
파일 저장 장치의 특성 / 저장 장치의 계층
저장 장치: 저장 매체 + 접근 장치
* 저장 매체: 데이터를 저장하는 물리적 재료
소멸성vs비소멸성 / 소멸성: 전원이 꺼지면 지워짐
* 접근 장치: 데이터를 판독하거나 기록하는 장치
– 1차 저장 장치
메인 메모리- 프로그램,데이터를 처리하기 위한 작업 공간 / 내용을 접근하는 시간이 일정하고 빠름
캐시 메모리- 메인 메모리보다 더 좋은 성능을 목적으로 함 (데이터를 빨리 접근해서 읽고 씀)
<메인 메모리보다 빠르지만 가격이 비쌈>
– 2차 저장 장치
자기 디스크: 용량이 커서 더 많은 데이터를 저장할 수 있는 장치 / 메인 메모리보다 10^5배 느림 / 저장된 데이터는 메인 메모리를 거쳐 CPU에 의해 처리
광 디스크, 자기테이프
< 1차 저장 장치>
– 캐시 메모리
가장 빠르고 가장 비싼 저장장치,
저장 매체: SRAM,
CPU 성능을 증진하기 위해 사용(CPU가 데이터를 빨리 빨리 처리할 수 있게 도와줌-> 같은 시간에 CPU가 일을 더 할 수 있음),
소멸성
– 메인 메모리
프로그램 실행에 필요한 데이터 유지 공간,
저장 매체: DRAM,
소멸성
– 플래시 메모리
EEPROM 전기적으로 데이터를 지우고 다시 기록할 수 있는 비휘발성 메모리(전기 공급 안 해도 데이터 유지)
<종류>
NAND형: NOR형에 비해 저장용량이 큼, 삼성전자가 주도
NOR형: NAND형에 비해 읽기 속도가 빠르나 쓰기 속도가 느림, 인텔이 주도
/ 디지털카메라,스마트폰,USB로 쓰이는 것
<2차 저장 장치>
– 자기 디스크
데이터 저장 장치의 주 매체, 데이터 처리와 기록은 메인 메모리를 거쳐야 함
– 광 디스크(CD)
광학적으로 저장, 레이저로 판독,용량과 보존 기간이 길다
– 자기 테이프
데이터의 백업과 보존을 위한 저장매체, 대용량의 데이터를 저장, 속도 느림
< 자기 디스크 Magnetic Disk >
직접 접근 저장 장치
종류: 하드디스크와 플로피디스크
분류 기준:
헤드 이동 시간,
회전 지연 시간(필요한 데이터가 헤드까지 올 시간) ,
밀도(섹터의 첫 부분과 끝 부분의 데이터 용량은 같다. 첫 부분은 좁지만 밀도가 크다[더 조밀하게 데이터가 있음]) ,
회전 속도
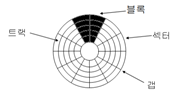
섹터: 기록과 판독 작업의 최소 단위
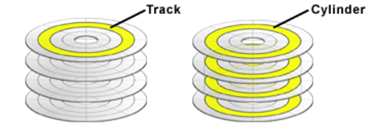
트랙: 갭으로 분리된 섹터들로 구성
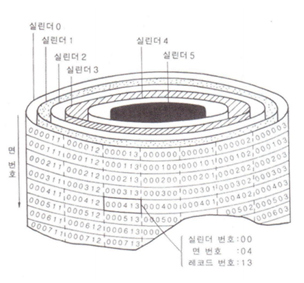
실린더: 지름이 같은 트랙 전체
블록: 디스크와 메인 메모리 간 전송되는 데이터의 논리적인 단위 <한 섹터 이상>
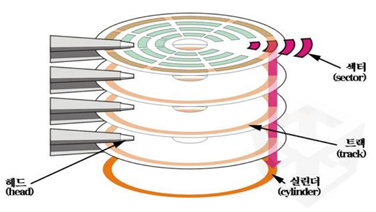
<유동 헤드 디스크>
: 헤드가 원하는 트랙에 이동하도록 액세스 암을 이동
데이터 전송 연산 시간: 탐구시간+회전지연시간+전송시간
탐구시간: 헤드가 몇 번째 실린지인지 찾는 시간
회전지연시간: 헤드가 필요한 데이터를 찾는 시간
(시계방향으로 도니까 b를 더 빨리 찾음)
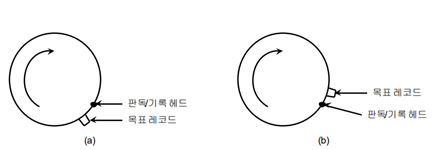
전송시간: 메인 메모리로 보내는 시간
/ 탐구시간 > 회전지연시간 이므로 탐구 시간을 줄여야 성능이 좋음
<고정 헤드 디스크>
: 헤드가 회전하지 않는 대신 많음
데이터 전송 연산 시간: 회전지연시간+전송시간
(유동 헤드 디스크의 10배 이상 빠름)
디스크 저장 장치의 특성
– 회전 속도
5400rpm<1분에 5400번 돌음>(1회전당 11ms) / 60:5400 = x:1 -> x는 0.011s -> 11ms
– 원반 수
5개의 원반 (앞뒤 10개의 면)
– 트랙 수
20000개 (한 트랙당 100만 바이트)
블록: 데이터 전송의 단위 (물리적 레코드:한 줄이 논리적 레코드라면, 임의의 설정한 n줄은 물리적 레코드)
트랙 길이 = 트랙에 있는 블록 수 * 블록 사이즈(길이)
블록 크기: 512kb,1kb,4kb(하나의 레코드가 100바이트라면, 1kb이면 10개의 레코드를 한 블록으로 구성한다는 뜻)
크기가 작으면? : 판독을 많이 해야 됨 (횟수가 많아짐)
크기가 많으면? : 불필요한 데이터 전송 / 메모리에 과도한 버퍼 공간 요구
[ 레코드가 모여 -> 블록이 모여 -> 파일 ]
[ <물리적> 섹터가 모여 -> 블록이 모여 -> 트랙이 모여 -> 실린더 ]
블록의 판독
1. 블록이 위치하는 트랙이 포함된 실린더에 헤더가 위치 (실린더 번호 찾기)
2. 디스크가 회전하면서 블록이 포함된 섹터들을 헤더가 인식,판독 (레코드 찾기)
– 평균 탐구 시간
실린더 번호 찾는 시간, 한 파일이 몇 개의 인접한 실린더에 기록되면 헤드 평균 이동은 줄어듦
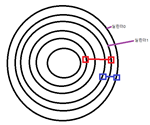
– 회전 지연 시간
레코드 찾는 시간, r= 1/2 * 1회전 시간 <평균적으로 구한거>
Q. rpm=3600일 때 (1분에 3600번돌 때=3600회전 시간이 60초), 디스크에서 r은 몇 ms인가?
A. 60:3600 = x:1 -> x(1회전 시간)=0.01667s = 16.67ms -> r=1/2*16.67=8.33ms
– 전송 시간
메인 메모리 보내는 시간 (블록의 섹터들과 갭들이 헤드 밑을 회전하여 통과하는데 걸리는 시간)
(평균 탐구 시간 > 평균 회전지연 시간 > 평균 전송시간)
-> 같은 실린더에 되도록 저장해야 판독 시간이 짧아진다
– 전송률
bts 단위 이용 / 1초 당 몇 바이트 전송하는가
블록의 기록과 갱신
블록의 기록: 판독(읽기)하는 대신 기록(쓰기)를 할 뿐 판독 과정과 동일
블록의 갱신: 메인 메모리로 블록 이동 -> 메인 메모리 내의 블록 사본을 갱신 -> 갱신된 블록 사본을 디스크에 기록
(자기디스크 내에서는 삭제가 불가능함)
블록 갱신 지연 시간: 블록 판독 시간 + 블록 사본 갱신 시간 + 블록 기록 시간
<메인 메모리에서 블록 사본 갱신하는 시간은 보통 무시>
-> 위의 지연 시간은 정해져 있으니 디스크 입출력의 횟수를 줄이는게 중요하다!
블로킹
블록 만들기, 몇 개의 논리적 레코드를 하나의 물리적 레코드(블록)에 저장시키는 것
블로킹 장점: I/O의 시간 감소, (갭으로 인한 기억 공간의 낭비 감소)
블로킹 단점: 버퍼 많이 사용함, 블록의 일부만 처리하는데 전체를 전송
블로킹 인수: 하나의 블럭에 담은 레코드 수
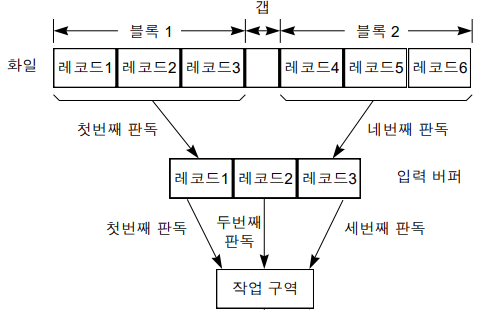
레코드 3개를 하나의 블록으로 블로킹 -> 디스크에서 메모리로 가는데 한 번에 판독이 됨
(물론 메모리에서 CPU로 가는데는 세 번 걸리긴 함)
IF) 블로킹을 안 했다면 디스크에서 메모리로 가는데 3번의 판독을 해야 됨
<블로킹 방법>
- 고정 길이 블로킹
- 신장된 가변 길이 블로킹 (블록의 길이가 다름)
- 비 신장된 가변 길이 블로킹
(신장:하나의 레코드를 여러 블록에 저장)
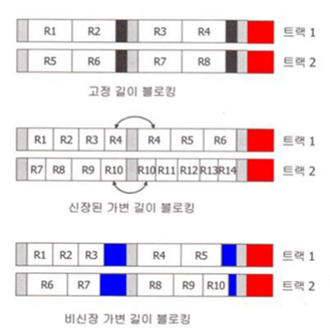
고정 길이 블로킹 -> 길이가 고정돼있어서 저장 공간이 낭비가 부분 부분 생김
신장 가변 블로킹 -> 저장 공간 낭비가 적지만 처리하기 어려움
비 신장 가변 블로킹 -> 신장 가변보다는 저장 낭비가 심함
고정 길이 블로킹은 길이만 알면 레코드 구분 가능
가변 길이 블로킹은 분리 표시가 필요함 or 각 레코드 앞에 길이 지시자
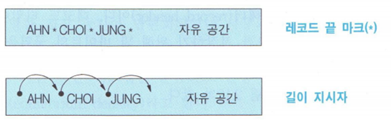
블로킹의 고려사항
적재 밀도: 실제 데이터 저장 공간/총 공간(실제 데이터 저장 공간+자유공간(여유공간))
적재 밀도 낮을(자유공간 많음)때 장단점?
장점: 디스크 추가 접근없이 데이터 삽입 가능성이 높아짐
단점: 같은 수의 레코드를 판독하기 위해 많은 블록을 읽어야 함
(실제 데이터가 30, 총 공간이 100인 블록 세 개가 있다. 근데 90개의 데이터를 찾아야 한다. -> 세 개의 블록을 뒤져야 한다)
균형 밀도: 시스템을 운용하고 안정된 뒤에 예상되는 저장 밀도
집약성: 레코드들의 근접성
-> 같은 실린더에 있으면 묶기도 좋다

필드에 대한 정보가 다 레코드 헤더에 저장됨 ]
< 자기 테이프 >

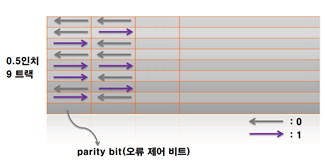
세로 한 줄에 1바이트 (00101101), parity bit(오류 체크 비트:데이터가 짝수개여야 되는데 홀수개다 ->check)
(1600bpi) -> 한 줄에 1바이트니 1인치에 1600바이트라고 생각!
(6250bpi) -> 한 줄에 1바이트니 1인치에 6250바이트라고 생각!
데이터 판독: 코일에 전류를 유도하여 판독
데이터 기록: 충전된 코일에 의해서 함
자기 테이프의 블록
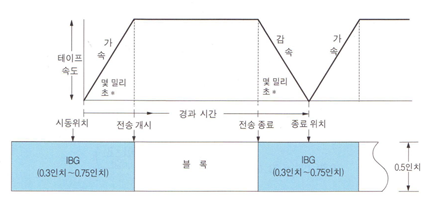
테이프의 소요 길이
<non blocking: 하나의 레코드가 하나의 블록>
Q. 100byte 레코드가 240000개일 때 몇 인치 필요? (6250bpi)
-> 1:6250=x:100(블록의 사이즈)*24000(블록의 개수) -> 384인치
-> IBG:0.3(하나의 IBG크기)*24000(갭의 개수)=7200인치
-> 갭에 대한 낭비가 너무 심하다
<blocking factor =5: 다섯 개의 레코드가 하나의 블록>
-> 1:6250=x:500(블록의 사이즈)*24000/5(블록의 개수) -> 384 인치
-> IBG: 0.3*24000/5 = 1440인치
->갭의 사이즈는 확 작아진다 -> 저장공간(1440+384)도 줄어든다.
Q. 6250 bpi 테이프에 300바이트 크기의 레코드를 20000개 기록시킨다고 하자. 단, 갭은 0.5인치라고 가정한다.
- 블로킹을 하지 않을 때, 테이프 길이를 구하시오
- 블로킹 인수를 10이라고 하는 경우, 테이프 길이를 구하시오
(10개의 레코드가 한 블록, 원래 한 블록은 300)
- 1(인치):6250(바이트) = x:300*20000 -> 960인치, 0.5*20000=10000 -> 10960인치
- 1:6250=x:3000*20000/10 -> 960인치, 0.5*20000/10=1000 ->1960인치
입출력 속도
기록/판독 속도=200ips(인치/초), 100바이트 24000개
갭 통해 출발 및 정지에 걸리는 시간=0.15초 (하나의 갭을 지나는 시간)
<non-blocking>
1(초):200(인치) = x:100/6250(인치) *24000(블록의 개수)
// 6250바이트가 1인치이니100바이트는 100/6250인치임
X(데이터 이동하는데 걸리는 시간)+{24000(갭의 개수)*0.15(하나의 갭을 지나는 시간)}=3601.92초
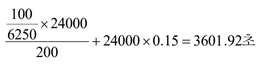
<blocking factor =5: 다섯 개의 레코드가 하나의 블록>
-> 마찬가지로 갭의 시간만 변동됨!
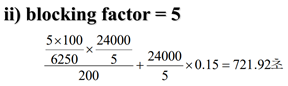
< 광 디스크 >
광 디스크
CD ROM의 장단점
장점: 가격이 저렴, 고용량,대량생산가능,보존성이 좋음
단점: 자기 디스크보다 탐구 시간이 길다
RAID
디스크의 성능과 신뢰성을 증진시키는 디스크 조직 기법
->많은 수의 저가 소형 디스크를 병렬로 사용하는 것이 고가 대형 디스크를 이용하는 것보다 효율적이게 만듦