입출력 시스템과 저장장치
주변 장치: 저속 주변 장치(키보드,마우스 등)와 고속 주변 장치(그래픽 카드,하드 디스크 등)으로 나뉨

채널: 데이터가 지나다니는 하나의 통로
-> 채널을 모든 주변장치가 공유하면 전체적으로 데이터 전송 속도가 느림
-> 전송 속도가 비슷한 장치끼리 묶어서 장치별로 채널을 할당하면 전체 데이터 전송 속도를 향상할 수 있음

초기의 구조는 모든 장치가 하나의 버스로 연결됨

버스는 메인 버스와 입출력 버스의 2개의 채널로 나뉨
메인버스: 고속으로 작동하는 CPU와 메모리가 사용
입출력 버스: 주변 장치가 사용

입출력 버스의 분리

메모리 공간 분할
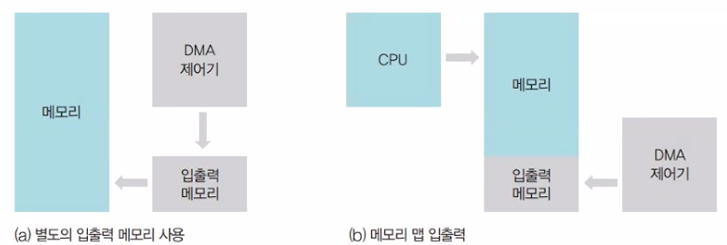
CPU의 작업 공간과 DMA의 작업 공간이 겹치는 것을 방지하기 위해 과거에는 DMA 제어기가 전송하는 데이터를 ‘입출력 메모리’라는 별도의 메모리에 보관
메모리 맵 입출력: CPU가 작업하는 공간과 DMA 제어기가 데이터를 옮기는 공간을 분리하여 메인 메모리를 운영
입출력과 인터럽트
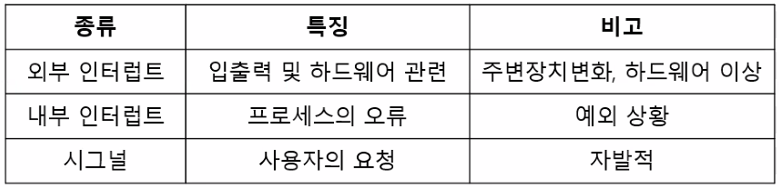
인터럽트는 주변장치의 입출력 요구나 하드웨어의 이상 현상을 CPU에 알려주는 역할을 하는 신호
외부 인터럽트: 입출력 장치로부터 오는 인터럽트 뿐 아니라 전원 이상이나 기계적인 오류 때문에 발생하는 인터럽트를 포함
내부 인터럽트: 프로세스의 잘못이나 예상치 못한 문제 때문에 발생하는 인터럽트
시그널: 사용자가 직접 발생시키는 인터럽트
인터럽트 벡터: 인터럽트 종류마다 번호를 정해서 번호에 따라 처리해야 할 코드가 위치한 부분을 가리키는 자료구조
인터럽트 핸들러: 인터럽스를 실제 처리할 코드, 함수
버퍼
속도가 다른 두 장치 속도 차이를 완화하는 역할을 하는 저장 공간
-> 이중 버퍼를 사용하면 한 버퍼는 데이터를 담는 용도, 한 버퍼는 데이터를 가져가는 용도로 사용
하드웨어 안전 제거
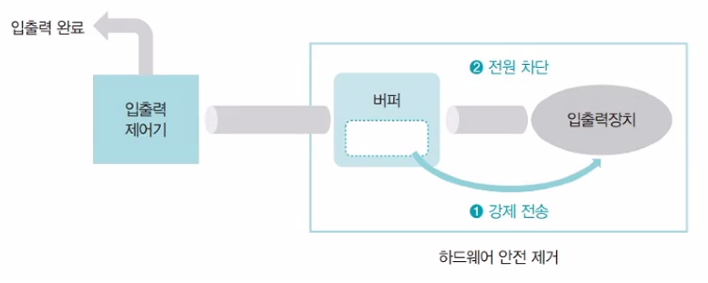
버퍼가 다 차지 않으면 버퍼가 다 찰 때까지 입출력장치에 자료가 전송되지 않는데, 이 상태에서 저장장치를 제거하면 버퍼 안의 데이터가 저장되지 않는 문제가 발생
-> 하드웨어 안전 제거를 사용하면 버퍼가 다 차지 않아도 강제로 버퍼의 내용이 저장 장치로 옮겨짐 (플러시)
하드 디스크의 구조
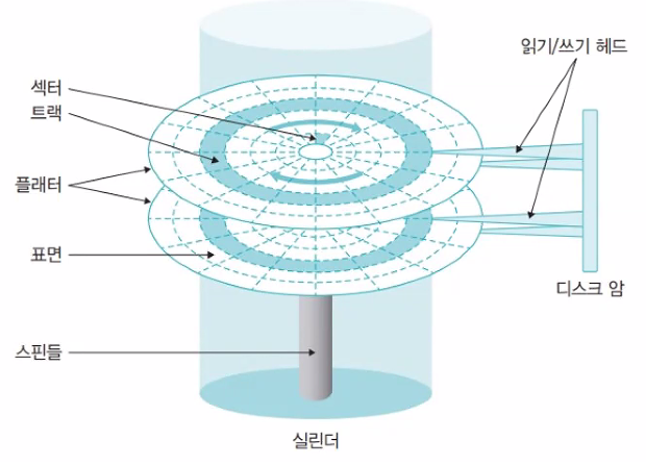
트랙: 플래터에서 회전축을 중심으로 데이터가 기록되는 동심원
실린더: 여러 개의 플래터에 있는 같은 트랙의 집합
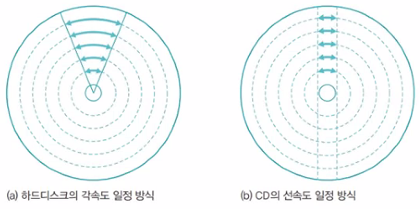
하드디스크와 CD의 디스크 회전
- 각속도 일정 방식 (하드디스크)
하드디스크의 플래터는 항상 일정한 속도로 회전하여 바깥쪽 트랙의 속도가 안쪽 트랙의 속도보다 훨씬 빠르다.
– 장점: 디스크가 일정한 속도로 회전하기 때문에 구동 장치가 단순하고 조용하게 작동
– 단점: 모든 트랙의 섹터 수가 같고 바깥쪽 섹터의 크기가 안쪽 섹터보다 커서 안쪽 트랙에 비해 바깥쪽 트랙으로 갈수록 낭비되는 공감이 생김 - 선속도 일정 방식 (CD)
CD에 사용하는 선속도 일정 방식은 어느 트랙에서나 단위 시간 당 디스크의 이동 거리가 같다.
– 장점: CD는 한정된 공간에 많은 데이터를 담을 수 있고 하드디스크처럼 바깥쪽 트랙의 섹터 공간이 낭비되는 문제가 없음
– 단점: 소음이 심함
하드디스크에서 데이터 전송 시간
탐색 시간 + 회전 지연 시간 + 전송 시간
파티션: 디스크를 논리적으로 분할하는 작업, 파티션 하나에 하나의 파일 시스템이 탑재
마운트: 유닉스 운영체제에서 여러 개의 파티션을 하나로 통합하는 것
포매팅: 디스크에 파일 시스템을 탑재하고 디스크 표면을 초기화하여 사용할 수 있는 형태로 만드는 작업
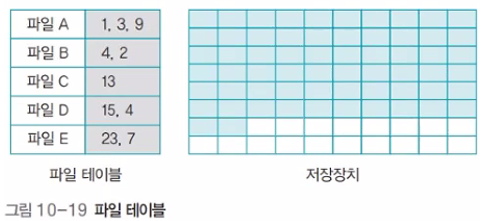
빠른 포매팅: 데이터는 그대로 둔 채 파일 테이블을 초기화하는 방식
느린 포매팅: 디스크에 파일 시스템을 탑재하고 디스크 표면을 초기화하는 방식
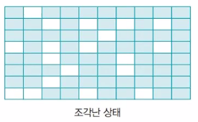
하드디스크에 조각이 많이 생기면 큰 파일이 여러 조각으로 나뉘어 저장되고 이를 읽기 위해 하드디스크의 여러 곳을 돌아다녀야 하기 때문에 성능 저하로 이어짐 -> 조각 모음
DAS: 서버와 같은 컴퓨터에 직접 연결된 저장장치를 사용하는 방식
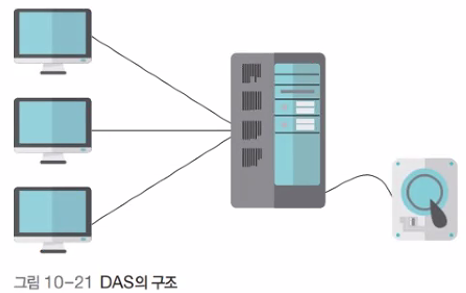
단점: 다른 운영체제가 쓰는 파일 시스템을 사용할 수 없음
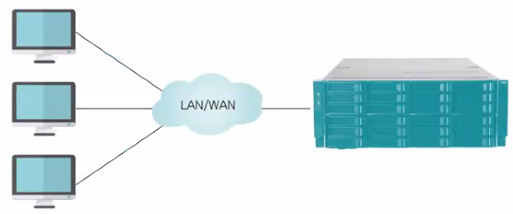
NAS: 저장장치를 LAN이나 WAN에 붙여서 사용하는 방식
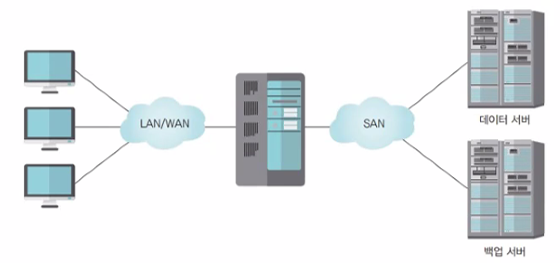
SAN: 데이터 서버, 백업 서버, RAID 등의 장치를 네트워크로 묶고 데이터 접근을 위한 서버를 두는 형태
디스크 스케줄링
사용할 데이터가 디스크 상의 여러 곳에 저장되어 있을 경우 데이터를 엑세스하기 위해 디스크 헤드가 움직이는 경로를 결정하는 기법
1. FCFS 스케줄링
입출력 요청 대기 큐에 들어온 순서대로 서비스를 하는 방법

이동 순서: 53 -> 98 -> 183 ->37 -> 122 -> 14 -> 124 -> 65 -> 67
이동 거리: 이동 순서에 따라 각각의 차를 더한다!
-> 45 + 85 + 146 + 85 + 108 + 110 + 59 + 2 = 640
답: 2번
2. SSTF 스케줄링
탐색 거리가 가장 짧은 트랙의 요청을 먼저 서비스하는 방법 (현재 헤드 위치의 가장 가까운 곳부터 처리)
- 대기 큐와 초기 헤드를 오름차순(내림차순)으로 정렬
- 초기 헤드 위치를 기준으로 좌우 비교, 더 짧은 거리로 이동
- 이동 거리의 경우 좌우 상관없이 거리의 절대값을 더하기

- 오름차순 정렬
14 37 53 65 67 98 122 124 183 - 초기 헤드 위치를 기준으로 좌우 비교, 더 짧은 거리로 이동
53->65->67->37->14->98->122->124->183 - 이동 거리의 경우 좌우 상관없이 거리의 절대값을 더하기
답: 1번
3. SCAN 스케줄링
SSTF가 갖는 탐색 시간의 편차를 해소하기 위한 기법
- 대기 큐와 초기 헤드를 오름차순(내림차순)으로 정렬
- 초기 헤드 위치를 기준으로 현재 진행 방향의 끝(0)까지 가고, 역방향의 끝까지 가기
- 이동 거리의 경우 좌우 상관없이 거리의 절대값을 더하기
현재 진행 방향: 좌->우 (문제에서 제시됨)
주의) 정답이 없으면 LOOK 스케줄링 방법을 이용
예제) 15 8 17 11 3 23 19 14 20, 초기 헤드 위치: 15
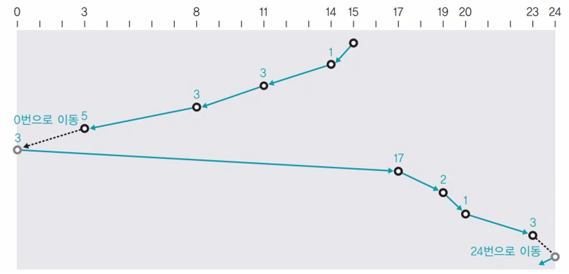
정렬: 0 3 8 11 14 15 17 19 20 23 (끝까지 가야 되므로 0이 추가됨)
이동: 15->14->11->8->3->0->17->19->20->23
헤드가 이동한 총 거리: 1+3+3+5+3+17+2+1+3=38
4. C-SCAN 스케줄링
SCAN 스케줄링을 변형 (헤드가 한쪽 방향으로 움직일 때는 요청받은 트랙을 서비스하고 반대 방향으로 돌아올 때는 서비스하지 않고 이동만 함)
현재 진행 방향: 좌->우 (문제에서 별 말이 없으면 항상 좌->우)
예제) 15 8 17 11 3 23 19 14 20, 초기 헤드 위치: 15
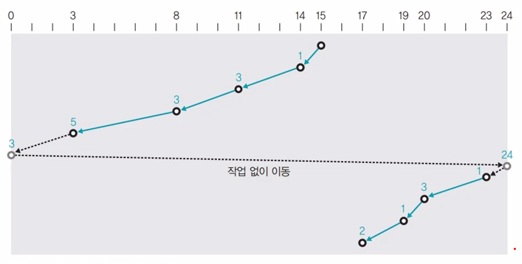
정렬: 0 3 8 11 14 15 17 19 20 23 24 (끝까지 가야 되므로 0, 24가 추가됨)
이동: 15->14->11->8->3->0->24->23->20->19->17
헤드가 이동한 총 거리: 1+3+3+5+3+24+1+3+1+2=46
5. LOOK 스케줄링
더 이상 서비스할 트랙이 없으면 헤드가 끝까지 가지 않고 중간에서 방향을 바꿈
예제) 15 8 17 11 3 23 19 14 20, 초기 헤드 위치: 15
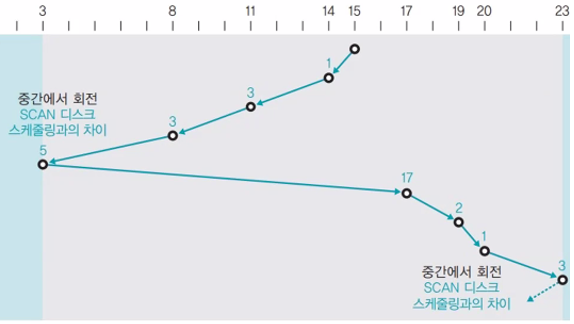
정렬: 3 8 11 14 15 17 19 20 23
이동: 15->14->11->8->3->17->19->20->23
헤드가 이동한 총 거리: 1+3+3+5+14+2+1+3=32 (그림에서 17은 오타)
6. C-LOOK 스케줄링
LOOK 스케줄링을 변형 (헤드가 한쪽 방향으로 움직일 때는 요청받은 트랙을 서비스하고 반대 방향으로 돌아올 때는 서비스하지 않고 이동만 함)

정렬: 16 35 40 50 65 90 112 165 170 180
이동: 50->65->90->112->165->170->180->16->35->40
헤드가 이동한 총 거리: 15+25+22+53+5+10+164+19+5=318
정답: 2번
7. 블록 SSTF 스케줄링
큐에 있는 트랙 요청을 일정한 블록 형태로 묶음
모든 트랙은 블록 안에서만 움직임
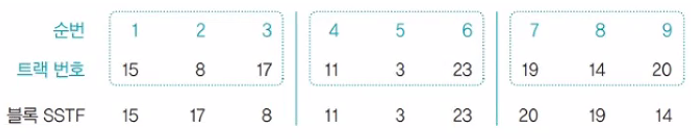
헤드가 이동한 총 거리: 2+9+3+8+20+3+1+5=51
-> 성능은 FCFS 스케줄링만큼 좋지 않음
RAID
자동으로 백업을 하고 장애가 발생하면 이를 복구하는 시스템
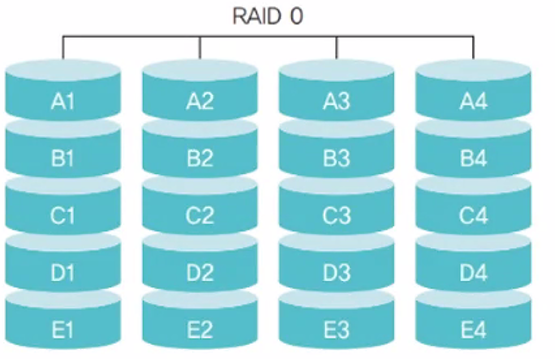
RAID 0
같은 규격의 디스크를 병렬로 연결하여 여러 개의 데이터를 여러 디스크에 동시에 저장하거나 가져올 수 있음
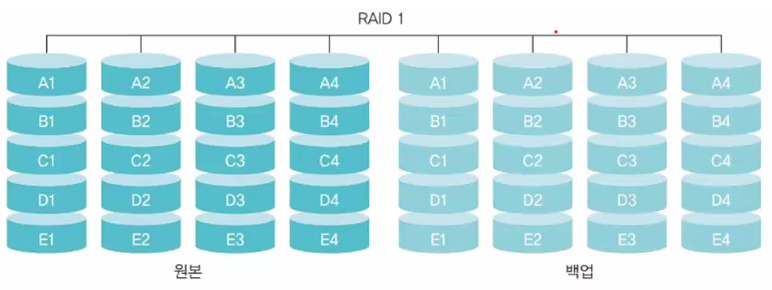
RAID 1
하나의 데이터를 2개의 디스크에 나누어 저장하여 장애 시 백업 디스크로 활용
RAID 2
오류를 검출하는 기능이 없는 디스크에 대해 오류 교정 코드를 따로 관리하고, 오류가 발생하면 이 코드를 이용하여 디스크를 복구

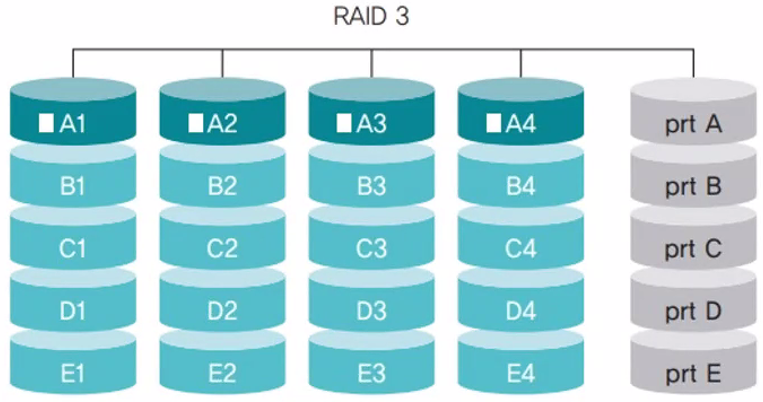
RAID 3
섹터 단위로 데이터를 나누어 저장
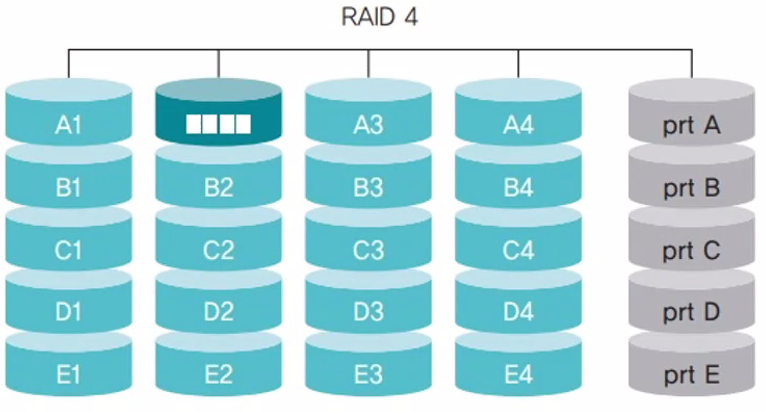
RAID 4
블록 단위로 데이터를 나누어 저장
-> 데이터가 저장되는 디스크와 패리티 비트가 저장되는 디스크만 동작한다는 것이 장점
RAID 5
패리티 비트를 여러 디스크에 분산하여 보관함으로써 패리티 비트 디스크의 병목 현상을 완화

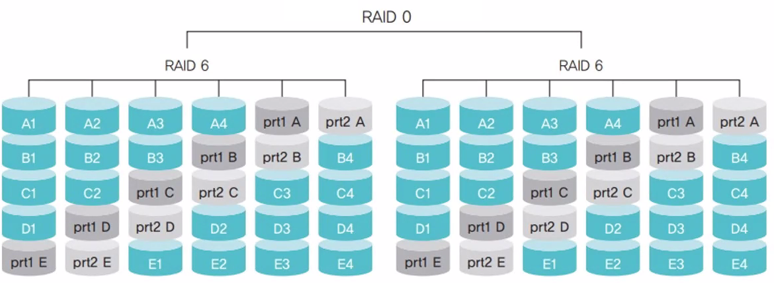
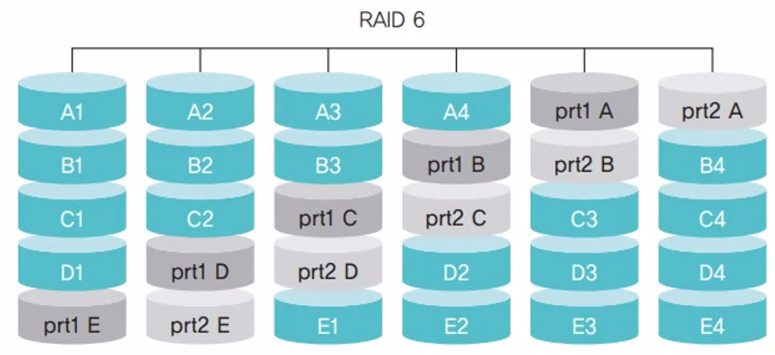
RAID 6
패리티 비트가 2개여서 디스크 2개의 장애를 복구할 수 있음
RAID 01은 스트라이핑한 디스크를 서로 미러링
RAID 10은 각각 미러링한 디스크를 스트라이핑

RAID 10이 더 좋은 방식이라고 평가받음
RAID 50은 RAID 5로 묶은 두 쌍을 다시 RAID 0으로 묶어 사용
RAID 60은 RAID 6으로 묶은 두 쌍을 다시 RAID 0으로 묶어 사용