
연관분석에 관한 포스팅:
https://shacoding.com/2019/10/19/mining%ec%97%b0%ea%b4%80%eb%b6%84%ec%84%9d/
연관분석을 이용해서
타이타닉호 사고 중 사망률이 가장 높았던 사람들은 어떤 사람들인지 알아 보겠습니다.
R Script )
Titanic
# 4차원 테이블 형태
class(Titanic)
# 테이블을 데이터프레임으로 평평하게 만듦
# 이제 4차원 테이블처럼 보이지 않음
titan.df<-as.data.frame(Titanic)
head(titan.df)
# freq제외 열(1열~4열) 데이터를 각각 freq개 나열
# [모든 행에 대한 i(1->4)열]데이터를 freq개 나열
# 1행 1열을 freq개 나열 ~ n행 4열을 freq개 나열
titanic<-NULL # titanic은 만들 행렬을 의미!
for(i in 1:4){titanic<-cbind(
titanic,rep(as.character(titan.df[,i]),titan.df$Freq)
)}
titanic
class(titanic) # 현재 행렬 상태
titanic<-as.data.frame(titanic) # 데이터 처리하기 위해 데이터 프레임으로 바꿈
titanic
names(titanic)<-names(titan.df)[1:4]
titanic
myrules<-apriori(data=titanic,parameter=list(support=0.01,confidence=0.25,minlen=2))
inspect(myrules)
# 결과 중에 오른쪽 아이템 집합에 생존여부가 들어있는 부분을 살펴봄
s <-subset(myrules,rhs %in% "Survived=No")
inspect(s)
결과)
0) 기존 타이타닉 데이터
Titanic

1) 타이타닉 데이터를 데이터 프레임 형태로 바꿈
titan.df <- as.data.frame(titanic)
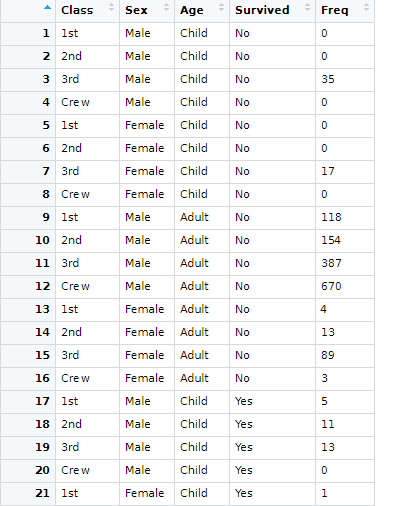
해석)
1st클래스 남성 아이가 죽었다의 데이터는 0번이다. -> 모두 다 생존했다.
3rd클래스 남성 아이가 죽었다는 데이터는 35번이다. -> 35명이 사망했다.
3rd클래스 남성 아이가 살았다는 데이터는 13번이다. -> 13명이 생존했다.
3) 연관성 측정을 하기 위한 형태로 데이터 프레임을 만듦
titanic <-null
for(i in 1:4){
cbind(titanic, rep(titan.df[,i], titan.df$Freq))
}
titanic <- as.data.frame(titanic)
=> 아래처럼 만들어야 (아이템 집합이 무수히 많은 형태로 만들어야)
apriori가 {3rd, male,child,no}에 대한 지지도/신뢰도/향상도를 구할 수 있음!

ex) 기존 프레임 3행 – 1열 3행)3rd는 freq가 35개이니 -> 3rd 3rd 3rd …
기존 프레임 3행 – 2열 3행) male은 freq가 35개이니 -> male male male…
cbind로 합쳐 놓고 데이터 프레임으로 변환!
4) apriori 알고리즘으로 연관분석을 실시!
apriori(data=titanic, parameter=list(support=0.01, confidence=0.25, minlen=2))

5) subset함수를 이용해서 데이터 가공
subset(myrules,rhs %in% “Survived=No”)
=> myrules데이터에서 rhs열에 있는 “Survived=No” 데이터만 가져옴!
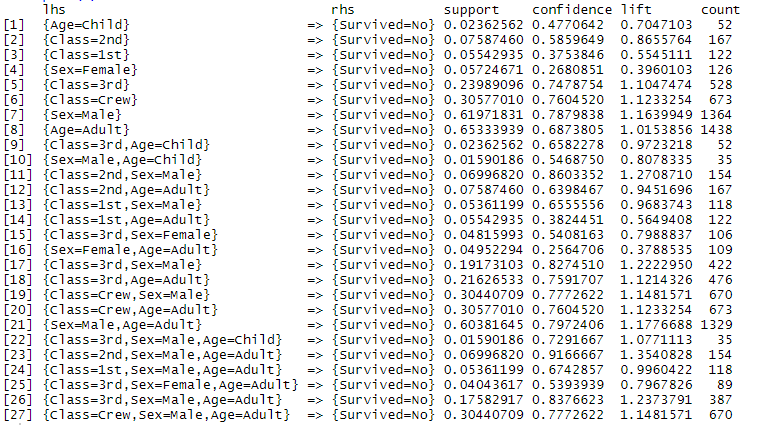
A->B에 대한 신뢰도(confidence)는 A가 일어났을 때 B가 일어날 비율로
B는 여기서 ‘사망’을 의미!
[1] {age=child} => {survived=No} confidence: 0.477
: 아이면서 사망한 비율은 47%
위 데이터에서 신뢰도가 가장 높은 [23]이 가장 사망율이 높음
=> 클래스가 2nd고 성인 남성이 가장 사망율이 높음!