– 입력 순차 파일
레코드가 입력되는 순서대로 저장되는 파일
(ex) 먼저 오는대로 앞에 앉아)
– 키 순차 파일
레코드의 특정 필드 값 순서에 따라 저장되는 파일
(ex) 너 번호는 정해져 있어. 그 자리에 앉아)
순차파일의 가장 일반적인 파일: 스트림 파일
- 파일에 저장되어 있는 순서에 따라 데이터를 접근하는 파일
- 데이터가 하나의 연속된 바이트 스트림으로 구성
종류: 순차 접근 스트림 파일, 임의 접근 스트림 파일(임의지만 기존 위치에 오프셋을 더해서 접근)
<순차 접근 스트림 파일>
: 해당 위치에서 시작하여 해당 바이트 값을 전송,
n번째 바이트 값을 판독하기 위해서는 n-1번째 바이트 값을 판독 해야 됨
순차 접근을 위한 함수
(fputc)


fputc(‘S’,streamfile) -> ‘S’ 출력 후 index 1을 가리킴
fputc(‘M’,streamfile) -> ‘M’ 출력 후 index 2를 가리킴
…
fputc(‘H’,streamfile) -> ‘H’ 출력 후 index 5를 가리킴

순차 접근 스트림 파일은 파일에 있는 모든 바이트를 처리하는 경우에 유용
<임의 접근 스트림 파일>
: 이전의 바이트를 접근하지 않고 직접 접근
임의 접근을 위한 함수
(fseek, ftell)




입력 순차 파일
1. 필드의 순서, 길이 등에 대해서 제한 없음 (원래라면 1열은 snumber, 2열은 sname으로 고정)
2. 레코드의 길이, 타입도 일정하지 않을 수 있음
3. 레코드<필드, 값> 쌍으로 구성

- 삽입 작업
레코드를 삽입하려면 항상 파일 끝에 첨가
- 검색 작업
파일 시작부터 비교해서 원하는 레코드 값을 검색
- 삭제,변경 작업
삭제할 내용을 빼고 나머지를 복사 및 새로 저장 (새로운 순차 파일을 생성하는 것)
Ex) 레코드가 10개 있는데 9를 삭제하려고 한다. -> 레코드1~8,10순서대로 저장
키 순차 파일
1. 저장 장치의 레코드 순서와 레코드 리스트의 논리적 순서가 같은 구조의 파일
2. 파일 내의 레코드들 : 키 필드 값에 따라 정렬 -> 학번을 기준으로 오름차순하면 됨
3. 데이터 필드가 딱 정해져 있으니 값만 저장하면 됨
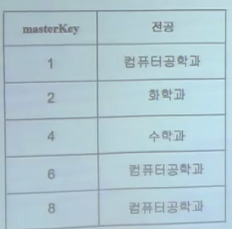
키 순차 파일의 문제점
오름차순을 무슨 필드로 하느냐에 따라 다르기 때문에 똑같을 파일을 n번 만들어야 된다.
- 학번으로 정렬, 이름 가나다 순으로 정렬, 등등
- ‘홍길동’ 학생이 전과를 함 -> 모든 파일에서 삭제를 해야 됨
- 일관성 유지, 보안 유지가 어려움 (다 삭제해야 되는데 하나 놓치면 문제가 발생함)
키 순차 파일의 특징
대화식 처리보다는 일괄 처리
예) 사원의 급여 명세서 작성
장점:
다음 레코드를 신속하게 접근 가능 (길이가 중구난방이 아니라 거의 비슷할 테니까),
접근 요구 순서가 저장된 레코드 순서와 같다면 접근 시간이 단축됨
(학번으로 정렬된 파일인데 학번으로 파일을 접근한다 -> 접근 시간이 빠르겠지)
-> 데이터의 접근 요구를 고려한 후 설계할 필요가 있음
설계 시 고려 사항
레코드 내의 필드 배치, 키 필드는 어떤 것, 블로킹 인수
레코드 내의 필드 배치
- 활동 파일과 비활동 파일을 구분하여 저장
Ex) 인사 파일에서 주된 내용은 활동 파일, 보조 내용은 비활동 파일로 나눔, 활동 파일 필드는 이름과 직위,부서를 필드로 사용, 비활동 파일에는 이름과 학벌,연봉을 필드로 사용 - 레코드의 고정 길이, 가변 길이를 고려해서 필드 배치
Ex) 만약 고정 길이로 한다면 메모리를 어떻게 쓰는지 파악 후 빈 공간이 적게 배치
키 필드는 응용 요건에 따라 선정
적정 블로킹 인수는 얼마이어야 하는가?
-> 가능한 한 블록을 크게 하는 것이 바람직함, 단 메인 메모리 내 버퍼 공간, 운영체제가 지원하는 블록 크기에 의해 제한 받을 수 있음
순차 파일의 생성
생성: 데이터 저장 장치에 레코드들을 순서대로 입력, 마스터 파일과 트랜잭션 파일(데이터 수정모음)을 이용해서 생성
편집: 트랙잭션 파일 생성 과정에서 데이터 값에 오류가 있는지 검사하고 수정
순차 파일의 질의 (순차 파일에 검색하는 것)
-> 파일 구조상 연속적인 검색의 경우에 효율적
Ex) 사원 봉급의 평균과 표준 편차는 얼마인가? // 연속적으로 다 접근해서 구하는 것
– 파일의 질의 적중 비율은? (파일에 검색했을 때 해당하는 레코드가 있는 비율은?)

Ex) 80명의 레코드가 있다. 출석부를 처음부터 끝까지 다 부른다. 전체 레코드는 80, 질의에 응답하기 위해 접근해야 할 레코드도 80 ->1-> 적중 비율이 높을수록 순차 파일 구조에 적합하다.
키 순차 파일의 갱신
1. 레코드 삽입
(1) 두 기존 레코드 사이에 삽입 위치를 검색
(2) 삽입점 앞에 있는 모든 레코드를 새로운 파일에 복사, 새 레코드 삽입
(3) 삽입점 뒤에 있는 모든 레코드를 새로운 파일에 복사
2. 레코드 수정, 삭제
-> 삽입과 거의 같은 과정
키 순차 마스터 파일의 갱신
갱신 트랜잭션은 트랜잭션 파일에 모아 일괄 처리
– 트랜잭션 파일의 트랜잭션들 <갱신할 때 필요한 레코드들을 저장하는 파일>
-> 마스터 파일과 똑같은 키로 정렬
-> 각 트랜잭션은 마스터 레코드와 키 값과 갱신 코드를 가지고 있음
– 마스터 파일에 적용하는 갱신
새 레코드의 삽입(I), 기존 레코드의 삭제(D), 기존 레코드의 수정(C)
파일의 연산을 크게 말하면 -> 생성,검색,삽입,삭제,수정
< 트랜잭션 코드(삭제할지 수정할지 삽입할지 나타내는 코드) >
* 트랜잭션의 삽입
트랜잭션 키 값은 반드시 있어야 함(삽입할 위치를 키 값으로 구분해야 됨), 다른 데이터 필드 값은 나중에 삽입 가능
* 트랜잭션의 삭제
마스터 레코드의 키 값만을 지정해도 됨
* 트랜잭션의 수정
트랜잭션 키 값과 수정될 필드들과 해당 값을 명세 (학번/이름/번호 중 번호 필드만 바꿀 경우)
// 수정하지 않을 필드는 공백으로 넣음
파일 갱신 프로그램
이미 저장된 레코드의 삽입, 저장되지 않은 레코드 삭제 혹은 수정 등 여러 가지 오류 고려해야 함
갱신 프로그램 역할:오류 보고서를 생성하여 수행하지 못한 모든 트랜잭션의 내용과 그 이유를 제시함
갱신 빈도수를 결정하는 요인
-> 변경율이 클수록 갱신 빈도수 증가
-> 파일의 크기가 클수록 갱신 빈도수 감소 (시간이 많이 걸리니까, 비용이 증가되므로 갱신 덜하게 설계함)
-> 최신 데이터 요구 클수록 빈도수 증가
-> 파일의 활동 비율이 클수록(삭제,삽입,수정이 클수록) 빈도수 증가
파일의 활동 비율

파일 활동 비율이 낮을수록 신마스터 파일로 단순히 복사하는 레코드 수가 증가 -> 갱신 빈도수 감소
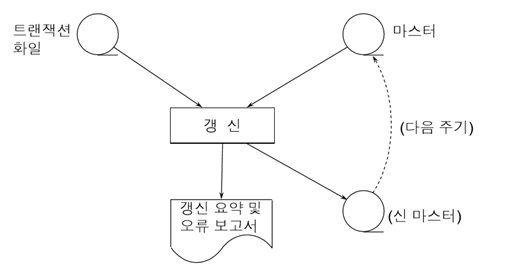
키 순차 마스터 파일의 갱신 알고리즘
(가정) 트랜잭션 파일과 순차 마스터 파일이 똑같은 키로 오름차순으로 정렬됨
(알고리즘)
어느 한 키 값이 두 파일에서 일치하면 갱신 프로그램은 갱신 코드에 따라 레코드를 수정,삭제
트랜잭션 레코드 키 값이 마스터 파일의 어떤 레코드의 것과도 일치하지 않으면, 새로 삽입할 레코드로 간주
(오류 처리)
마스터 파일에 있는 키 값을 가진 레코드를 삽입 (키 값이 일치하는데 삽입)
마스터 파일에 없는 키 값을 가진 레코드를 삭제,수정 (키 값이 없는데 삭제,수정)
* masterKey < transKey
(마스터 파일의 레코드 키 값은1, 트랜잭션 파일의 레코드 키 값은 2 -> 1수정 안 하므로 그냥 복사)
: 마스터 레코드에 적용할 트랜잭션 레코드가 없는 경우 (아무런 연산이 없다)
-> 그냥 마스터 레코드를 신 마스터 파일로 복사만 한다.
* masterKey = transKey
: 트랜잭션 레코드의 갱신코드에 따라 다르게 처리한다
-> 수정: 마스터 파일에서 해당 레코드를 변경하여 신 마스터 파일에 삽입
-> 삭제: 해당 마스터 레코드와 트랜잭션 레코드는 무시된다.
-> 삽입: 중복됐다는 오류 메시지 출력
* masterKey > transKey
(마스터 파일의 레코드 키 값은2, 트랜잭션 파일의 레코드 키 값은 1 -> 1레코드를 신 마스터 파일에 삽입)
: 트랜잭션 레코드와 일치하는 마스터 레코드가 없는 경우
-> 해당 트랜잭션 레코드는 삽입할 레코드이거나 오류
-> 삽입: 레코드를 구성해서 신 마스터 파일에 삽입
-> 이외(수정,삭제): 오류 메시지 출력
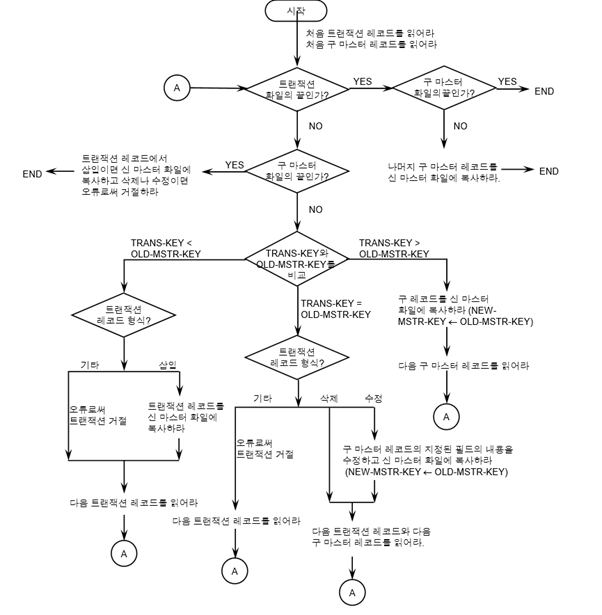
< 정리 >
* 키가 같으면 삭제나 수정 [두 파일 모두 처리]
* 키가 같은데 삽입일 경우 오류로 취급 [구 마스터 파일은 처리x, 트랜잭션 파일은 처리]
* 마스터 키가 작으면 연산 없음 (그냥 복사) [구 마스터 파일은 처리, 트랜잭션 파일은 처리x]
* 트랜잭션 키가 작으면 삽입 [구 마스터 파일은 처리x, 트랜잭션 파일은 처리]
* 트랜잭션 키가 작은데 삽입이 아닐 경우는 오류로 취급 [구 마스터 파일은 처리x, 트랜잭션 파일은 처리]
* 삭제할 경우, 구 마스터 파일에서 삭제하라는 의미가 아니라 다음 트랜잭션 레코드, 다음 구 마스터 레코드를 읽으라는 의미이다.
* 수정할 경우, 구 마스터 파일의 레코드 내용을 수정한 뒤 신 마스터 파일에 복사한다.
<알고리즘대로 수행해보기>
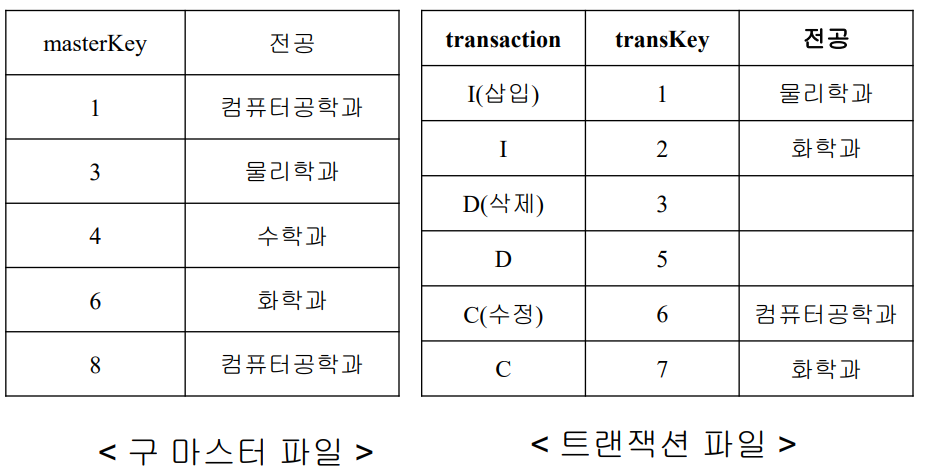
- 키가 같은데 삽입하라고 하니 오류 출력 // (1,1)
- 마스터 키가 더 작으니 (1 컴공) 그냥 복사 // (1,2)
- 트랜잭션 키가 더 작은데 삽입하라고 하니 (2 화학) 삽입 // (3,2)
- 키가 같은데 삭제하라고 하니 (3 물리) 삭제 // (3,3)
- 마스터 키가 더 작으니 (4 수학과) 그냥 복사 // (4,5)
- 트랜잭션 키가 더 작은데 삭제하라고 하니 오류 출력 // (6,5)
- 키가 같은데 수정하라고 하니 (6 컴공)으로 수정 // (6,6)
- 트랜잭션 키가 더 작은데 수정하라고 하니 오류 출력 // (8,7)
- 트랜잭션은 끝났는데 구 마스터 파일이 남아 있음 ->
구 마스터 파일에 남은 레코드 모두 복사 // (8,x)