
IRIS 실습
IRIS: (붓꽃이 여러 종류가 있을텐데) 각각의 붓꽃이 어떤 품종인지 구분해 놓은 측정 데이터
ex) 푸밀라붓꽃에 대한 측정 데이터, 술붓꽃에 대한 측정 데이터 등등

목표) IRIS데이터를 이용해서 새로 채집한 붓꽃의 품종을 예측하는 머신러닝 모델 구현
from sklearn.datasets import load_iris iris_dataset=load_iris()
- 먼저 사이킷런 패키지로 iris데이터를 불러 옵니다.
사이킷런은 python의 대표적인 머신러닝 프레임워크입니다.
# 1. 데이터 적재
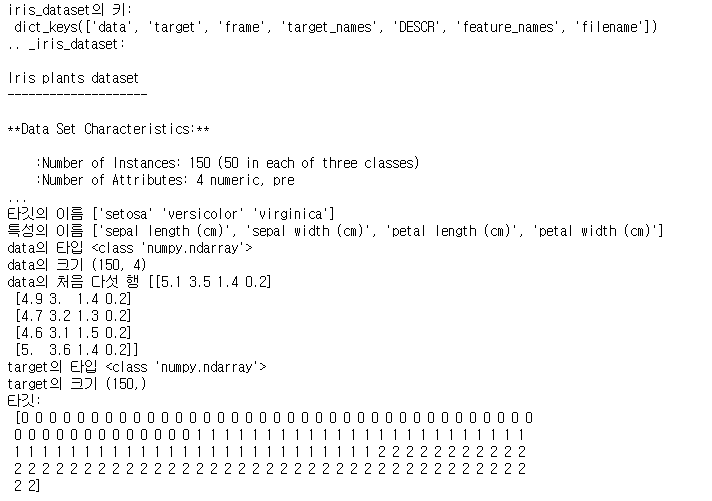
print("iris_dataset의 키:\n",iris_dataset.keys())
print(iris_dataset['DESCR'][:193]+'\n...') #descr이 뭔지 확인 -> dataset의 특징 출력됨
print("타깃의 이름",iris_dataset['target_names'])
print("특성의 이름",iris_dataset['feature_names'])
print("data의 타입",type(iris_dataset['data']))
print("data의 크기",iris_dataset['data'].shape)
print("data의 처음 다섯 행",iris_dataset['data'][:5])
print("target의 타입",type(iris_dataset['target']))
print("target의 크기",iris_dataset['target'].shape)
print("타깃:\n",iris_dataset['target'])
2. iris 데이터의 특징을 알아 봅시다.
이 데이터의 총 크기는 150개이고 iris_dataset[‘target’]과 iris_dataset[‘data’]로 나뉩니다.
타킷(품종)의 이름은 'setosa','versicolor','virginica'이고 이를 바탕으로 iris_dataset['target']는 0,1,2로 저장된 형태를 보입니다. 특성의 이름은 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'이고 이는 iris_dataset['data']의 원소입니다. 이 특징들은 타깃을 분류하기 위해 필요합니다.
# 2. 훈련데이터와 테스트 데이터
# 150개 데이터를 train과 test로 나눔
from sklearn.model_selection import train_test_split
# train:test = 075:0.25 (3대1로 나누는 객체)
X_train, X_test, y_train, y_test =train_test_split(iris_dataset['data'],
iris_dataset['target'],
random_state=0)
# train에 쓰이는 입력값
# test에 쓰이는 입력값
# train에 쓰이는 참값
# test에 쓰이는 참값
# random_state를 보내면 랜덤으로 데이터를 나눔, 0~74 데이터로 나누는 개념이 아니라 0,2,7,8,9,...해서 75개 만든다는 것
print("x_train 크기:",X_train.shape)
print("y_train 크기:",y_train.shape)
print("X_test 크기:",X_test.shape)
print("y_test 크기:",y_test.shape)
3. 사이킷런은 train_test_split객체를 제공합니다. 이는 머신러닝을 하기 전 데이터를 (훈련 데이터와 테스트 데이터)로 나누기 위해 필요합니다.
이렇게 나누는 이유는 머신러닝의 목표가 ‘새로운 데이터에 대해서도 잘 예측하는 것’이기 때문입니다.
따라서 75%는 머신러닝 훈련(학습)용으로 사용하고 나머지 25%는 시험용으로 사용해서 머신러닝이 잘 이루어졌나 테스트합니다.
x_train 데이터는 iris_dataset[‘data’]의 75%로 품종의 특성을 가집니다.
x_test 데이터는 iris_dataset[‘data’]의 25%로 품종의 특성을 가집니다.
y_train 데이터는 iris_dataset[‘data’]의 75%로 품종의 타킷을 가집니다.
y_test 데이터는 iris_dataset[‘data’]의 25%로 품종의 타깃을 가집니다.

# 3. 데이터 살펴보기
import pandas as pd
from preamble import *
import matplotlib.pyplot as plt
# x_train 데이터를 사용해서 데이터 프레임을 만든다
# 열의 이름은 iris_dataset.feature_names에 있는 문자열을 사용합니다.
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names)
# 데이터 프레임을 사용해 y_train에 따라 색으로 구분된 산점도 행렬을 만든다.
# figsize는 크기, marker: 점을 표시, cmap:colormap -> mglearn.cm3는 rgb
a=pd.plotting.scatter_matrix(iris_dataframe,c=y_train, figsize=(15,15), marker='o',
hist_kwds={'bins':20},s=60,alpha=8,cmap=mglearn.cm3)
# plt.show() 산점도 보기
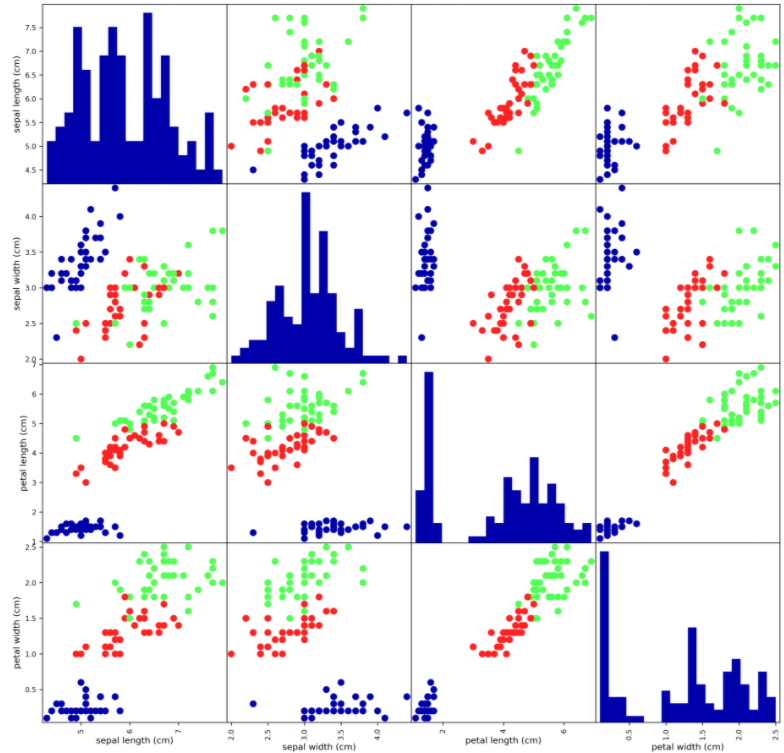
4. 머신러닝 학습을 하기 전 데이터를 살펴보겠습니다.
각각의 x축과 y축에 해당하는 데이터를 산점도로 표현하였습니다.
타깃은 (0,1,2)총 세 가지이니 산점도에서 원소들의 색도 세 가지가 됩니다.
# 4. 첫 번째 머신러닝 모델: KNN from sklearn.neighbors import KNeighborsClassifier knn=KNeighborsClassifier(n_neighbors=1) knn.fit(X_train,y_train) #지도학습 시키기
5. 이제 처음으로 머신러닝을 할 것입니다.
scikit-learn 패키지로 여러 가지 학습 모델을 만들 수 있는데, 여기서는 분류 모델을 만들 것입니다.
분류 모델의 이름은 KNN이고, KNeighborsClassifier 클래스를 인스턴스화하는 방식으로 생성을 합니다.
knn.fit(훈련 데이터)를 통해서 75%의 품종의 특성 데이터를 가지고 품종의 타깃을 분류하는 학습을 하고 모델을 만드는 것입니다.
y_train도 함수 안에 같이 들어가게 되는데, 이는 학습을 위해 필요합니다.
이를 정답을 이용해서 학습을 하는 ‘지도 학습’이라고 합니다.
# 5. 예측 및 모델 평가하기
X_new=np.array([[5,2.9,1,0.2]])
print("X_new.shape",X_new.shape)
prediction=knn.predict(X_new) # X_new에 대해서 예측해보기
print("예측:",prediction)
print("예측한 타깃의 이름:",iris_dataset['target_names'][prediction])
y_pred=knn.predict(X_test) # 25% 테스트 데이터가지고 시험보기
print("테스트 세트에 대한 예측값:\n",y_pred)
print("테스트 세트의 정확도:{:.2f}".format(np.mean(y_pred==y_test)))
print("테스트 세트의 정확도:{:2f}".format(knn.score(X_test,y_test)))
6. 이제 학습 모델이 잘 만들어졌나 테스트를 할 것입니다. test데이터를 사용하기 전에 x_new데이터로 간단하게 테스트를 해보았습니다.
테스트는 predict함수로 진행됩니다.
학습 모델로 x_new의 예측치를 구한 결과 ‘0’으로 분류하였습니다.
즉 데이터 특성 [5,2.9,1,0.2]이 들어 왔을 때 학습 모델은 ‘setosa’로 예측하고 분류한다는 의미입니다.
이제 이전에 만든 25%의 특성 데이터로 테스트를 해보겠습니다.
25%에 해당하는 예상 타깃들은 아래 사진들과 같습니다.
마지막으로 학습 모델의 정확도를 구해 보았습니다.
새로 들어온 데이터에 대해 얼마나 정확하게 분류했는지 알아보는 시간입니다.
위처럼 predict함수를 통해 미리 구한 예측치가 있다면 np.mean(y_pred==y_test) 소스를 통해서 해결이 가능합니다.
그렇지 않다면, knn.score(x_test,y_test)함수를 통해 한 번에 예측도 하고 정확도를 구할 수 있습니다.
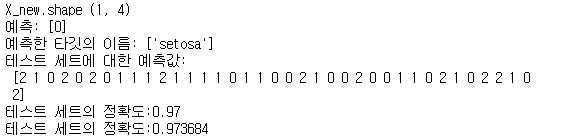
지금까지 사이킷런으로 학습 모델을 만들어 보고 이 모델이 얼마나 쓸모가 있는지 테스트를 해보았습니다.
위 설명에서는 학습 데이터를 가지고 모델을 만든다고 나와 있습니다.
그러나 사실 KNN은 예외적으로 모델을 뒤늦게 생성합니다.
이번 포스팅은 일반적인 머신러닝의 진행 과정을 설명하려다 보니 약간의 오류가 있습니다!!
다음 포스팅에 올라가는 KNN 이론에 대해 꼭 확인해주세요!
25 thoughts on “ML – Iris 실습으로 처음 만드는 머신러닝 모델”
Hello there! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche. Your blog provided us useful information to work on. You have done a outstanding job!
You flatter me immensely.
Have you ever considered writing an e-book or guest authoring on other sites? I have a blog based on the same subjects you discuss and would love to have you share some stories/information. I know my visitors would value your work. If you are even remotely interested, feel free to shoot me an e-mail.
I’m a student. No, thank you. I’m sorry.
Hiya, I’m really glad I have found this information. Today bloggers publish just about gossips and net and this is really irritating. A good blog with interesting content, that’s what I need. Thank you for keeping this web site, I’ll be visiting it. Do you do newsletters? Can’t find it.
I can talk by mail. Thank you very much. (cse@shacoding.com)
Do you mind if I quote a couple of your articles as long as I provide credit and sources back to your website? My blog site is in the very same niche as yours and my visitors would truly benefit from a lot of the information you present here. Please let me know if this ok with you. Many thanks!
of course, thank you~
Simply wish to say your article is as surprising. The clearness in your put up is just excellent and i can assume you’re a professional in this subject. Fine with your permission allow me to clutch your feed to keep updated with impending post. Thank you one million and please keep up the gratifying work.
I feel this is among the most important info for me. And i am happy reading your article. However wanna statement on few basic things, The site taste is great, the articles is in point of fact nice : D. Good activity, cheers
The next time I read a weblog, I hope that it doesnt disappoint me as a lot as this one. I mean, I know it was my option to read, but I truly thought youd have something interesting to say. All I hear is a bunch of whining about something that you could fix in the event you werent too busy on the lookout for attention.
I’m sorry. I’m still a student and I have a lot to study, so the update cycle is not constant. There is a limit to writing interesting articles due to lack of information. I will become a blogger who is developing more and more.
You can check the post related to machine learning on the data mining board, so please check it out. Machine learning posting will be carried out again from mid-June to late June.
Thanks for another informative web site. Where else could I get that type of info written in such an ideal way? I’ve a project that I’m just now working on, and I have been on the look out for such information.
The ‘data mining’ category provides ML issues. However, please refer to the fact that it is written in the R language. Sorry for the late reply.
That is the right weblog for anybody who needs to seek out out about this topic. You understand a lot its nearly laborious to argue with you (not that I truly would need匟aHa). You positively put a new spin on a subject thats been written about for years. Great stuff, simply nice!
Thank you very much. But Please understand that I will post the backend for the time being.
We’re a group of volunteers and starting a new scheme in our community. Your website offered us with valuable information to work on. You’ve done a formidable process and our whole neighborhood will likely be thankful to you.
Thank you for using the website!
Hello my friend! I wish to say that this post is amazing, nice written and include almost all vital infos. I抎 like to see more posts like this.
I抎 should verify with you here. Which isn’t one thing I often do! I enjoy studying a post that may make folks think. Additionally, thanks for allowing me to remark!
My brother recommended I may like this website. He was once entirely right. This post actually made my day. You can not believe simply how so much time I had spent for this information! Thanks!
I am curious to find out what blog platform you’re working with?
I’m experiencing some small security issues with my latest site and I would like to find something more
safeguarded. Do you have any suggestions?
my platform is wordpress. I use the basic safe guard provided by Word Press.
Great beat ! I would like to apprentice whilst you amend your site, how could i subscribe for a blog site?
The account aided me a applicable deal. I have been a little bit acquainted of
this your broadcast provided bright transparent idea