
크루스칼 알고리즘
가중치가 작은 순서대로, 에지를 하나씩 추가하며 MST를 만든다. Cycle이 만들어지면 해당 에지는 버린다. 이를 n-1개의 에지가 만들어질 때까지 진행한다.
MST: 최소 신장 트리, 에지 가중치 합이 최소가 되는 신장 트리
구현 방법
1) 가중치가 작은 에지부터 차례대로 고려하기 위해 최소 힙을 사용한다. 최소 힙을 만든 뒤 루트부터 삭제해서 정렬한다.
2) 에지를 추가하였을 때 cycle이 생기는지 알려면 Union-Find를 이용한다. Find를 해서 같은 root가 나오면 같은 집합이다. (cycle 조건) Union은 최대 n-1회, Find는 최대 2m회가 수행된다.
시간복잡도
(1) O(mlogm) + (2) O(m) = O(mlogm)
추가 설명
그래프의 정점을 연결하는 것이나 유니온파인드에서 합집합을 만드는 것이나 형태는 비슷하다.
다만 차이점이 있다.
유니온파인드는 집합에 이미 있는 원소를 또 집어 넣으면 집합의 형태는 변하지 않는다.
그러나 그래프는 선(에지)이 이어져서 사이클을 만드는 형태로 바뀐다.
즉 이 차이점을 사이클의 구분점으로 사용하면 알고리즘을 구상할 수 있다.
-> 두 노드가 같은 루트를 가지면(같은 트리(집합)에 속하면) 사이클이 발생한다고 생각 가능
이는 아래 이미지에서 [5] 과정을 보고 이해할 수 있다.
유니온 파인드 비 최적화 결과

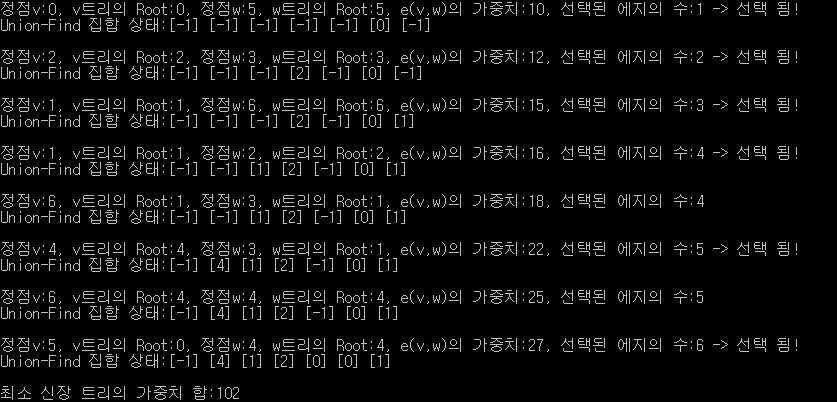
유니온 파인드 최적화 결과 (경로압축 및 가중법칙 적용)


Kruskal을 이용해서 MST의 가중치 합 구하기 (최적화 적용)
#include<time.h>
#include <stdio.h>
#include <stdlib.h>
#define MAX 1000002
// 에지 구조체
typedef struct {
int v, w, x; // v,w는 정점, x는 가중치
}Edge;
int n, m; // 그래프의 정점과 에지 수
typedef struct {
Edge heap[MAX];
int heap_size; // 힙 사이즈가 n이면 heap배열의 원소들이 (idx 1 ~ idx n) 까지 존재
}HeapType;
typedef HeapType* HeapType_ptr;
// 힙 생성 및 초기화 함수
HeapType_ptr heap_init(Edge* e) {
HeapType_ptr h = (HeapType_ptr)malloc(sizeof(HeapType));
// 배열 e를 '완전 이진 트리 배열'로 생각한 뒤 h에 일단 저장
h->heap_size = m;
int i;
for (i = 1; i <= h->heap_size; i++)
h->heap[i] = e[i - 1];
h->heap[i].v = h->heap[i].w = h->heap[i].x = -34529; // 힙의 m+1번째 노드는 쓰레기값 처리 (for. Dev-C++)
// -> 힙 성질을 만족하지 않는 h가 생성됨
return h;
}
// 에지 m개를 원소로 가진 힙을 O(m) 시간에 구현
void MyHeapify(HeapType_ptr h) {
// 힙 성질을 만족하게 할 첫 번째 서브트리 지정
int parent, child, parent_save, child_save;
child = child_save = h->heap_size; // 말단 노드부터 비교 시작
parent = parent_save = h->heap_size / 2;
// 모든 서브트리에 대해 힙 성질 만족 시키기
Edge temp;
while (parent > 0) {
// 현재 부모 노드의 값을 temp에 저장
temp = h->heap[parent];
// 자식이 힙을 벗어나지 않았으면 반복문 진행
while (child <= h->heap_size) {
// 두 자식노드가 있으면 더 작은 자식노드를 찾는다.
if ((h->heap[parent * 2].x >= 0) && (h->heap[(parent * 2) + 1].x >= 0)) {
if ((h->heap[parent * 2].x) < (h->heap[(parent * 2) + 1].x))
child = parent * 2;
else
child = (parent * 2) + 1;
}
// temp 노드를 현재 자식의 부모 노드의 위치에 있다고 생각했을 때, 값이 작거나 같으면 힙 조정할 필요가 X
if (temp.x <= h->heap[child].x)
break;
// 부모 노드 자리에 자식 노드의 값들을 저장
h->heap[parent] = h->heap[child];
// 한 단계 아래로 이동
parent = child;
child *= 2;
}
// child > h->heap_size로, 위치해야 될 노드에 저장
h->heap[parent] = temp;
// 서브트리 재지정
parent = parent_save = parent_save - 1;
child = child_save = parent * 2; // p가 1이고 c가2면 전체 노드를 다 보게 됨
}
}
// 힙에서 최소 가중 에지를 삭제하여 되돌려 줌
Edge myDeleteMin(HeapType_ptr h) {
int parent, child;
Edge item, temp;
item = h->heap[1]; // 루트 노드 값을 반환하기 위해 item변수로 옮긴다.
temp = h->heap[(h->heap_size)--]; // 말단 노드 값을 temp변수로 옮기고 힙 사이즈를 1 줄인다. (temp값이 처음에는 루트에 위치해있다고 생각)
parent = 1;
child = 2; // 루트의 왼쪽 자식부터 비교한다.
while (child <= h->heap_size) {
if ((h->heap[parent * 2].x >= 0) && (h->heap[(parent * 2) + 1].x >= 0)) {
if ((h->heap[parent * 2].x) < (h->heap[(parent * 2) + 1].x))
child = parent * 2;
else
child = (parent * 2) + 1;
}
// 말단 노드를 현재 자식의 부모 노드의 위치에 있다고 생각했을 때, 값이 작거나 같으면 힙 조정할 필요가 X
if (temp.x <= h->heap[child].x)
break;
h->heap[parent] = h->heap[child];
parent = child;
child *= 2;
}
h->heap[parent] = temp;
return item;
}
// 유니온파인드 구조체
typedef struct {
int parent;
int count;
}uf;
typedef uf* ufp;
// 유니온 파인드 생성 및 초기화 함수
ufp uf_init(int n) {
ufp u = (ufp)malloc(sizeof(uf) * n);
int i;
for (i = 0; i < n; i++) {
u[i].parent = -1;
u[i].count = 1;
}
return u;
}
// 경로압축을 하고 집합의 루트를 반환한다.
int myFind(ufp u, int curr) {
if (u[curr].parent == -1)
return curr;
// 루트 노드 찾기
int tmp = myFind(u, u[curr].parent);
// 경로 압축 (리턴해서 받은 루트 노드의 값을 부모 노드의 값으로 사용)
// 다음에 comp_Find가 호출되면 순환 횟수가 줄어든다.
u[curr].parent = tmp;
return tmp;
}
// 가중법칙을 적용하여 합집합을 만든다.
void myUnion(ufp u, int a, int b) {
int root1 = myFind(u, a);
int root2 = myFind(u, b);
int temp = u[root1].count + u[root2].count;
if (u[root1].count < u[root2].count) {
u[root1].parent = root2;
u[root2].count = temp;
}
else {
u[root2].parent = root1;
u[root1].count = temp;
}
}
// 입력으로 주어진 그래프를 읽는다.
Edge* readGraph() {
int i; // iteration 변수
// 정점의 수, 에지의 수 입력
scanf_s("%d %d", &n, &m);
Edge* e = (Edge*)malloc(sizeof(Edge) * m); // 에지 배열 생성
for (i = 0; i < m; i++)
scanf_s("%d %d %d", &e[i].v, &e[i].w, &e[i].x);
return e;
}
int main() {
Edge* e = readGraph(); // 그래프의 모든 에지를 e배열에 저장
HeapType_ptr h = heap_init(e); // 힙 자료구조에 에지 배열 원소를 순차 대입
MyHeapify(h); // 힙 성질 맞추기
// 힙에서 삭제하면서 정렬
int i;
for (i = 0; i < m; i++)
e[i] = myDeleteMin(h);
ufp u = uf_init(n); // 유니온 파인드 집합 생성
int vroot, wroot, sum, selected_edge; // 각 집합의 루트, 가중치 합계, 연결한 에지의 수
selected_edge = sum = 0;
// 연결한 에지의 수가 n-1이 되면 스패닝 트리 완성 -> 반복문 빠져 나옴
for (i = 0; selected_edge < (n - 1); i++) {
vroot = myFind(u, e[i].v);
wroot = myFind(u, e[i].w);
// find를 해서 같은 root가 나오면 이미 같은 집합 -> 연결하면 사이클이 생성됨
if (vroot != wroot) {
myUnion(u, vroot, wroot);
selected_edge++;
sum += e[i].x;
}
}
printf("%d", sum);
free(h);
free(e);
return 0;
}
