
클러스터링: 비슷한 데이터끼리 클러스터(그룹)를 만드는 것! , 군집화라고도 부름
SNS사이트를 크롤링해서 가져온 데이터 : 10대 시장 데이터
를 가지고 클러스터링을 해보겠습니다.
데이터 활용하게 많기에 ‘데이터 분석’도 같이 해보겠습니다!
각 인물들의 (졸업연도, 성별, 나이, 친구 수, 농구에 대한 이야기 수 등)을 수집한 것입니다.

R Script )
install.packages("dplyr")
library(dplyr)
setwd("C:/Users/oo/Desktop")
teens<-read.csv("snsdata.csv")
str(teens)
table(teens$gender)
# 결측치 폼함해서 집계
table(teens$gender,useNA="ifany")
summary(teens$age)
# 청소년의 제외한 데이터는 결측 처리
teens$age<-ifelse(teens$age>=13&teens$age<20,teens$age,NA)
summary(teens$age)
# 성별 데이터를 세 개의 더미변수로 만들기
# 더미변수는 0과 1값을 가지는 변수
teens$female<-ifelse(teens$gender=="F",1,0)
# 이렇게 변수를 만들고 여성 비율을 계산할 때 0.7이 나오면 여자가 70퍼
# 즉 이렇게 해야 수치 계산이 쉬워짐!
teens$male<-ifelse(teens$gender=="M",1,0)
teens$no_gender<-ifelse(is.na(teens$gender),1,0)
table(teens$female,useNA="ifany")
table(teens$male,useNA="ifany")
# -> 여전히 변수에 na가 나옴
# 이유: 값이 비어 있으면 테스트(ifelse문) 자체가 불가능함
table(teens$no_gender,useNA = "ifany")
# is.na함수를 이용해서 ifelse문을 활용했으므로 걸러짐
# 오류 안나오게 하기
teens$female<-ifelse(teens$gender =="F" & !is.na(teens$gender),1,0)
teens$male<-ifelse(teens$gender =="M" & !is.na(teens$gender),1,0)
# 더 이상 오류 안나오는거 확인
table(teens$female,useNA="ifany")
table(teens$male,useNA="ifany")
# 연령의 평균
mean(teens$age,na.rm=TRUE)
# 연령의 성별 분포
teens$age_fl<-floor(teens$age) # floor함수로 나이의 소수값을 없앤다.
table(teens$age_fl,teens$gender) # 분포를 구할 때 웬만하면 table함수로 해결된다
# 졸업 연도별로 평균 나이 구하기
# 졸업연도 데이터를 그룹짓고 이걸 평균 나이로 요약하기 ->
# 2006년 졸업 나이가 쭉 있으면 그 나이를 평균으로 구함 (2007,2008,2009도 동일)
teens %>% group_by(gradyear) %>% summarise(mean_age=mean(age,na.rm=T))
# aggregate(계산될 변수 ~기준 변수, 데이터, 함수, 함수 옵션)
aggregate(age~gradyear,teens,mean,na.rm=TRUE) # gradyear변수를 기준으로 age평균을 계산하고 요약하겠다.
# gradyear를 그룹으로 잡고(2006그룹,2007그룹...) 그룹 개수만큼 age 평균을 만듦
#ave는 그룹의 대표 값을 반환해주는 함수
#ave(그룹 대표 값을 구할 때 필요한 데이터, 그룹, 데이터를 받는 함수)
# x에는 첫 번째 인수가 들어감
# 왜 function을 이용하였는가?
# na.rm=true라는 옵션을 주기 위해서이다.
# 세 번째 인수에는 함수 이름만 쓰거나 함수를 정의해야만 하도록 설계되어있다.
# teens$gradyear에 대한 대표값: 졸업연도에 해당하는 나이의 평균
ave_age<-ave(teens$age,teens$gradyear,FUN=function(x) mean(x,na.rm=TRUE))
# teens$gradyear가 2006이면 2006년에 대한 teens$age의 평균을 구함
# teens$gradyear가 2007이면 2007년에 대한 teens$age의 평균을 구함
# 결과 예시) teens$gradyear=2006일 때의 대표값은 18이고 2007일 때의 대표값은 19이다!
# gradyear에 대한 age평균을 데이터 개수만큼 만듦
teens_age<-ifelse(is.na(teens$age),ave_age,teens$age)
# teens$age가 결측값이면 대표값을 쓰고 아니면 일반 값을 씀
# 데이터 프레임 5열부터 40열만 이용 <행과 열이 있는데 둘 중 하나만 쓴다면 열을 쓰겠다는 것>
interests<- teens[5:40]
#laaply를 써서 interests를 리스트로 만들고 scale함수를 써서 리스트별로 정규화
interests_z<-as.data.frame(lapply(interests,scale))
interests_z
set.seed(2345) # 난수 고정
# 5개의 클러스터로 구성 (결과는 리스트로 나옴)
teen_clusters<-kmeans(interests_z,5)
teen_clusters$size
teens$cluster<-teen_clusters$cluster
# teen_clusters$cluster은 데이터마다 어떤 클러스터인지를 나타내는 데이터 프레임!
# 처음 5행의 데이터만 살펴보기 (열은 두 번째 인수에 해당)
teens[1:5,c("cluster","gender","age","friends")]
# 각 클러스터별로 연령 평균 구하기
aggregate(age~cluster,teens,mean)
# 각 클러스터별로 여성의 비율 구하기
aggregate(female~cluster,teens,mean)
# 각 클러스별로 친구 수 구하기
aggregate(friends~cluster,teens,mean)
# 클러스터별 비중이 높은 단어를 표기하기!!
# teen_clusters$centers는 각 클러스터들 센터 데이터의 모음
class(teen_clusters$centers)
# 위 행렬의 각 행(1)을 내림차순으로 조정해서 a행렬을 만듦
a<-apply(-teen_clusters$centers,1,order) # 행렬에 함수 적용해서 행렬 반환하는 함수
a
# a행렬은 36행 5열로 구성되고 내림차순 결과는 teen_clusters$centers의 인덱스로 저장됨
# a행렬 1열은 teen_clusters$centers 1행을 내림차순한 인덱스 결과!
# 즉 teens_clusters$centers[a[1,1]]은 teen_clusters$centers 1행에서 가장 큰 값을 가짐
# 마찬가지로 teens_clusters$centers[a[2,1]]은 teen_clusters$centers 1행에서 두 번째 큰 값을 가짐
# 하지만 값이 필요한게 아니라 그 값에 대한 열 이름이 필요하므로 colnames함수를 사용함!
result <-NULL
for(i in 1:5){
result<-cbind(result,colnames(teen_clusters$centers)[a[,i]])
}
result
결과 )
1) 여성과 남성의 수 구하기
: 여성은 F, 남성은 M으로 나왔기 때문에
teens$female<-ifelse(teens$gender ==”F” & !is.na(teens$gender),1,0)
teens$male<-ifelse(teens$gender ==”M” & !is.na(teens$gender),1,0)
를 사용해서 여성 변수, 남성 변수를 만들었습니다.
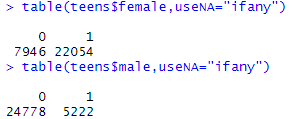
teens$female은 0과 1로 이루어져있고 1에 해당하는 숫자만큼 여자입니다.
teens$male도 0과 1로 이루어져있고 1에 해당하는 숫자만큼 남자입니다.
이처럼 0과 1로만 구성된 변수를 더미변수라고 합니다.
2) 연령의 평균 구하기

3) 연령별 성별 분포 구하기

4) 졸업연도별로 평균 나이를 구하기

5) 연령 결측치 처리하기
: NA값을 (졸업연도에 해당하는 나이 간 평균)으로 수정합니다!
[ 원리는 주석 설명을 참조 ]
ave_age<-ave(teens$age,teens$gradyear,FUN=function(x) mean(x,na.rm=TRUE))
teens_age<-ifelse(is.na(teens$age),ave_age,teens$age)

->
6) 클러스터링 하기 전에 정규화하기!
정규화를 해야 되는 이유는 유클리드 알고리즘이 오류를 범할 수 있기 때문입니다!
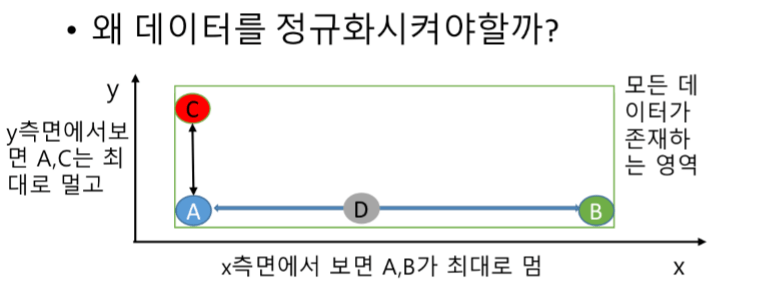
위 사진을 보면 C는 Y축 끝에 있고, D는 고작 X축 가운데 위치하지만
공식대로 풀면, A<->C 간의 거리보다 A<->D간의 거리가 더 멀게 값이 나옵니다.
이를 정규화해서
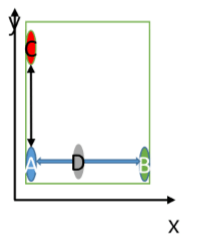
위와 같은 모양으로 만들면 정상적으로 거리를 구할 수 있습니다!
고로 클러스터링을 하기 전에는 정규화를 하는 것이 우선입니다!
# laaply를 써서 interests를 리스트로 만들고 scale함수를 써서 리스트별로 정규화
interests_z<-as.data.frame(lapply(interests,scale))
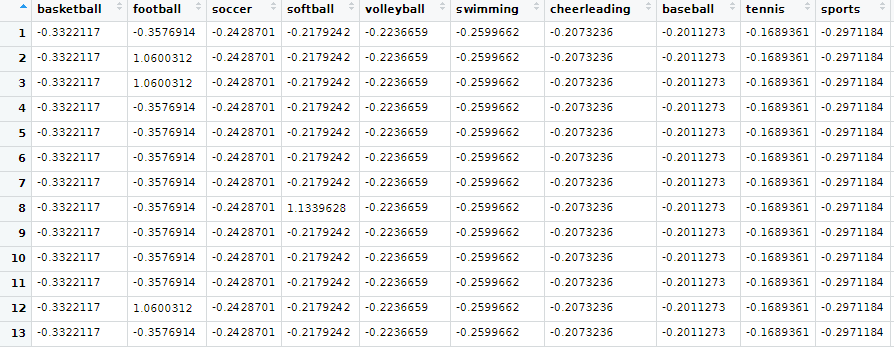
7) 5개의 그룹으로 클러스터링 하기
: teen_clusters<-kmeans(interests_z,5)
teens$cluster<-teen_clusters$cluster
# teen_clusters$cluster은 데이터마다 어떤 클러스터인지를 나타내는 데이터 프레임!

8) teens 데이터 [1행에서 5행] 원하는 열만 보기

9) 각 클러스터별로 연령 평균 구하기

10) 각 클러스터별로 여성의 비율 구하기
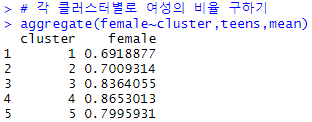
11) 각 클러스터별로 친구 수 구하기

12) 클러스터별 비중이 높은 단어의 수 구하기
teen_clusters$centers는 클러스터들 각 센터가 가지는 데이터 모음
1행 – 그룹1 센터의 데이터, 2행- 그룹 2센터의 데이터…

teen_clusters$centers 1행에서 basketball이 가장 값이 크다.
이 문장의 의미는 그룹1에 있는 아이템들(10대들)은 basketball을 가장 많이 이야기했다는 것입니다.
센터와 그룹 내 데이터는 비슷한 수치를 가지고 있기 때문에 위처럼 해석됩니다.
a<-apply(-teen_clusters$centers,1,order)
result <-NULL
for(i in 1:5){
result<-cbind(result,colnames(teen_clusters$centers)[a[,i]])
}
result

그룹1은 운동을 좋아는 것 같고, 그룹2는 활발한 그룹인 듯 하고, 그룹5는 자극적인 것을 좋아하는 그룹으로
추정할 수 있습니다!
지금까지 ‘클러스터링 실습’을 해보았습니다!