
분류란 ‘데이터가 어느 category(범주)에 해당하는지 판단하는 문제’입니다.
분류에서 좋은 모델은 무엇일까요?
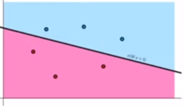
단순하게 ‘틀린 예측 개수가 적은 모델’이라고 생각할 수 있습니다.
이 방식대로 아래 두 모델을 평가하면 어떻게 될까요?
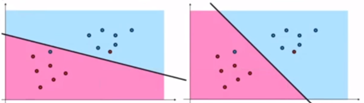
왼쪽 모델과 오른쪽 모델 모두 틀린 개수가 2개이니 둘은 같은 성능의 모델이 됩니다.
이렇게 평가하는 것을 ‘discrete한 평가 방식’이라고 합니다.
하지만 사실 오른쪽이 더 분류를 잘했다고 볼 수 있습니다.
SVM 이론에도 나오지만, Margin이 더 클수록 분류를 잘하기 때문입니다.
이러한 문제점을 극복할 수 있는 ‘Continuous 평가 방식’을 소개합니다.
Discrete방식과 Continuous 방식
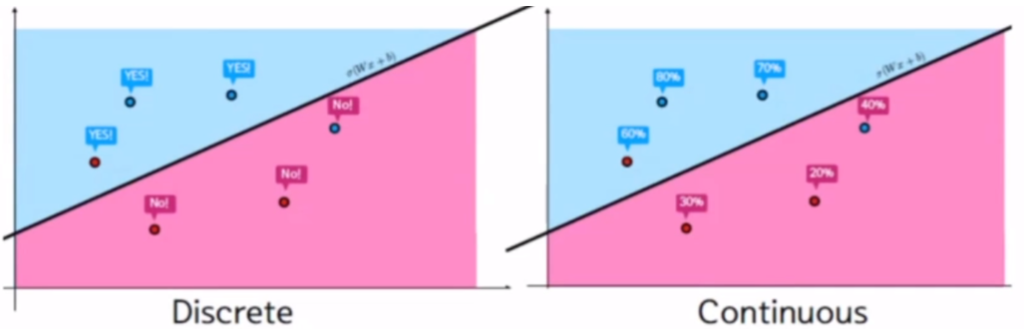
Discrete는 잘 분류하면 yes, 잘못 분류하면 no로 세팅합니다. (그림 오류는 감안해주세요)
이 때는 ‘틀린 예측(no) 개수’와 관련된 Loss Function(모델 평가 함수)이 쓰입니다.
이 Loss가 낮을수록 틀린 예측 값이 적다는 것이고 좋은 모델이 됩니다.
쉽게 이야기하면 두 모델 [ 틀린 개수=loss=2, 틀린개수=loss=0 ]이 있을 때 후자가 더 좋은 모델이라는 것입니다.
Continuous는 각 클래스로 예측될 확률로 세팅합니다.
위 그림으로 설명하면 레코드 마다 P(blue), P(red)를 계산하는 것입니다.
또한 p(blue)+p(red)=1을 만족합니다.
따라서 레코드별 클래스 예측 확률은 아래 그림과 같습니다.
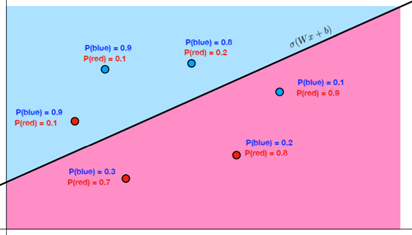
이후 참값에 대한 확률만 남깁니다. 이 참값인 확률이 최대한 높을 때 좋은 모델이 됩니다.
즉 Continuous 방식은 각 레코드별 참값으로 예측될 확률이 높으면 좋은 모델이라고 평가합니다.
단, 확률 하나하나를 따지는 것은 어려우니, 확률들의 곱으로 따집니다.
참값인 확률들의 곱이 클수록 좋은 모델이라고 할 수 있는 것입니다.

이 때는 ‘참값인 확률들의 곱’과 관련된 Loss Function(모델 평가 함수)이 쓰입니다.
이 Loss가 클수록 각 레코드가 참값으로 예측할 확률(곱)이 크다는 것이고 좋은 모델이 됩니다.
앞으로 이 Loss를 최대로 만드는(참값인 확률(곱)을 최대로 만드는) 모델을 찾으면 됩니다.
이렇게 확률을 최대로 만들어서 모델을 찾는 방법을 ‘최대 가능도 추정’이라고 합니다.
하지만
이렇게 loss를 만들면 한 가지 문제점이 생깁니다.
확률들의 곱을 loss를 사용하려고 하니 값이 너무 작은 것이죠. (ex)0.0004032)
따라서 log를 붙이고 덧셈을 하고 마이너스를 붙여서 최소값 문제로 변경했습니다.
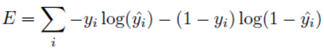
참고로 log를 붙이면 함수 값 자체는 바뀌지만 최소가 될 때의 세타 값은 변하지 않습니다.
(중요한 것은 loss가 최소일 때의 세타 값임)
이 Loss(E)를 Cross-Entropy, 교차 엔트로피라고 합니다.
다시 문제를 풀어 볼까요?
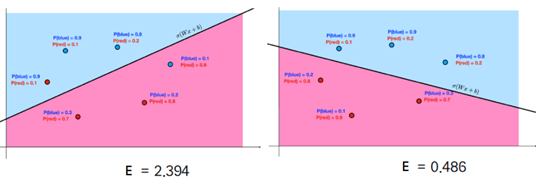
두 모델 중 오른쪽이 loss값이 더 작으니 좋은 모델입니다.
-> 오른쪽 모델이 ‘각 레코드별 참값으로 예측할 확률(곱)’이 더 크니 좋은 모델입니다.
위처럼 이진 분류를 위한 Cross-Entropy식은 다음과 같습니다.
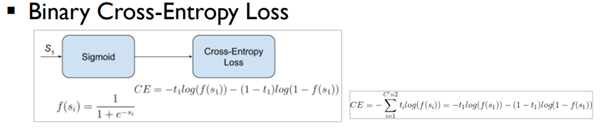
다중 분류를 위한 Cross-Entropy식은 다음과 같습니다.
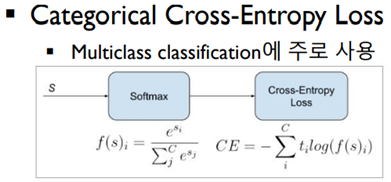
SoftMax 함수
기존에 이진 분류 문제를 풀 때는 활성화 함수로 ‘Sigmoid’를 주로 이용했습니다.
그러나 다중 분류 문제를 풀 때는 ‘SoftMax’라는 활성화 함수를 주로 이용합니다.
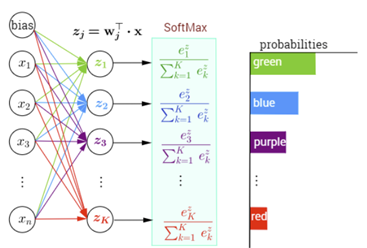
SoftMax는 계산해서 나온 최종 ouput을 확률 값으로 바꿔 줍니다.
예를 들어보겠습니다.
분류할 카테고리가 네 가지(초록,파랑,보라,빨강)가 있습니다.
네트워크(Neural Network)를 통과하면 각 카테고리에 대한 어떤 값이 나오게 됩니다.
예를 들어 (1000,50,10,1)이 나옵니다.
이 값을 SOFT MAX에 통과시키면 (98%, 1.5%, 0.3%, 0.2%)과 같은 확률 값이 나옵니다.
이 확률 값들이 각 카테고리로 분류될 확률이라는 것입니다.
당연히 확률 값들의 합은 1이 됩니다.
이제 우리는 이 확률 값들 중 가장 큰 값으로 분류를 할 수 있습니다.
아래는 다중 분류를 위한 파이썬 코드입니다.
model=tf.keras.Sequential([
tf.keras.layers.Dense(units=48,activation='relu',input_shape=(12,)),
tf.keras.layers.Dense(units=24,activation='relu'),
tf.keras.layers.Dense(units=12,activation='relu'),
tf.keras.layers.Dense(units=3,activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.003), loss='categorical_crossentropy', metrics=['accuracy'])
history= model.fit(train_X,train_Y,epochs=15, batch_size=32,validation_split=0.25)
model.predict(test_X)

test_X에 담긴 첫 번째 데 test_X에 담긴 첫 번째 데이터가 입력으로 들어왔을 때의 결과는 [0.82, 0.16, 0.006]이 되므 1번으로 분류를 하면 됩니다.
원-핫 인코딩
원-핫 인코딩은 클래스 정보를 0과 1로 이루어져 있는 Vector로 만드는 것을 말합니다.
예를 들어 4개의 카테고리가 있는데 output이 0번 클래스라면 (1,0,0,0) 벡터를 만듭니다.
이런 원-핫 인코딩을 하는 이유는 무엇일까요?
만약 출력 노드에서 (0 or 1 or 2)같은 값이 나오면 output이 크기를 내포한다는 의미가 됩니다.
이것은 Regression에서 유용합니다.
만약 답이 2인데 output이 1이면 크기가 2배나 차이가 나니까 오차가 2배인 것을 알 수 있고 이것을 훈련으로 사용할 수 있는 것이죠.
하지만 Classification에서 답이 2인데 ouput이 1이라면 오차가 2배라고 말할 수는 없습니다.
단순히 레이블 값만을 가지고 오차를 확인하는 개념이 아니기 때문입니다.
이렇게 크기가 내포된 상태에서 학습을 진행하면 학습이 잘못 진행될 수도 있습니다.
따라서 크기의 값을 포함하지 않는 형태로 바꿔줘야 합니다.
아래는 원-핫 인코딩에 대한 파이썬 코드입니다.
train_Y=tf.keras.utils.to_categorical(train_Y,num_classes=3) # 원핫코딩 test_Y=tf.keras.utils.to_categorical(test_Y,num_classes=3)

train_Y를 출력한 결과, 0과 1로 이루어진 벡터로 잘 변형된 것을 확인할 수 있습니다.
이제 모델을 제작할 때 왜 출력층의 노드가 (카테고리의 개수)만큼 있는지 알 수 있습니다.
원-핫 인코딩을 이용해서 얻은 (0과 1로 이루어진 벡터)가 정답(train_Y)이 되니 output도 그 모형을 따라야 하는 것이죠.
model=tf.keras.Sequential([
tf.keras.layers.Dense(units=48,activation='relu',input_shape=(12,)),
tf.keras.layers.Dense(units=24,activation='relu'),
tf.keras.layers.Dense(units=12,activation='relu'),
tf.keras.layers.Dense(units=3,activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.003), loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_X,train_Y,epochs=15, batch_size=32,validation_split=0.25)
model.predict(test_X)
test_X에 담긴 첫 번째 데이터가 입력으로 들어왔을 때의 결과는 [0.82, 0.16, 0.006]이 됩니다.
SoftMax를 사용했기 때문에 어쩔 수 없이 확률로 나타나지만, 1에 가까운 한 요소만 의미있기 때문에
[1,0,0]으로 생각해도 지장이 없습니다.
따라서 첫 번째 레이블로 분류됩니다.
GitHub에 파이썬 코드를 제공하겠습니다.
필자의 GitHub는 메인 화면 배너에 있습니다.
감사합니다.