
강좌가 아니라 소스를 제공하는 글입니다!
구글 검색에 나오는 모든 이미지들을 다운로드하자!
Google Image Crawling에 들어간 라이브러리
- Selenium Library for Crawling
- Tkinter Library for GUI
- Threading Library for Concurrency
- Os Module for File Processing
- Webbrower Module for Showing HTML Document
- Urllib.request Module for Downloading
(프로그램 진행 화면)

1. webdriver를 생성 및 설정하는 과정입니다.
임시 윈도우에서 작업이 진행되며 Progress Bar로 진행 상태를 알립니다.
2. 설정을 마치고 윈도우 창에 들어온 상태입니다.
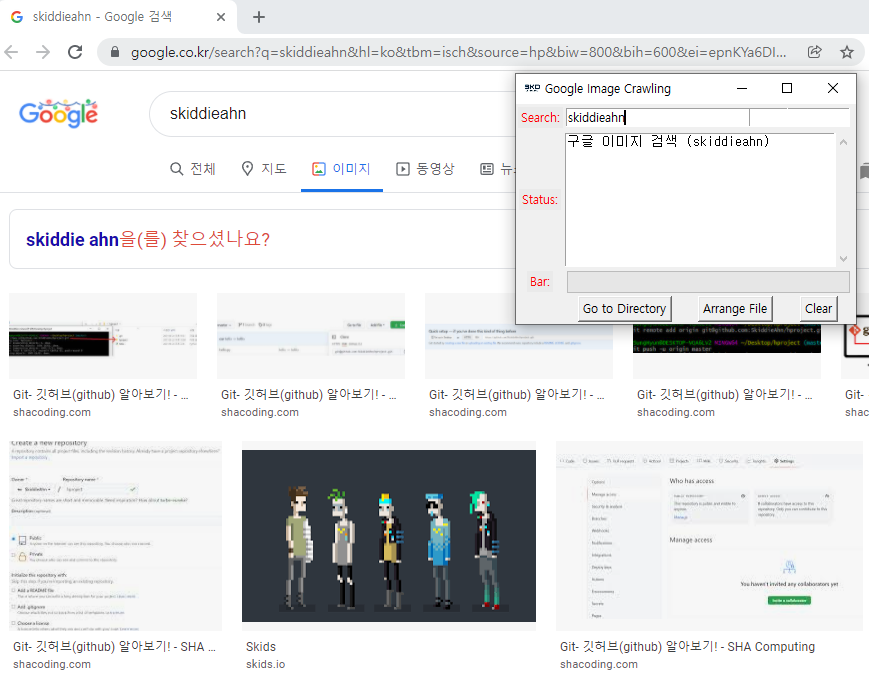
3. 필자의 닉네임으로 구글 이미지 검색을 해보았습니다.
Search Entry에 검색할 키워드를 적고 <Enter>를 누르면 웹 브라우저가 실행됩니다.
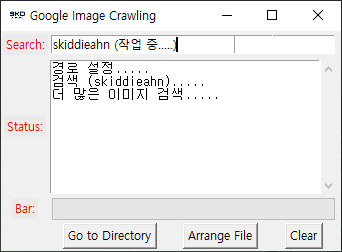

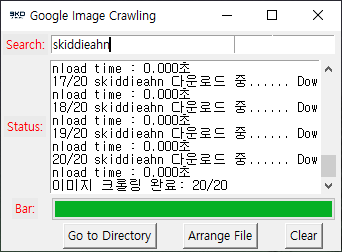
4. 이번에는 크롤링을 통해 <구글 이미지 검색>에 나온 모든 사진들을 다운로드해보았습니다.
Search Entry에 크롤링할 키워드를 적고 <F1>을 누르면 크롤링 및 다운로드가 진행됩니다.

5. 다운로드가 완료되면 이미지 파일이 저장된 디렉토리가 자동으로 열립니다.
[Go to Directory] 버튼을 통해 디렉토리를 수동으로 열 수도 있습니다.
디렉토리명: (사용자 입력 keyword)_img_download, 파일명: (사용자 입력 keyword)_(인덱스)

6. 하지만 원하는 이미지들만 저장되기는 쉽지 않습니다. 따라서 필요없는 이미지들은 삭제하였습니다.
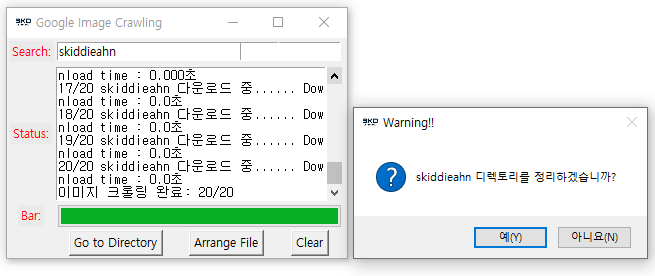
7. 삭제를 완료하면 [Arrange File] 버튼을 통해 디렉토리를 정리할 수 있습니다.

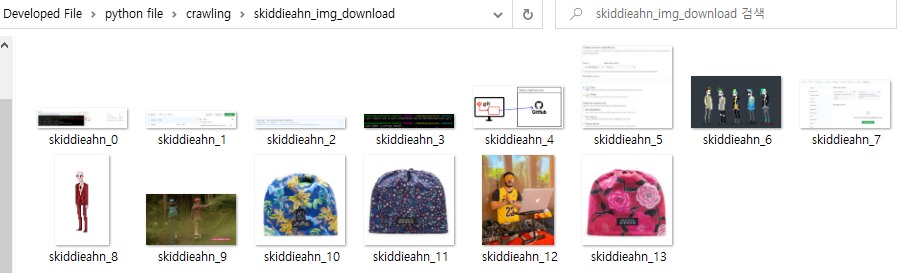
8. 정리가 완료되면 위처럼 파일명이 순서대로 바뀌게 됩니다.
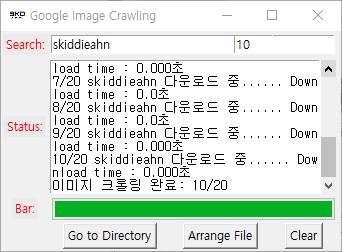
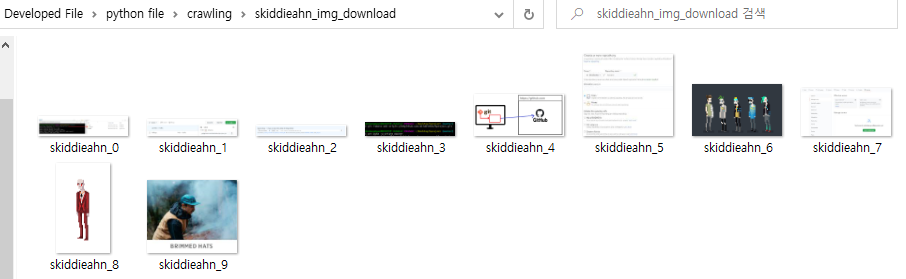
9. 이번에는 오른쪽 Entry에 수치를 추가하고 크롤링을 진행하였습니다.
수치를 추가하면 원하는 개수만큼 다운로드가 가능합니다.
위 예시는 10개의 이미지만 다운로드하는 모습입니다.

10. [Clear] 버튼을 누르면 모든 Text, Progress Bar가 초기화됩니다.
(프로그램 진행 과정)
드라이버 생성 및 설정 -> 키워드 입력 -> 다운로드 경로 지정 -> 구글 이미지 검색 접속 및 키워드 입력 -> 더 많은 이미지를 찾기 위한 스크롤링 -> 모든 이미지에 대한 url 크롤링 -> url을 통해 이미지 다운로드 -> 다운로드된 디렉토리 열기
(코드 및 파일 제공)
- skiddieahn_crawling_cli.py: 구글 이미지 크롤링의 CLI 버전. 크롤링 과정을 이해하려면 이 코드를 이용하세요.
- skiddieahn_crawling_gui.py: 구글 이미지 크롤링의 GUI 버전. 실제 사용을 하려면 이 코드를 이용하세요.
- skd.ico: GUI(상단 바)에 사용되는 앱 아이콘
- skd.jpg: GUI(임시 윈도우)에 사용되는 앱 이미지
- chromedriver.exe: 크롤링에 필요한 웹 드라이버 (Chrome을 자동으로 제어하는 기능) – 버전 96.0.4664.110
(참고 자료)