
클래스 불균형이 심한 Anomaly Detection에서는 다수 클래스(i.e. 정상)에 해당하는 데이터만 잘 예측하는 경향이 있다.
정확도(Accuracy)는 클래스 비율을 고려하지 않기 때문에, 소수 클래스(i.e. 비정상)를 잘 예측하지 못하더라도 다수 클래스(i.e. 정상)만 잘 예측하면 높은 성능을 보이는 것처럼 나타날 수 있다.
반면, AUC (Area Under the Curve)를 이용하면 클래스 비율과 관계없이 모델의 두 클래스(정상, 비정상) 간 분포를 평가할 수 있어(분포가 얼마나 잘 분리되는지 평가할 수 있어) 더 정확한 평가가 가능하다.
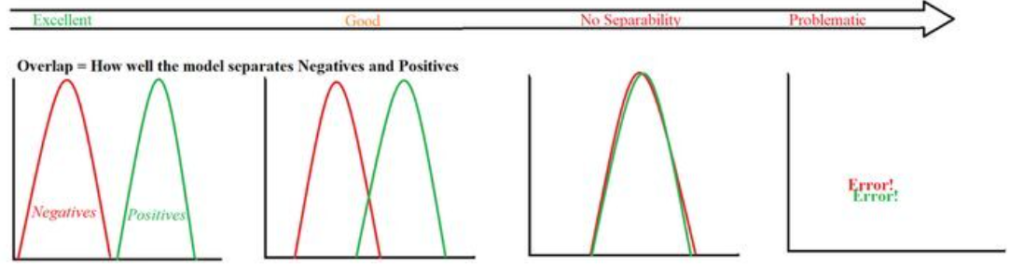
따라서 AUC는 Anomaly Detection의 평가 지표로 채택되고 있다.
Video Anomaly Detection에서 Anomaly Score가 다음과 같이 나왔다고 생각해보자.
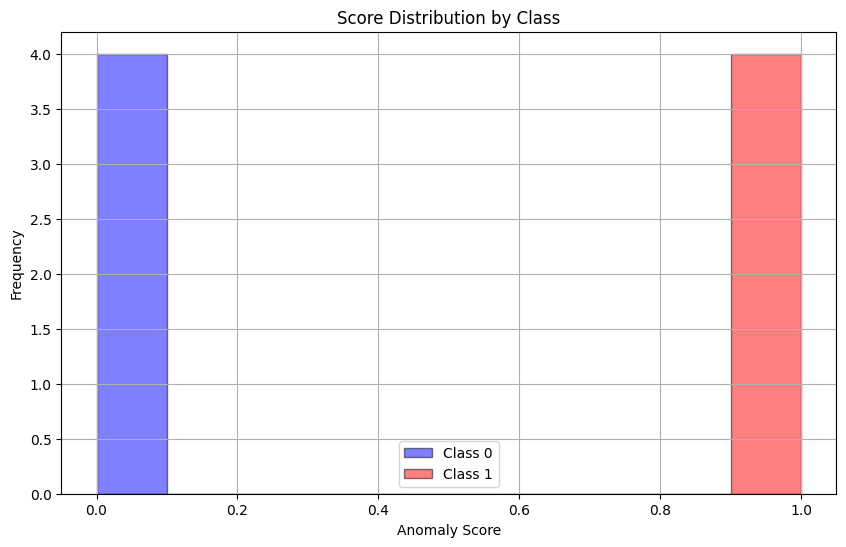
0~3번째 프레임은 정상이고, 4~7번째 프레임은 비정상일 때, 모델은 정상은 0으로, 비정상은 1로 올바르게 판단하고 있다.

이 때 정상 클래스(0)와 비정상 클래스(1)의 Anomaly Score 분포를 그려보면 다음과 같다.
(x-axis: anomaly score, y-axis: frequency, class: noraml(0), abnormal(1))
정상과 비정상 분포가 완전히 분리되어 있으며, 이 때 AUC는 1이 나온다.
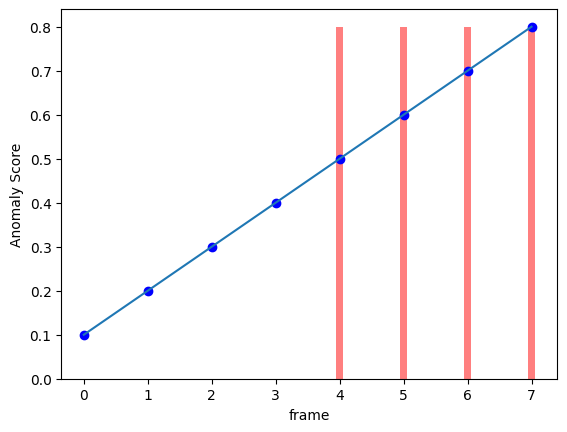
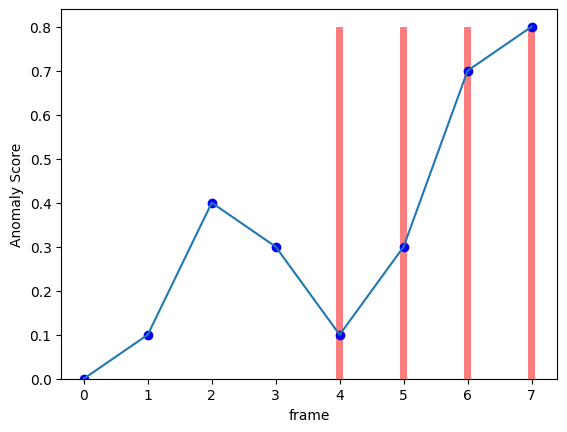
이번에는 정상에서 비정상 프레임으로 갈수록 Anomaly Score가 높아지는 상황을 생각해보자.
앞의 그래프보다는 이 그래프가 좀 더 현실적인 그래프일 것이다. 왜냐하면, 비정상 프레임의 시작 부분은 정상과 모호하여 사람도 판단하기 힘들기 때문이다.
따라서 이 그래프도 모델이 예측을 잘 했다고 평가를 하는 것이 옳다.
마찬가지로 분포를 그려보면 아래와 같으며, 분포가 겹치지 않기 때문에 AUC는 1이 나온다.
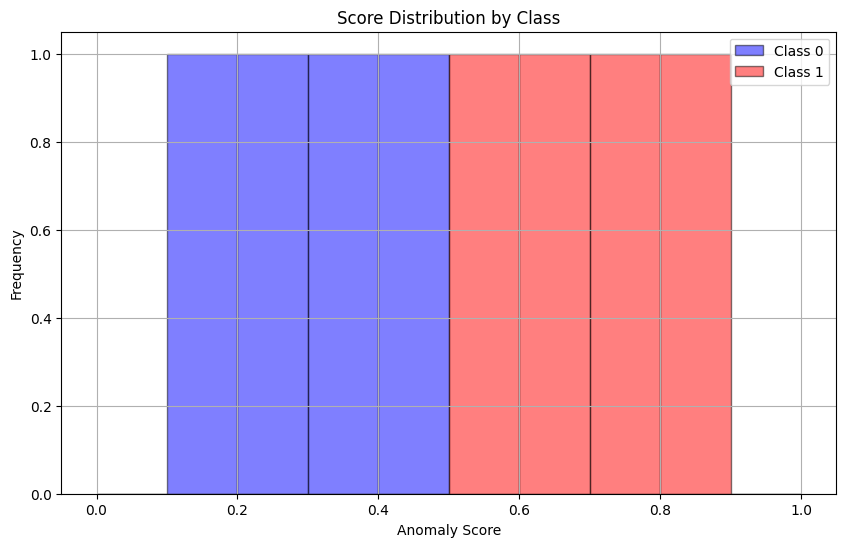
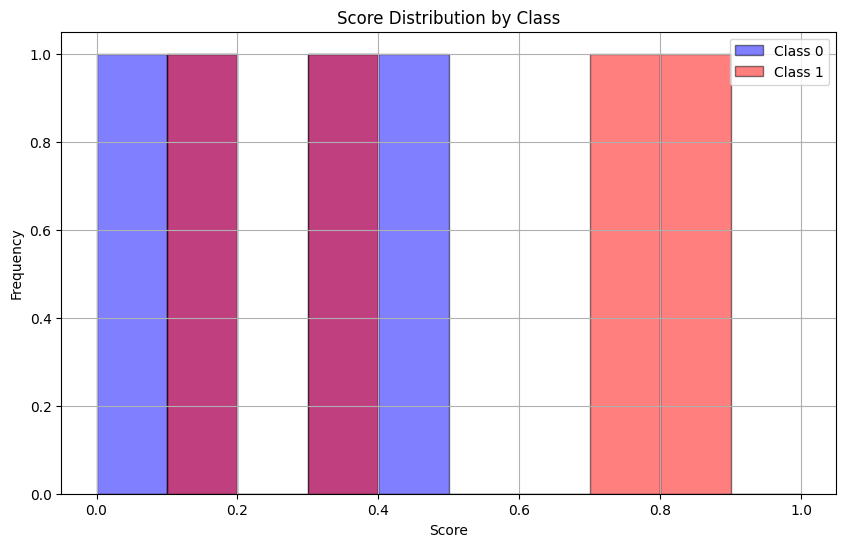
이번에는 모델이 이상 탐지를 잘하지 못한 그래프이다.
정상에 해당하는 1번 프레임과 비정상에 해당하는 4번 프레임이 같은 Score 값을 도출하는 것을 확인할 수 있다.
분포는 다음과 같이 겹쳐지며 AUC는 0.75로 낮은 성능을 보인다.
그렇다면 분포가 잘 분리되었는지 평가하기 위해서 AUC는 어떤 방식으로 계산될까?
바로, score의 threshold를 바꿔가며 TPR(Positive를 얼마나 잘 맞췄는지)와 FPR(Negative를 얼마나 틀렸는지)를 계산하는 것이다.
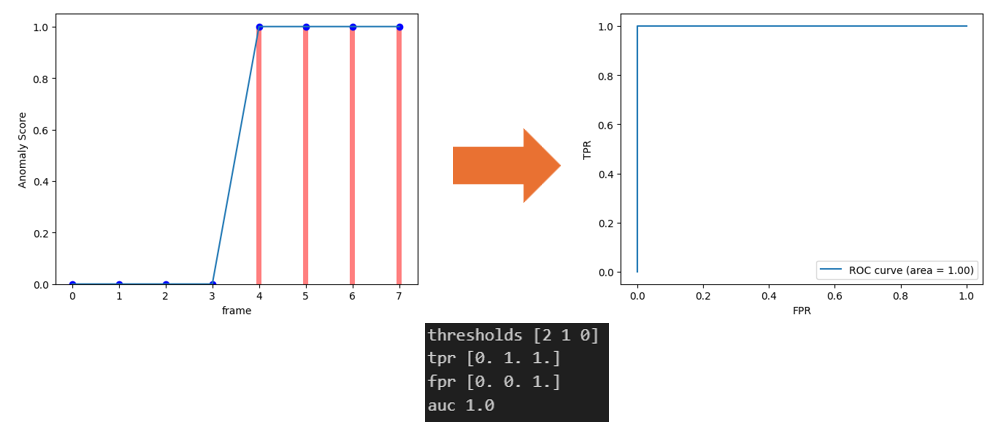
예를 들어, 아래의 그래프는 score로 0과 1 값을 가지므로, threshold는 [0과 1, 1+a]가 선정된다.
이 때, threshold가 1이면, score가 1 이상인 frame은 positive로 판단되고, 1미만인 frame은 negative로 판단되어 TPR과 FPR이 계산된다.
해당 그래프는 완벽하기 때문에, threshold에 따라 TPR과 FPR을 표시한 ROC-Curve의 아랫면적(AUC)은 1로 계산된다.
그리고 아래와 같이 모델이 잘 예측을 하지 못했다면, TPR이나 FPR이 낮아져서 AUC는 낮아지게 된다.
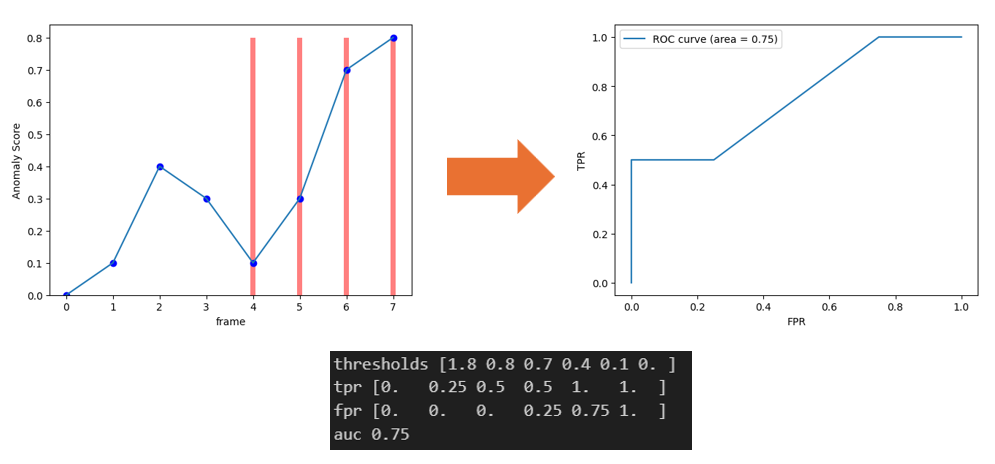
AUC는 다양한 threshold에서 모델이 얼마나 양성과 음성을 잘 구분하는지를 종합적으로 측정한 지표이다. 모든 threshold에서 TPR이 높고 FPR이 낮게 유지된다면, 두 클래스는 잘 분리되었다고 볼 수 있다.
그런데 threshold를 자세히 살펴보면 (최솟값, 최댓값, 최댓값+1)이 포함되어 있는 것처럼 보이는데, 실제로는 score의 고유값 전체를 기준으로 threshold가 구성된다. 이 중에서도 TPR이나 FPR에 변화를 주지 않는 값들은 sklearn 내부에서 제거되어 반환되지 않는다. 즉 AUC는 모든 score에 대해 계산되지만, 반환되는 threshold는 그 score들만 있어도 같은 AUC를 만들 수 있는 최소 집합이라고 이해하면 된다.
또한 최댓값+1과 같은 값이 threshold에 포함되는 이유는, TPR과 FPR이 모두 0인 시작점을 ROC 곡선에 포함시키기 위해서다. 이 점이 있어야 ROC 곡선의 면적이 최대 1이 되도록 정확하게 계산될 수 있다.
지금까지 AUC를 사용하는 이유와 계산되는 방식에 대해 간단하게 알아보았다.
Anomaly Detection을 처음 공부하는 분들에게 도움이 되길 바란다.