
컴퓨터 비전이나 머신러닝 모델을 다루다 보면 반드시 마주치는 평가 지표가 있습니다. 바로 AP(Average Precision)입니다. 단순히 ‘정확도’만 보면 될 것 같은데, 왜 복잡하게 AP라는 지표를 사용할까요?
이번 글에서는 모델 출력의 기초부터 AP가 중요한 이유, 계산 방식, 그리고 자주 헷갈리는 AUC와의 차이점까지 명확하게 정리해 보겠습니다.
1. 모델은 어떻게 결과를 출력할까?
먼저 평가 지표를 이해하기 전에 모델이 어떤 형태로 결과를 내놓는지 알아야 합니다.
- 다중 출력: 모델은 일반적으로 여러 개의 ‘예측(Prediction)’과 그에 대한 ‘컨피던스 스코어(Confidence Score, 확신도)’를 함께 출력합니다.
- 태스크별 예측 형태: 예측의 형태는 해결하려는 문제에 따라 다릅니다. (예: 객체 탐지에서는 ‘바운딩 박스’, Moment 검색에서는 ‘특정 구간’)
- 학습의 목표: 모델이 높은 컨피던스를 부여한 예측일수록 실제 정답(Ground Truth)에 가까워야 ‘학습이 잘 된 모델’이라고 할 수 있습니다.
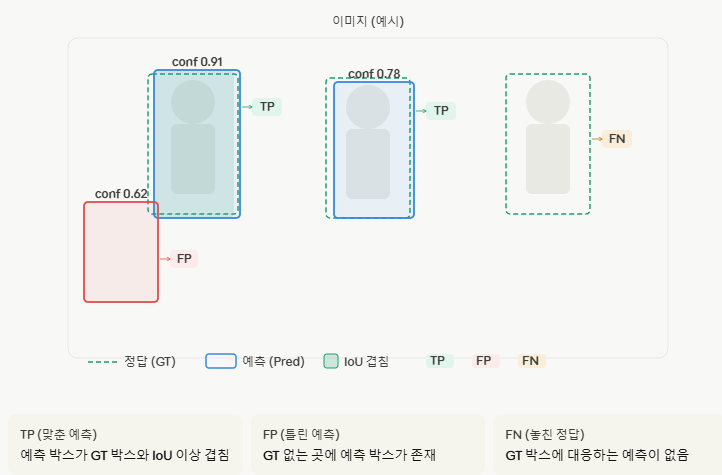
1) 객체 탐지 (Object Detection)
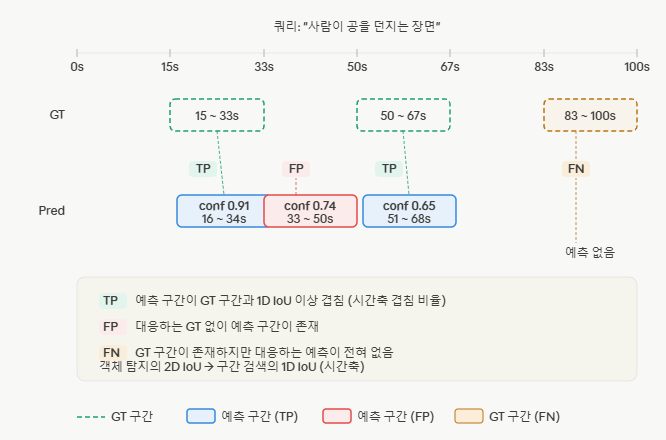
2) 비디오 구간 검색 (Moment Retrieval)
2. AP(Average Precision)가 중요한 이유
단순히 맞고 틀린 것만 세면 안 될까요? 왜 AP가 필요할까요? 모델의 ‘확신(Confidence)’과 실제 ‘정확도’ 사이의 관계를 보면 그 이유를 알 수 있습니다.
❌ 나쁜 모델의 예시
- 확신이 없는 모델: 전반적으로 컨피던스가 낮고, 정답과 오답의 점수가 섞여 있습니다. 어떤 예측을 믿어야 할지 판단할 수 없어 신뢰성이 떨어집니다.
- 근자감(확신은 있는데 오답) 모델: 컨피던스가 높은 예측을 믿고 썼는데 틀린 경우가 많습니다. 모델을 믿을수록 손해를 보므로 실전에서 운용할 수 없습니다.
즉, “컨피던스가 높은 순서가 실제 정확도가 높은 순서와 일치하는가?”를 측정해야 실전에서 써먹을 수 있는 모델인지 알 수 있습니다.
AP는 단순한 정확도 지표가 아니라, 바로 이 컨피던스 랭킹의 품질을 평가하는 지표입니다. 모델이 “나 이거 확실해!”라고 한 것이 진짜 얼마나 정확한지 측정하는 것이죠.
3. AP는 어떻게 계산될까?
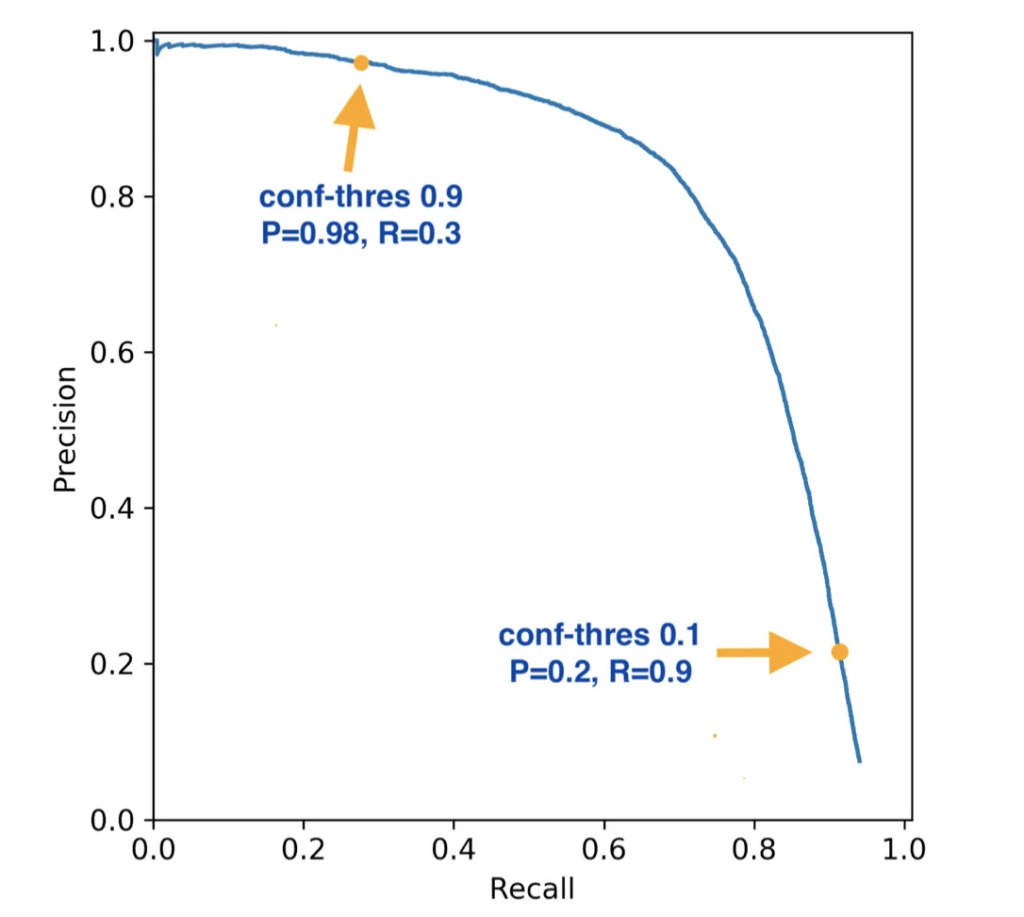
AP를 계산하기 위해서는 임계치(Threshold)를 조절하며 성능의 변화를 관찰해야 합니다.
- 정답의 기준 (IoU): 예측된 결과와 실제 정답의 겹치는 비율(IoU)이 일정 수치를 넘어야 ‘정답’으로 인정합니다.
- 예측의 기준 (Confidence): 컨피던스 스코어가 특정 임계치를 넘어야만 유효한 ‘예측’으로 취급합니다.
TP: 맞춘 예측 /FP: 틀린 예측 /FN: 놓친 정답 /TN: 존재하지 않음 (객체 탐지 등에서는 보통 정의되지 않음)
- 임계치 변화 (Sweep): 컨피던스 임계치를
1에서0으로 서서히 낮추면서 Precision(정밀도)과 Recall(재현율)을 반복해서 계산합니다. - AP 산출: 이렇게 계산된 Precision-Recall(PR) 커브의 아래쪽 면적(AUC, Area Under Curve)을 구한 값이 바로 AP입니다.
4. 잘 학습된 모델의 특징과 임계치 강건성
임계치를 변화시킬 때, 좋은 모델은 다음과 같은 이상적인 흐름을 보이며 AP 값이 1에 수렴합니다.
- 매우 높은 임계치: 확실한 것만 예측하므로 Precision은 높지만, 놓치는 정답이 많아 Recall은 낮습니다.
- 적당히 높은 임계치: Precision과 Recall이 모두 높은 이상적인 상태를 유지합니다.
- 임계치가 낮아질수록: 아무거나 다 예측하므로 정답을 맞출 확률(Recall)은 오르지만, 오답도 많아져 Precision은 떨어집니다.
💡 임계치 강건성(Robustness)과 일반화
AP가 높은 모델은 아주 좁은 특정 임계치에서만 성능이 좋은 게 아니라, 넓은 임계치 구간에서 안정적으로 높은 성능을 보입니다. 이런 모델은 사용자가 임계치를 억지로 끼워 맞출(Cherry-pick) 필요가 없기 때문에 ‘일반화 관점’에서 매우 우수하다고 평가받습니다.
두 명의 개발자가 만든 스팸 차단 모델 A와 B가 있다고 가정해 봅시다.
- 모델 A (강건하지 못함):
- 임계치를 정확히 0.87로 맞췄을 때만 스팸을 기가 막히게 잡아냅니다.
- 하지만 임계치를 0.85로 살짝만 낮춰도 중요한 업무 메일까지 스팸으로 분류해 버리고, 0.89로 높이면 스팸이 폭주합니다.
- 👉 문제점: 데이터가 조금만 변해도 성능이 널뛰기 때문에, 운영자가 매일 임계치를 미세하게 조정(Cherry-pick)하느라 고생해야 합니다.
- 모델 B (강건함 – AP가 높음):
- 임계치를 0.7로 두든 0.9로 두든 스팸 차단 성능이 안정적으로 유지됩니다.
- 확실한 스팸에는 아주 높은 점수를, 일반 메일에는 아주 낮은 점수를 안정적으로 부여하기 때문입니다.
- 👉 장점: 어떤 환경에서도 믿고 쓸 수 있으며, 사용자가 복잡하게 설정을 만질 필요가 없는 ‘일반화 능력이 우수한’ 모델입니다.
5. AP vs AUC, 언제 무엇을 써야 할까?
가장 많이 헷갈리는 두 지표, AP(PR 커브의 밑면적)와 AUC(ROC 커브의 밑면적)는 어떤 차이가 있을까요?
AUC는 모델이 Positive와 Negative를 얼마나 잘 분리하는지(TPR vs FPR)를 평가합니다.
태스크별 지표 선택 가이드
1) 객체 탐지 / Moment 검색
- 이러한 태스크는 ‘배경(정답이 없는 곳)’이 무한하기 때문에 TN(True Negative) 자체를 정의하기 어렵습니다.
- TN이 없으면 FPR(False Positive Rate) 계산이 불가능해 ROC 커브를 그릴 수 없습니다.
- 👉 따라서 무조건 AP를 사용합니다.
2) 이진 분류 (Binary Classification)
클래스의 비율에 따라 선택이 달라집니다.
| 비교 항목 | AP (Average Precision) | AUC (ROC AUC) |
| 특징 | Precision과 Recall만 사용 | TPR과 FPR 사용 (TN의 영향을 받음) |
| 클래스 불균형 | TN의 영향을 받지 않아 정직한 평가 가능 | TN이 많으면 FPR이 작아져 성능이 부풀려질 수 있음 |
| 클래스 균형 | – | P와 N의 전체적인 분리도를 직관적으로 평가하기 좋음 |
📌 결론 요약
두 지표는 우열을 가릴 수 없으며 상황에 맞게 써야 합니다.
- AUC 추천: 클래스가 균형 잡혀 있거나, FP(오탐지)를 줄이는 것이 전체적으로 중요한 일반적인 분류 문제
- AP 추천: 객체를 탐지하거나, 불량품 찾기 등 클래스 불균형이 심한 상황(Negative가 압도적으로 많은 경우)