파일을 읽어서 단어 빈도수 함수 그리기
import string
import numpy as np
import matplotlib.pyplot as plt
def process_file(filename):
hist = dict()
fin = open(filename)
for line in fin:
process_line(line, hist)
return hist
def process_line(line, hist):
line = line.replace('-', ' ')
for word in line.split():
word = word.strip(string.punctuation + string.whitespace)
word = word.lower()
if len(word) > 0:
hist[word] = hist.get(word, 0) + 1
def f2(x):
return x[1]
hist = process_file('emma-a.txt')
h=sorted(hist.items(),key=f2,reverse=True)
ranks=[]
freqs=[]
rank=0
for w,f in h:
freqs.append(f)
rank+=1
ranks.append(rank)
freqs=np.array(freqs)
ranks=np.array(ranks)
logf=np.log(freqs)
logr=np.log(ranks)
plt.xlabel('rank')
plt.ylabel('freq')
plt.plot(logr,logf)
plt.show()

행렬 계산 문제

def matadd(A,B):
m=len(A)
n=len(A[0])
p=len(B)
q=len(B[0])
if m!=p or n!=q:
raise Exception("Not Same size")
mat=[]
for i in range(m):
row=[0]*n
for j in range(n):
row[j]=A[i][j]+B[i][j]
mat.append(row)
return mat
def matmul(A,B):
m=len(A)
n=len(A[0])
p=len(B)
q=len(B[0])
if n!=p:
raise Exception("Not Match")
mat=[]
for i in range(m):
row=[0]*q
for j in range(q):
for k in range(n):
row[j]+=A[i][k]*B[k][j]
mat.append(row)
return mat
def matpower(A,k):
if k==1:
return A[:]
res=A[:]
for i in range(1,k):
res=matmul(A,res)
return res
A=[[1,2],[-1,2]]
sum=A[:]
for i in range(2,17):
B=matpower(A,i)
sum=matadd(sum,B)
print(sum)
순열 나열
def permute(l,k):
if k<=0 or k>len(l):
return []
if k==1:
ones=[]
for i in l:
ones.append([i])
return ones
list=[]
for i in range(len(l)):
l2=l[:i]+l[i+1:]
sub=permute(l2,k-1)
for part in sub:
list.append([l[i]]+part)
return list
permute([1,2,3,4],3)

조합 나열
def choose(l,k):
if k<=0 or k>len(l):
return []
if k==1:
ones=[]
for i in l:
ones.append([i])
return ones
list=[]
for i in range(len(l)):
l2=l[i+1:]
sub=choose(l2,k-1)
for part in sub:
list.append([l[i]]+part)
return list
choose([1,2,3,4],3)
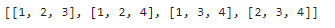
자연수의 분할 나열
def partition_number(n,k,ub=None):
if k<=0 or k>n:
return []
if k==1:
return [[n]]
l=n-k+1 ## upper bound of the largest number
if ub != None and ub<l:
l=ub
s=n//k ## lower bound of the largest number
if n%k > 0:
s += 1
list=[]
for i in range(l,s-1,-1):
sub=partition_number(n-i,k-1,i)
for j in sub:
list.append([i]+j)
return list
# 5를 3개의 자연수로 분할하는 모든 경우
partition_number(5,3)
# 5를 3개의 자연수로 분할하되 각각의 자연수가 2이하가 되도록 표현
partition_number(5,3,2)

집합의 분할 나열
def partition_set(A, k = None):
n = len(A)
if k == None:
res = []
for i in range(n):
res.extend(partition_set(A, i + 1))
return res
if k <= 0 or k > n:
return []
if k == 1:
return [[A[:]]]
res = []
a = A[0]
A2 = A[1:]
sub = partition_set(A2, k - 1)
for part in sub:
res.append([[a]] + part)
sub = partition_set(A2, k)
for part in sub:
for i in range(len(part)):
res.append(part[:i] + [part[i] + [a]] + part[i+1:])
return res
partition_set([1,2,3,4],3)
