
나이브 베이즈에 관한 포스팅:
https://shacoding.com/2019/12/07/mining-%eb%82%98%ec%9d%b4%eb%b8%8c-%eb%b2%a0%ec%9d%b4%ec%a6%88/
나이브 베이즈를 이용해서
SMS 스팸 분류를 해보겠습니다.
library(tidyverse)
library(caret)
library(tm)
library(extrafont)
library(dplyr)
library(gdata)
library(SnowballC)
library(wordcloud)
library(e1071)
# 햄과 스팸이 담긴 문서
sms_raw<-read.csv("sms_spam.csv",encoding="UTF-8")
table(sms_raw$type)
# ham, spam이 아닌 요소 번호 찾기
for(i in (1:length(sms_raw$type))){
if(sms_raw$type[i]!="spam" & sms_raw$type[i]!="ham"){
error<-i
break;
}
}
sms_raw<-sms_raw[-error,] # 에러 제거
sms_raw$type<-drop.levels(sms_raw$type) # 값이 0인 레벨 제거
table(sms_raw$type) # 오류 제거 확인
# 워드 클라우드 시각화
# 단어를 뽑아서 가장 많이 발생하는 단어를 가장 크고 가운데에 배치, 나머지는 작고 주위에
# 50번 이상 나온 단어들로 워드 클라우드 만들기
# random.order=FALSE이면 빈도에 따라 빈발 단어가 가운데 나옴
# 햄과 스팸을 워드 클라우드 시각화
ham<-subset(sms_raw,sms_raw$type=="ham")
spam<-subset(sms_raw,sms_raw$type=="spam")
wordcloud(ham$text,min.freq=50,random.order=FALSE)
wordcloud(spam$text,min.freq=50,random.order=FALSE)
# 코파스 (언어 모음을 만들어 놓은 것)
sms_corpus<-Corpus(VectorSource(sms_raw$text))
# 코파스로 만든 문서를 보려면
# as.character(corpus[[index]])를 이용한다.
as.character(sms_corpus[[1]])
# tm_map함수는 텍스트 변환하는 함수
sms_corpus_clean<-sms_corpus %>%
tm_map(content_transformer(tolower)) %>% # 소문자로 변경
tm_map(removeNumbers) %>% # 숫자 제거
tm_map(removeWords,stopwords(kind="en")) %>% # 불용어 제거
# 불용어: 의미없이 쓰이는 단어
tm_map(removePunctuation) %>% # 문장 기호 제거
tm_map(stripWhitespace) # 쓸데없는 공백 제거
as.character(sms_corpus_clean[[1]]) # 제거된 문장 보기
# 어근 찾기
# 예를 들어 learn,learned,learing,learns라고 하면 어근 learn을 찾음
sms_corpus_clean<-tm_map(sms_corpus_clean,stemDocument)
# checking -> check로 바껴서 나옴
as.character(sms_corpus_clean[[1]])
# 특정 단어가 해당 문서에서 나오면 1, 아니면 0으로 표시됨
sms_dtm<-DocumentTermMatrix(sms_corpus_clean)
# inspect함수를 이용해야 document가 보임
inspect(sms_dtm[1:30,1:30])
# 빈발 단어만 추리기
sms_freq_words<-findFreqTerms(sms_dtm,5)
str(sms_freq_words)
# 빈발단어로만 document 추출
sms_dtm_freq<-sms_dtm[,sms_freq_words]
# 추출해서 만든 행렬 행,열 개수 보기
dim(sms_dtm_freq)
dim(sms_dtm) #비교
# 0과 1로 보이는 것을 문자열로 보이게 하는 과정
convert_counts<-function(x){
x<-ifelse(x>0,1,0)
# 요소형을 정의할 때 labels옵션을 넣어주면 화면에서 보이는
# 문자열을 지정할 수 있음
x<-factor(x,levels=c(0,1),labels=c("Absent","Present"))
}
# 행 단위로 convert_counts함수를 적용
sms_dtm_convert<-apply(sms_dtm_freq,2,convert_counts)
# (native용) 훈련,테스트 데이터 만들기
train_index<-createDataPartition(sms_raw$type,p=0.75,list=FALSE)
sms_dtm_train<-sms_dtm_convert[train_index,]
sms_raw_train<-sms_raw[train_index,] # 답이 담긴 데이터
sms_dtm_test<-sms_dtm_convert[-train_index,]
sms_raw_test<-sms_raw[-train_index,] # 답이 담긴 데이터
m<-naiveBayes(sms_dtm_train,sms_raw_train$type)
p<-predict(m,sms_dtm_test,type="class")
table(sms_raw_test$type,p)
# 교차 검증
ctrl<-trainControl(method="cv",number=10,repeats=3)
sms_nb_mod<-train(sms_dtm_train,sms_raw_train$type,method="nb",trControl=ctrl)
sms_nb_mod
sms_nb_pred<-predict(sms_nb_mod,sms_dtm_test)
cm_nb<-confusionMatrix(sms_nb_pred,sms_raw_test$type,positive="spam")
cm_nb
결과)
0) sms_raw 확인
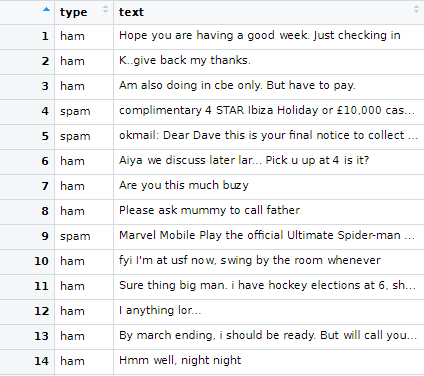
sms_raw$type에는 문자가 햄인지 스팸인지가 기재돼있습니다.
sms_raw$text에는 문자 내용이 기록돼있습니다.

그러나 파일 오류로 sms_raw$type에 이상한 데이터가 확인되었습니다.
그래서 전처리 작업으로 위 데이터를 삭제하였습니다.
# ham, spam이 아닌 요소 번호 찾기
for(i in (1:length(sms_raw$type))){
if(sms_raw$type[i]!="spam" & sms_raw$type[i]!="ham"){
error<-i
break;
}
}
sms_raw<-sms_raw[-error,] # 에러 제거
sms_raw$type<-drop.levels(sms_raw$type) # 값이 0인 레벨 제거
table(sms_raw$type) # 오류 제거 확인

값이 0인 레벨까지 지우고 나면 데이터 전처리가 완료됩니다.
1) 워드 클라우드로 스팸 문자 보기
# 워드 클라우드 시각화 # 단어를 뽑아서 가장 많이 발생하는 단어를 가장 크고 가운데에 배치, 나머지는 작고 주위에 # 50번 이상 나온 단어들로 워드 클라우드 만들기 # random.order=FALSE이면 빈도에 따라 빈발 단어가 가운데 나옴 # 햄과 스팸을 워드 클라우드 시각화 ham<-subset(sms_raw,sms_raw$type=="ham") spam<-subset(sms_raw,sms_raw$type=="spam") wordcloud(ham$text,min.freq=50,random.order=FALSE) wordcloud(spam$text,min.freq=50,random.order=FALSE) # max.words옵션을 주면 (시각화될 최대 단어수)를 정할 수 있음

스팸 문자에서 50번 이상 나온 단어들을 추려서 워드 클라우드를 만들었습니다.
워드 클라우드는 단어들을 시각화해놓은 것입니다.
2) sms_raw를 코파스로 만들기
# 코파스 (언어 모음을 만들어 놓은 것) sms_corpus<-Corpus(VectorSource(sms_raw$text)) # 코파스로 만든 문서를 보려면 # as.character(corpus[[index]])를 이용한다. as.character(sms_corpus[[1]])

메시지를 코파스 형태로 만드는게 우선입니다.
코파스는 쉽게 생각하면 언어 모음이고, 텍스트 관련 작업을 할 때 유용하게 쓰입니다.
코파스로 변경한다고 해서 메시지 내용이 변하지는 않습니다.
3) sms_corpus 텍스트 변환하기
# tm_map함수는 텍스트 변환하는 함수 sms_corpus_clean<-sms_corpus %>% tm_map(content_transformer(tolower)) %>% # 소문자로 변경 tm_map(removeNumbers) %>% # 숫자 제거 tm_map(removeWords,stopwords(kind="en")) %>% # 불용어 제거 # 불용어: 의미없이 쓰이는 단어 tm_map(removePunctuation) %>% # 문장 기호 제거 tm_map(stripWhitespace) # 쓸데없는 공백 제거 as.character(sms_corpus_clean[[1]]) # 제거된 문장 보기

tm_map은 텍스트를 변환해주는 함수입니다.
대문자를 소문자로 변경, 숫자 제거, 불용어 제거, 문장 기호 제거, 쓸데없는 공백 제거를 한 후
제거된 문장과 제거되지 않은 문장을 비교해보았습니다.
4) sms_corpus_clean 변환하기
# 어근 찾기 # 예를 들어 learn,learned,learing,learns라고 하면 어근 learn을 찾음 sms_corpus_clean<-tm_map(sms_corpus_clean,stemDocument) # checking -> check로 바껴서 나옴 as.character(sms_corpus_clean[[1]])
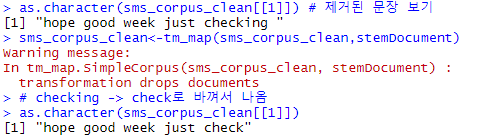
이전에 텍스트 변환된 문장은 sms_corpus_clean에 있습니다.
이를 다시 어근만으로 변환시켜서 sms_corpus_clean에 저장하였습나다.
어근만으로 변환해야 이전 포스트에 설명한 나이브 베이즈 형태를 구축할 수 있습니다.
5) 데이터 형태 변환하기
# 특정 단어가 해당 문서에서 나오면 1, 아니면 0으로 표시됨 sms_dtm<-DocumentTermMatrix(sms_corpus_clean) # inspect함수를 이용해야 document가 보임 View(inspect(sms_dtm[1:30,1:30])) # 빈발 단어만 추리기 sms_freq_words<-findFreqTerms(sms_dtm,5) str(sms_freq_words) # 빈발단어로만 document 추출 sms_dtm_freq<-sms_dtm[,sms_freq_words] # 추출해서 만든 행렬 행,열 개수 보기 dim(sms_dtm_freq) dim(sms_dtm) #비교
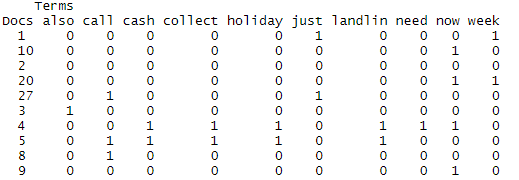
나이브 베이즈 모델은 위와 같은 형태의 데이터를 입력 데이터로 받습니다.
DocumentTermMatrix()함수를 이용해서 위와 같은 형태를 만들 수 있습니다.
sms_corpus_clean는 각 행마다 각 문자에 나오는 어근들을 담고 있습니다.
각 문자(행)에 대해 모든 어근을 조사할 때 어근이 있으면 1, 없으면 0을 저장합니다.
그렇게 모든 행에 대한 조사가 끝나면 sms_dtm에 저장합니다.
이후 findFreqTerms()함수를 이용해서 sms_dtm에 나오는 어근(열) 중 5회 이상이 나오는 어근(열)만 추렸습니다.
추려서 만들어진 데이터는 sms_dtm_freq에 저장됩니다.

빈발 어근을 추려서 저장한 후 / 추리기 전
6) 보이는 데이터 형태 변환하기
# 0과 1로 보이는 것을 문자열로 보이게 하는 과정
convert_counts<-function(x){
x<-ifelse(x>0,1,0)
# 요소형을 정의할 때 labels옵션을 넣어주면 화면에서 보이는
# 문자열을 지정할 수 있음
x<-factor(x,levels=c(0,1),labels=c("Absent","Present"))
}
# 행 단위로 convert_counts함수를 적용
sms_dtm_convert<-apply(sms_dtm_freq,2,convert_counts)
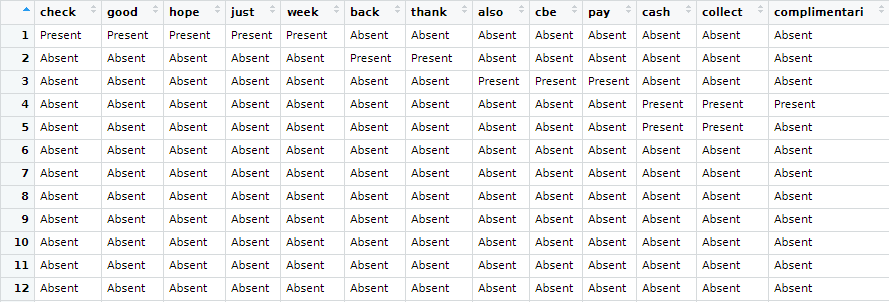
데이터가 0과 1로 처리되지만 보기에 0은 “Absent”, 1은 “Present”로 표기되도록 함수를 적용하였습니다.
7) 나이브 베이즈 모델 만들고 테스트
# (native용) 훈련,테스트 데이터 만들기 train_index<-createDataPartition(sms_raw$type,p=0.75,list=FALSE) sms_dtm_train<-sms_dtm_convert[train_index,] sms_raw_train<-sms_raw[train_index,] # 답이 담긴 데이터 sms_dtm_test<-sms_dtm_convert[-train_index,] sms_raw_test<-sms_raw[-train_index,] # 답이 담긴 데이터 # 훈련 데이터, 훈련 데이터의 답 m<-naiveBayes(sms_dtm_train,sms_raw_train$type)
sample함수를 이용하지 않고 createDataPartition함수를 이용해서 요소 넘버 중 75%를 추출했습니다.
이후 이 랜덤된 요소 넘버를 가지는 행을 모아 sms_dtm_trian(훈련 데이터)를 만들었습니다.
간단히 createDataPartition함수를 소개하겠습니다.
spam이 전체 중 1%라고 가정합시다.
sample함수로 75%를 추출하면 , train에 spam이 하나도 없고 test에 spam다 들어갈 수도 있습니다.
만약 train에도 spam이 1%, test에도 spam이 1%를 유지하려면 createDataPartition함수를 이용합니다.
naiveBayes함수로 나이브 베이즈 모델을 완성했습니다.
이제 모델을 만들었으니 시험을 봐보겠습니다.
p<-predict(m,sms_dtm_test,type="class") table(sms_raw_test$type,p)
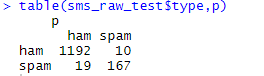
나이브 베이즈 분류를 할 때는 이전 포스트에서 설명한 ‘베이즈 정리’를 기반으로 합니다.
오답이 29니 꽤나 정확한 수치를 보입니다.
7) k-fold cross validation로 기계학습
# 교차 검증 ctrl<-trainControl(method="cv",number=10,repeats=3) sms_nb_mod<-train(sms_dtm_train,sms_raw_train$type,method="nb",trControl=ctrl) sms_nb_mod sms_nb_pred<-predict(sms_nb_mod,sms_dtm_test) cm_nb<-confusionMatrix(sms_nb_pred,sms_raw_test$type,positive="spam") cm_nb
훈련 데이터를 k(10)조각으로 쪼개고 k-1(9)조각은 모델을 훈련하는데 사용합니다.
나머지 한 조각은 validation으로 만들어서 만들어진 모델을 검증합니다.
이렇게 검증을 1회 하고 나면 다음에는 다른 조각을 validation으로 만들고 나머지 조각들로 모델을 훈련합니다.
이 과정을 k(10)번 반복합니다.
만들어진 k(10)개의 모델에서 최적의 오류를 기반으로 최적 모델을 찾습니다.
이후 최적 모델을 바탕으로 전체 training set(75%)의 학습을 진행합니다.
학습이 끝나면 test데이터(25%)로 학습 모델을 평가합니다.
교차 검증은 조각을 어떻게 나누느냐에 따라서 오차가 다르게 발생합니다.
그렇기 때문에 교차 검증을 repeats(3)번 반복 후 평균을 이용한 방법이 많이 쓰입니다.
k-fold에 대한 설명은 아래 링크에서 자세히 설명돼있습니다. (nonameyet님의 블로그)
: https://nonmeyet.tistory.com/entry/KFold-Cross-Validation%EA%B5%90%EC%B0%A8%EA%B2%80%EC%A6%9D-%EC%A0%95%EC%9D%98-%EB%B0%8F-%EC%84%A4%EB%AA%85
k를 10으로 만들고 반복을 교차 검증 반복을 3회 진행하였습니다.
모델이 총 30개나 만들어졌기 때문에 기존보다 더 좋은 정확도를 보일 것이라 예상됩니다.
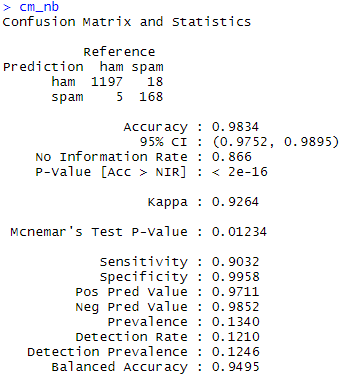
오차가 23으로 더 향상된 분류를 성공하였습니다!
지금까지 데이터 마이닝의 ‘나이브베이즈‘를 알아 보았습니다.