
메모리 주소: 1Byte로 나뉜 메모리의 각 영역은 메모리 주소로 구분하는데 보통0번지부터 시작
-> CPU는 메모리에 있는 내용을 가져오거나 작업 결과를 메모리에 저장하기 위해 메모리 주소 레지스터(MAR)을 사용
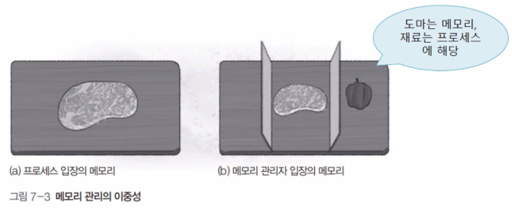
메모리 관리의 복잡성
메모리는 폰노이만 구조의 컴퓨터에서 유일한 작업 공간이며 모든 프로그램은 메모리에 올라와야 실행 가능
메모리 관리의 이중성
프로세스 입장에서는 메모리를 독차지하려 하고, 메모리 관리자 입장에서는 되도록 관리를 효율적으로 하고 싶어함
컴파일러의 목적
오류 발견: 소스코드에서 오류를 발견하여 실행 시 문제가 없도록 하는 것
코드 최적화: 소스 코드를 간결하게 정리하여 실행 속도를 빠르게 하는 것
컴파일러와 인터프리터의 차이

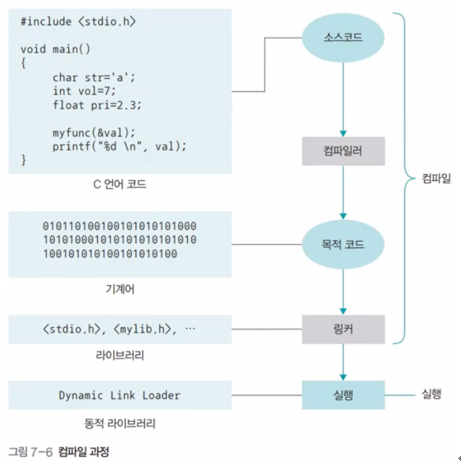
컴파일 과정
1. 소스코드 작성 및 컴파일
2. 목적 코드와 라이브러리 연결 (링커)
3. 동적 라이브러리를 포함하여 최종 실행
dll파일 (함수의 변경된 사항, 추가된 사항을 기록하여 다시 컴파일하는 것을 방지)
메모리 관리자
메모리 관리를 담당하는 하드웨어
– 가져오기 작업: 프로세스와 데이터를 메모리로 가져옴
– 배치 작업: 가져온 프로세스와 데이터를 메모리의 어떤 부분에 올려놓을지를 결정
– 재배치: 메모리가 꽉 차있어 새로운 프로세스를 위해 오래된 프로세스를 내보내는 작업
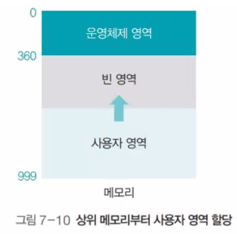
단순 메모리 구조
메모리를 운영체제 영역과 사용자 영역으로 나누어 관리
(한 번에 한 가지 일만 처리하는 일괄 처리 시스템에서 볼 수 있음)

-> 사용자 프로세스가 운영체제 영역의 크기에 따라 매번 적재되는 주소가 달라지는 것은 번거로움. 이를 개선하여 사용자 프로세스를 메모리 최상위(999)부터 사용
-> 메모리를 거꾸로 사용하기 위해 주소를 변경하는 일이 복잡해서 잘 안 쓰임
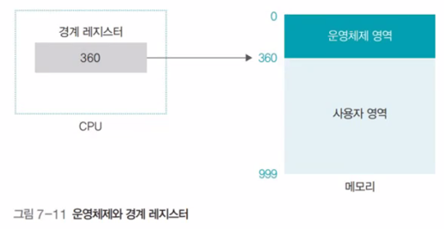
메모리 관리자는 사용자가 작업을 요청할 때마다 경계 레지스터의 값을 벗어나는지 검사하고, 만약 경계 레지스터의 값을 벗어나는 작업을 요청하는 프로세스가 있으면 그 프로세스를 종료 (사용자 영역이 운영체제 영역으로 침범하는 것을 막기 위함)
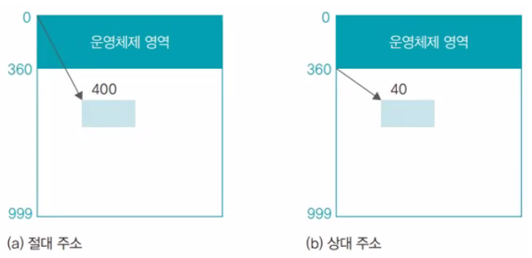
절대 주소
실제 물리 주소를 가리키는 주소
상대 주소
사용자 영역이 시작되는 번지를 0번지로 변경하여 사용하는 주소
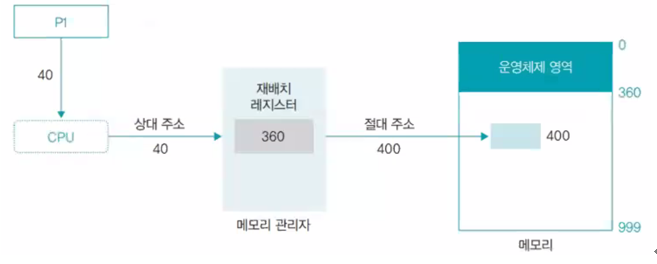
상대 주소를 절대 주소로 변환하는 과정
메모리 관리자는 사용자 프로세스가 상대 주소를 사용하여 메모리에 접근할 때마다 상대 주소 값에 재배치 레지스터 값을 더하여 절대 주소를 구함
재배치 레지스터는 주소 변환의 기본이 되는 주소 값을 가진 레지스터, 사용자 영역의 시작 주소가 저장됨
메모리 오버레이
프로그램의 크기가 실제 메모리(물리 메모리)보다 클 때 전체 프로그램을 메모리에 가져오는 대신 적당한 크기로 잘라서 가져오는 기법
(프로그램이 실행되면 필요한 모듈만 메모리에 올라와 실행)

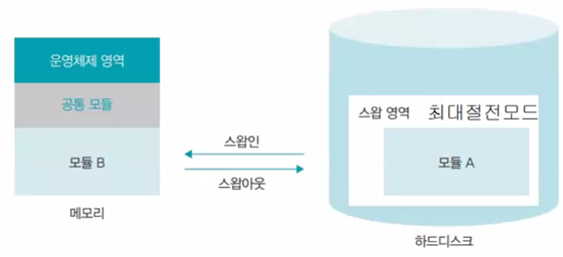
스왑 영역
메모리가 모자라서 쫓겨난 프로세스를 저장장치의 특별한 공간에 모아두는 영역
-> 메모리에서 쫓겨났다가 다시 돌아가는 데이터가 머무는 곳이기 때문에 저장 장치는 장소만 빌려주고 메모리 관리자가 관리
스왑인: 스왑 영역에서 메모리로 데이터를 가져오는 작업
스왑아웃: 메모리에서 스왑 영역으로 데이터를 내보내는 작업
메모리에 여러 개의 프로세스를 배치하는 방법
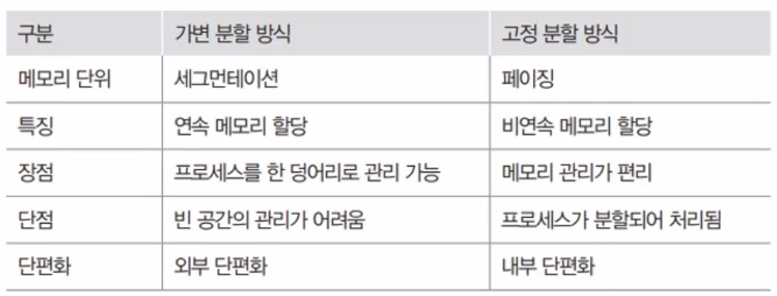
1. 가변 분할 방식: 프로세스의 크기에 따라 메모리를 나누는 것
-> 메모리의 영역이 각각 다름, 연속 메모리 할당
2. 고정 분할 방식: 프로세스의 크기에 상관없이 메모리를 같은 크기로 나누는 것
-> 큰 프로세스가 메모리에 올라오면 여러 조각으로 나누어 배치, 비연속 메모리 할당

가변 분할 방식의 장단점
장점: 프로세스를 한 덩어리로 처리하여 하나의 프로세스를 연속된 공간에 배치
단점: 비어 있는 공간을 하나로 합쳐야 하며, 이 과정에서 다른 프로세스의 자리도 옮겨야 하므로 메모리 관리가 복잡함
고정 분할 방식의 장단점
장점: 메모리를 일정한 크기로 나누어 관리하므로 메모리 관리가 수월
단점: 쓸모없는 공간으로 인해 메모리 낭비가 발생할 수 있음
외부 단편화: 작업보다 많은 공간이 남아 있더라도 실제로 그 작업을 받아 들이지 못하는 경우

외부 단편화 해결
- 메모리 배치 방식: 작은 조각이 발생하지 않도록 프로세스를 배치하는 것
1. 최초 배치(first fit): 프로세스를 메모리의 빈 공간에 배치할 때 메모리에서 적재 가능한 순서대로 찾다가 첫 번째로 발견한 공간에 프로세스를 배치하는 방법
(빈 공간을 찾아다닐 필요 없음)
2. 최적 배치(best fit): 메모리의 빈 공간을 모두 확인한 후 적당한 크기 가운데 가장 작은 공간에 프로세스를 배치하는 방법
(딱 맞는 공간을 찾을 경우 단편화가 일어나지 않음, 딱 맞는 공간이 없으면 아주 작은 조각을 만들어내는 단점이 있음)
3. 최악 배치(worst fit): 빈 공간을 모두 확인한 후 가장 큰 공간에 프로세스를 배치하는 방법
(프로세스를 배치하고 남은 공간이 크기 때문에 쓸모가 있음)
- 조각 모음: 조각이 발생했을 때 작은 조각들을 모아서 하나의 큰 덩어리로 만드는 작업

내부 단편화: 주기억장치 내 사용자 영역이 실행 프로그램보다 커서 프로그램의 사용 공간을 할당 후 사용되지 않고 남게 되는 현상

<< 단편화 문제 >>
1. 내부 단편화는 모두 얼마인가?
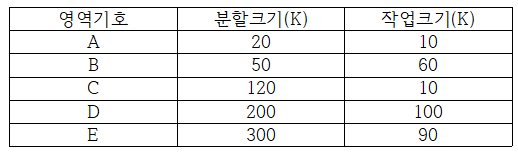
A. 작업을 넣고 남은 공간의 크기를 계산하면 된다. (10(A)+110(C)+100(D)+210(E))=430이 된다.
2. 내부 단편화와 외부 단편화의 크기는?
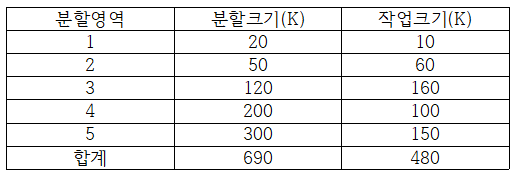
A. 내부 – 작업을 넣고 남은 공간의 크기를 계산하면 된다. (10(1)+100(4)+150(5))=260이 된다.
외부 – 작업을 넣지 못하는 분할 영역의 크기를 계산하면 된다. (50(2)+120(3))=170이 된다.
가변 분할 방식과 고정 분할 방식의 비교
버디 시스템
가변 분할 방식의 단점인 외부 단편화를 완화하는 방법, 가변 분할 방식이지만 고정 분할 방식과 유사한 점이 있다.
버디 시스템의 작동 방식
1. 프로세스의 크기에 맞게 메모리를 1/2로 자르고 프로세스를 메모리에 배치한다.
2. 나뉜 메모리의 각 구역에는 프로세스가 1개만 들어간다.
3. 프로세스가 종료되면 주변의 빈 조각과 합쳐서 하나의 큰 덩어리를 만든다.
버디 시스템의 특징
1. 가변 분할 방식처럼 메모리가 프로세스 크기대로 나뉨
2. 고정 분할 방식처럼 하나의 구역에 다른 프로세스가 들어갈 수 없고, 메모리의 한 구역 내부에 조각이 생겨 내부 단편화 발생
3. 비슷한 크기의 조각이 서로 모여 작을 조각을 통합하여 큰 조각을 만들기 쉬움