
정렬
내부 정렬
데이터가 적어서 메인 메모리 내에 모두 저장시켜 정렬이 가능할 때
외부 정렬
메모리 용량을 초과할 정도로 데이터가 많아서 보조기억장치에서 저장된 파일을 정렬할 때
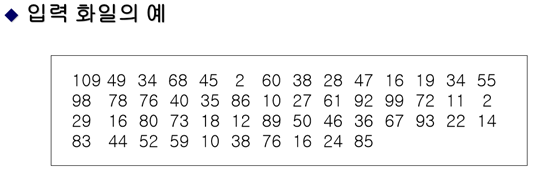
런: 하나의 파일을 여러 개의 서브 파일로 나누어 내부 정렬 기법을 사용하여 정렬시킨 파일
-> 런들을 합병하여 원하는 하나의 정렬된 파일을 만든다.
[ 메인 메모리에 5개의 수만 저장할 수 있다고 가정하고 런(정렬된 서브파일)들을 만든 결과 ]

합병의 기본 논리
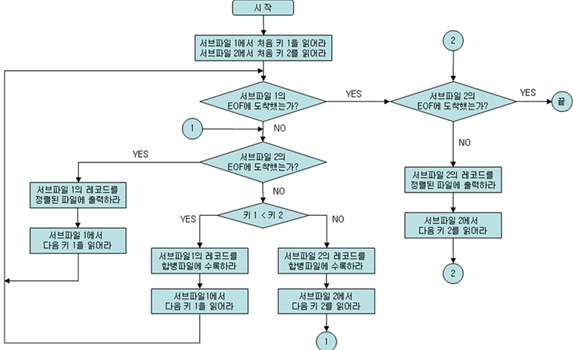
서브파일1 레코드 값이 작다 -> 서브 파일1의 레코드를 출력
서브파일2 레코드 값이 작다 -> 서브 파일2의 레코드를 출력
서브파일1 끝났는데 서브파일2가 남아 있다 -> 서브 파일 2의 레코드를 정렬된 파일에 출력
서브파일2 끝났는데 서브파일1이 남아 있다 -> 서브 파일1의 레코드를 정렬된 파일에 출력
정렬 단계
정렬할 파일의 레코드들을 지정된 길이의 서브 파일로 분할해서 런을 만들고 정렬
합병 단계
정렬된 런들을 합병해서 보다 큰 런을 만들고, 이것들을 다시 입력 파일로 재분배해서 합병
(80명이 있다, 20명의 런을 만들겠다 -> 런 4개 만듦 -> 런 2개 합병을 두 번 -> 런 2개 합병한 것들을 다시 합병)
– 런 생성 방법
1. 내부 정렬
2. 자연 선택
(1) 내부 정렬
파일을 n개 레코드씩 분할 후 내부 정렬 -> 제일 마지막 런을 제외하고 모두 길이가 같다. (n개씩)
(2) 자연 선택
– 첫 번째 런 생성
1) 입력 파일에서 버퍼에 m개 레코드 판독
2) 버퍼에서 키 값이 가장 작은 레코드를 선택해 출력
3) 입력 파일에서 다음 레코드를 판독해 출력된 레코드와 대체

<동결돼서 예비 장소로 가야 되는데, 예비 장소의 버퍼도 다 차면, 동결된 것을 제외하고 정렬해서 출력 -> 출력된 것이 런1 -> 동결된 것은 원래 장소로 감>
// 버퍼가 다 차고 새로 들어온게 방금 출력한 것보다 작다 -> 런 하나 끝
– 계속해서 런 생성
1) 동결된 레코드 모두 해제(예비 장소로 간 레코드들을 메모리 버퍼로 이동)
2) 첫 번째 런 생성의 단계의 (2)로 돌아가 새로운 런 선택
자연 선택 방법의 장점
내부 정렬보다 런의 길이가 길어짐 -> 런 개수 줄어듦 –> 합병 개수도 줄어듦 -> 합병 과정 비용(시간) 줄임 ->
자연선택 런의 평균 예상 길이: 2m
자연 선택 실습


- 7 21 101 55를 버퍼에 올림
- 버퍼 중 7이 제일 작으니 출력
- 14(다음 레코드)를 가져와서 출력된 것(7)과 비교, 더 크니 동결x, 버퍼(14,31,101,55)에서 제일 작은 것 출력 -> 14출력
- 20도 (3)과 같은 방식으로 출력됨, 11(다음 레코드)를 가져와서 출력된 것(20)과 비교, 더 작으니 동결, 동결되면 예비 장소로 이동
- 60(다음 레코드)를 가져와서 출력된 것(20)과 비교[11아님], 더 크니 동결 x, 버퍼에서 제일 작은 것 출력 -> 31출력
- 2(다음 레코드)를 가져와서 출력된 것(31)과 비교, 더 작으니 동결, 동결되면 예비 장소로 이동
——> 같은 방식 반복하다가 17까지 예비 장소로 이동함 (예비 공간의 버퍼 다 참)
[주의] 예비 공간이 다 찬다고 끝나는게 아님 (새로 들어온 것이 방금 출력보다 작아서 예비 장소로 이동해야 될 때 끝 처리를 시작함)
-> 59(다음 데이터)를 가져와서 출력된 것(57)과 비교, 더 크니 동결 x, 버퍼에서 제일 작은 것 출력 -> 59출력
-> 9(다음 데이터)를 가져와서 출력된 것(59)와 비교, 더 작으니 동결 -> (끝 처리 시작)
-> 동결된 것을 제외하고 버퍼에 있는 것을 작은 것부터 차례대로 출력 (60출력, 98출력, 101출력)
-> 이렇게 해서 출력된 것들이 런1 (런 한 개 끝)
(계속해서 런 생성)
-> (9)는 다시 입력 파일로 돌아감
-> 예비장소에 있는 것들을 다시 버퍼에 옮김

-> (런1 만드는 방식대로 런2를 만듦)
-> (입력 파일로부터 모든 런을 만듦)

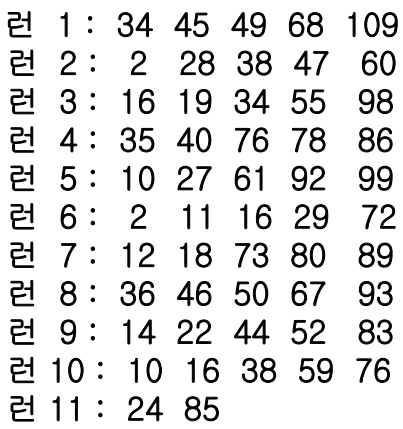
내부 정렬: 14개
// 총 54개, 버퍼크기4 -> 런1~런13은 네 개의 레코드, 런14는 두 개의 레코드
자연 선택: 5개

차이점을 나타내는 매개변수
1) 적용하는 내부 정렬 방식(퀵,합병,선택 등)
2) 내부 정렬을 위해 할당된 메인 메모리의 크기 (버퍼 크기)
3) 동시에 처리할 수 있는 런의 수
4) 정렬된 런들의 보조 저장 장치에서의 저장 분포 (얼마나 레코드들이 흩어졌는지도 영향을 줌)
정렬/합병 기법의 성능
매개변수에 따라 런의 수와 합병의 패스 수(런 2개 합칠 때 패스 1개)가 결정됨

패스가 적을수록 성능이 좋음
-> 가능한 런의 길이를 길게 만들어 런의 수를 최소화해야 됨!
합병
m원 합병
입력파일 m개(런들을 m개의 파일에 분배 후 합치는 개념임), 출력파일 1개
-> 총 m+1개 파일을 사용
단점: 한 패스에 합병이 끝나지 않으면 런들을 다시 분배하기 위해 복사,이동해야 함
이상적 합병: m개의 런에 m개의 입력 파일 사용하여 한 번에 m-원 합병을 적용
패스 수: O(logmN), 한 번 패스 후 합병된 런의 크기는 m배, 런의 수는 1/m개
If) 2원 합병의 경우 (런들을 2개씩 묶어서 2개의 파일에 분배)
- 한 번 패스 후 합병된 런의 크기는 2배, 런의 수는 1/2개
- n개의 런으로 분할된 파일 정렬 위한 패스 수: ceil(log2N) <트리 구조와 비슷하므로>
m원 합병 실습: 6개의 런에 대한 2원 합병
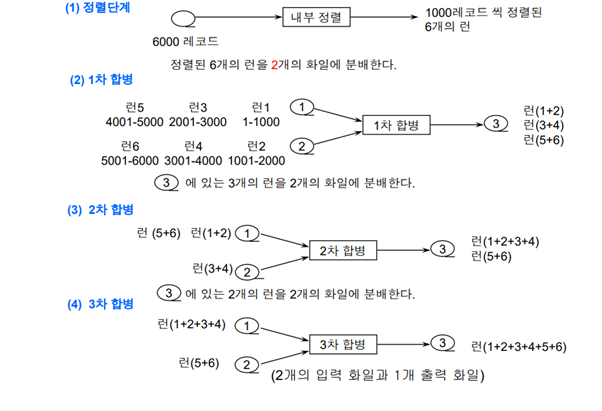
- 런6개를 (런5,런3,런1)은 ‘입력파일1’이 처리, (런6,런4,런2)는 ‘입력파일2’가 처리하도록 분배함
- (런1-런2) 먼저 합병 -> (런3-런4) 합병 -> (런5-런6) 합병
- 런(1+2), 런(3+4), 런(5+6) 생성 완료 [1차 합병 완료]
- 1차 합병된 런 3개를 {런(1+2),런(5+6)}은 ‘입력파일1’이 처리, 런(3+4)는 ‘입력파일2’가 처리하도록 분배함
- {런(1+2)-런(3+4)} 먼저 합병 -> 런(5+6)은 그대로 옴
- 런(1+2+3+4), 런(5+6) 생성 완료 [2차 합병 완료]
- 2차 합병된 런 2개를 런(1+2+3+4)은 ‘입력파일1’이 처리, 런(5+6)은 ‘입력파일2’가 처리하도록 분배함
- {런(1+2+3+4)-런(5+6)} 합병
- 런(1+2+3+4+5+6) 생성 완료 [3차 합병 완료]
m원 합병 실습: 5개의 런에 대한 2원 합병

1. 런1(50 95 110) 은 입력파일1, 런2는 입력파일2, 런3은 입력파일1, … 런5는 입력파일1로 분배
-> 합병 후 출력을 파일3에 함

2. 1차 합병 후 재분배를 진행
[ 런1(15,30,50,95,100,110)을 입력파일1, 런2를 입력파일2, 런3을 입력파일1로 분배 ]
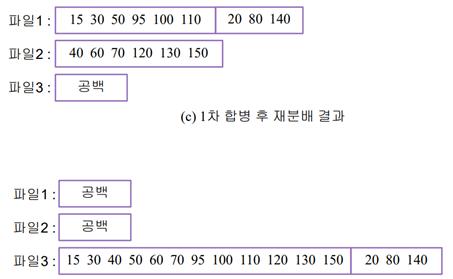
3. 2차 합병 후 출력을 파일3에 함 -> 재분배를 진행

4. 3차 합병 후 출력을 파일3에 함
m원 합병 실습: 6개의 런에 대한 3원 합병

* 파일 수는 늘어난다 (3개에서 4개로),
* 합병과 분배 수는 줄어든다(3번에서 2번으로),
* 비교하는 수는 늘어난다. (2개 런 비교하다가 3개 런 비교해서 합병해야 하므로)
m원 균형 합병
2m개의 파일 필요 (m개 입력 파일, m개 출력 파일)
m원 합병의 단점(파일의 재분배로 인한 많은 I/O사용)을 극복한 합병 방법
패스 수: O(logmN), 한 번 패스 후 합병된 런의 크기는 m배, 런의 수는 1/m개 <m원 합병과 일치>
2원 균형 합병의 예시

출력파일 3,4가 2차 합병에서는 입력파일3,4로 됨 (이를 번갈아가므로 파일 재분배 필요 x)
m원 균형 합병 실습: 5개의 런에 대한 2원 균형 합병
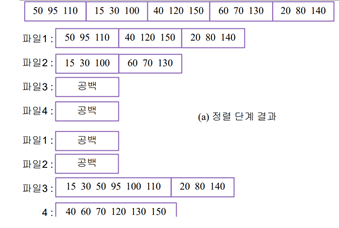
1. 처음에는 m원 합병과 큰 차이가 없음 (합병 후 출력을 한 개로 하느냐 두 개로 하느냐)

2. 2차 합병에서는 출력파일 3,4가 입력파일3,4로 돼서 합병 후 파일1,2에 출력함

3. 3차 합병에서는 출력파일 1,2가 입력파일1,2가 돼서 합병 후 파일4에 출력함
(마무리 단계일 때는 출력 파일 1개만 사용 / 파일3을 사용해야 됨)
m-원 균형 합병 기법의 단점
2m개의 파일 필요(m개의 입력파일, m개의 출력파일)
m-원 다단계 합병
m개의 입력 파일과 1개의 출력 파일
-> 공백 파일 한 개를 출력 파일로 사용
-> 파일의 재분배가 필요 없고 파일 수는 2m에서 m+1로 줄어듦
m-원 다단계 합병의 초기 런 분배 방법: 완전 피보나치 분배
완전 피보나치 분배
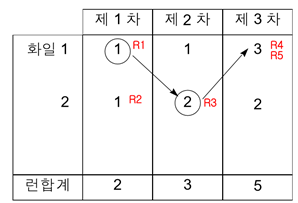
피보나치 수열을 활용하여 런을 분배! (자기는 그대로두고 나머지에 분배, 분배할 때는 2^n-1개씩, n은 차수)
<1차는 파일1에서 분배, 2차는 파일2에서 분배, ..>
m원 다단계 합병 실습: 5개의 런에 대한 2원 다단계 합병


1. 완전 피보나치 분배 결과

2. 1차 합병 -> 합병하고 남은 것은 놔둠[20,80,40], 공백이 생긴 파일(파일2)은 다음 출력 파일이 된다.
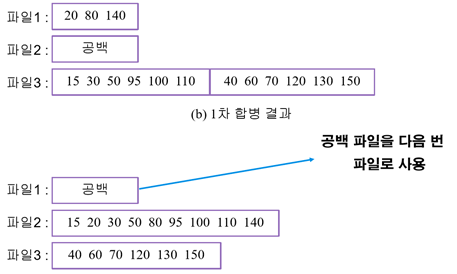
3. 2차 합병 -> 합병하고 남은 것[40,60,…]은 놔둠, 공백이 생긴 파일(파일1)은 다음 출력 파일이 된다.
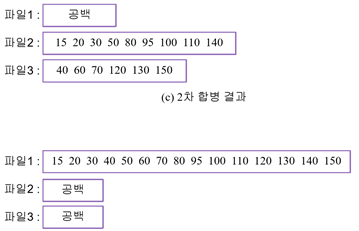
4. 3차 합병 -> 2원 다단게 합병 종료

m원 다단계 합병 실습: 17개의 런에 대한 3원 다단계 합병
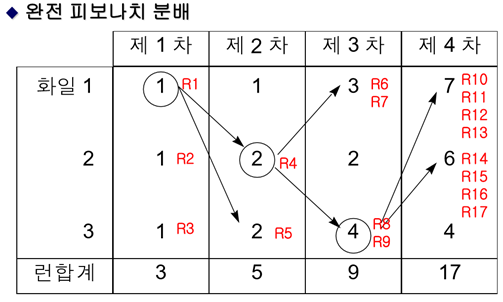
(자기는 그대로두고 나머지에 분배, 분배할 때는 2^n-1개씩, n은 차수)
Ex) 파일1은 그대 로두고 파일2,파일3에 2^(1-1)개씩 분배 // R4,R5
<1차는 파일1에서 분배, 2차는 파일2에서 분배,3차는 파일3에서 분배….>
<차수%3해서 1이면 파일1에서 분배, 2면 파일2에서 분배, 0이면 파일3에서 분배 진행>
<피보나치 분배가 안 되면 공백인 런을 추가해서 피보나치 수로 맞춤>

- 파일1은 그대로두고 파일2,3에 런4,런5분배
- 세 개의 런 합병(파일1,2,3의 런1,2,3합병)해서 파일4에 출력 -> 파일1이 공백이 됨
- 세 개의 런 합병(파일2,3,4의 런4,5,합병된 런을 합병)해서 파일1에 출력
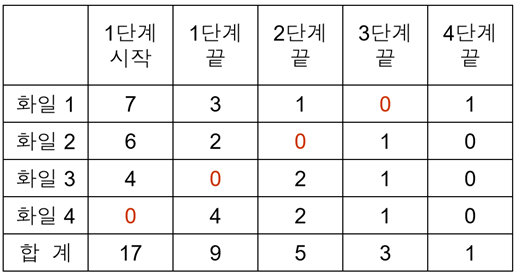
m원 다단계 합병 특징
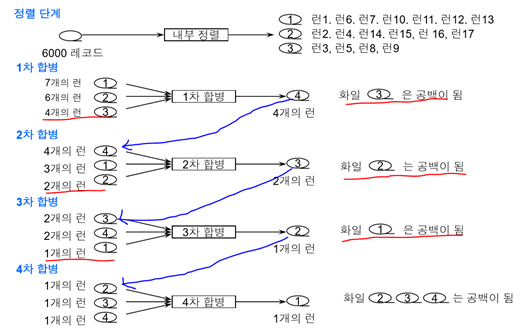
<피보나치 분배하면 항상 하나의 파일은 공백이 됨!>
<런의 수가 제일 작은 것이 공백이 됨!>
선택 트리를 이용한 합병
m개의 런 중 가장 작은 키 값의 레코드를 계속 선택해서 출력
선택 트리를 사용하면 비교 횟수를 줄일 수 있음
// 단말노드(잎)는 각 런의 최소 키 값 원소를 나타냄
// 내부노드(중간 노드)는 두 자식 중에서 최소값을 나타냄
선택 트리 中 승자 트리 예시
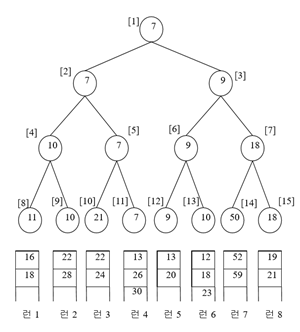
특징: 승자(작은 것)가 부모 노드로 올라감
합병 알고리즘

1. 7출력(제일 작은 값) -> 7이 처음 왔던 곳(잎)에 13이 올라감 -> 13과 21시합 -> 13이 올라감 ->13과 10시합 -> 10이 올라감 -> 10과 9 시합 -> 9 올라감
2. 9출력(두번째로 작은 값) -> … <모두 출력할 때까지 반복>

< m-1번(7번) 비교, m-1번(7번) 비교, log2m번(약 3번) 비교 >
< 트리의 구조를 이용하므로 첫 번째 출력 이후에는 (루트의 왼쪽 서브트리-루트의 오른쪽 서브트리) 중 한 부분만 비교함 >
선택 트리 中 패자 트리 예시
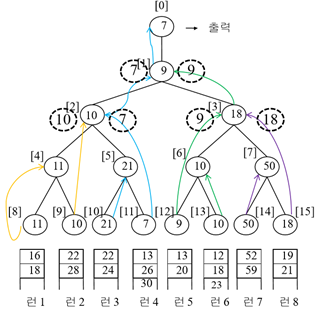
특징: 패자(큰 것)는 부모 노드로 올라감, 승자(작은 것)는 그 위의 노드로 올라감 [처음], 패자는 옆의 노드에 위치, 승자는 더 위로 올라감 [이후]
로직 설명
11과 10이 경기 -> 패자인 11이 올라감 -> 승자인 10은 더 위로 올라감,
21과 7이 경기 -> 패자인 21이 올라감 -> 승자인 7은 더 위로 올라감,
9과 10이 경기 -> 패자인 10이 올라감 -> 승자인 9는 더 위로 올라감,
50과 18이 경기 -> 패자인 50이 올라감 -> 승자인 18은 더 위로 올라감
<더 위로 올라간 것을 기준으로 시합>
10과 7이 경기 -> 패자인 10은 옆으로 감 -> 승자인 7은 위로 올라감,
9와 18이 경기 -> 패자인 18이 옆으로 감 -> 승자인 9는 위로 올라감
<더 위로 올라간 것을 기준으로 시합>
7과 9가 경기 -> 패자인 9는 옆으로 감(루트) -> 승자인 7은 위로 올라감 (루트의 루트)
비교 횟수는 승자 트리와 완전히 동일함