
RNN은 시계열 데이터를 다루는데 최적화된 인공신경망입니다.
시계열 데이터는 ‘시간 축을 중심으로 현재 데이터가 앞,뒤로 연관 관계가 있는 데이터’입니다.
예를 들어 (주식 가격, 음성 데이터, 자연어)가 있습니다.
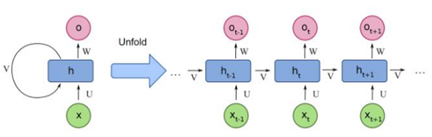
RNN은 이전 시간(t-1)의 은닉층의 출력을 다음 시간(t+1)의 은닉층으로 다시 집어 넣는 경로가 추가된 형태입니다.
따라서 앞에서 얻은 정보가 뒤에서 얻은 데이터와 연관관계를 가질 때 강력한 효과를 발휘합니다.
simple RNN
가장 간단한 형태의 RNN부터 알아 보겠습니다.
RNN에는 은닉층의 상태를 저장하고 있는 벡터가 있습니다.
현재 시점 T에서의 은닉 상태를 ht라고 정의하겠습니다.
새로운 은닉 상태 ht는 이전의 은닉 상태 ht-1과 현재 입력 벡터 xt 를 fw()에 넣어서 얻을 수 있습니다.
fw()는 주로 tanh를 사용합니다.
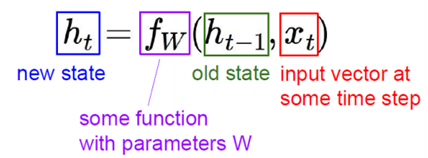
ht는 (새로운 은닉 상태)
ht-1는 (이전 은닉 상태)
xt는 (시간 t에서의 입력 벡터)
fw는 (가중치 W를 가지는 함수)
위의 식을 좀 더 자세히 기술하면 다음과 같습니다.
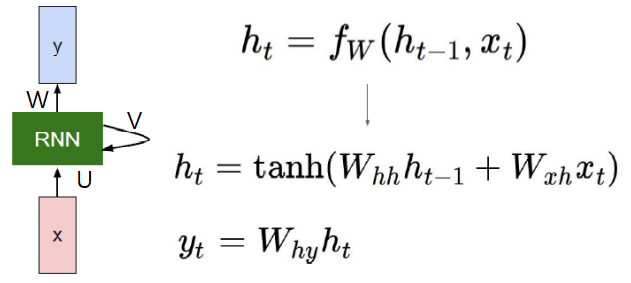
U,V,W는 Parameter로 각각 Wxh, Whh, Why을 나타 냅니다.
U(Wxh)는 새로운 입력을 (새로운 은닉 상태)로 변환하는 parameter입니다.
V(Whh)는 (이전 은닉 상태)를 (새로운 은닉 상태)로 변환하는 parameter입니다.
W(Why)는 (현재 은닉 상태)에서 출력을 생성하는데 사용되는 parameter입니다.
xt는 입력 벡터입니다.
ht는 (새로운 은닉 상태)로, 가중치(V,U)와 (이전 은닉 상태,입력 벡터)로 이루어진 식을 fw()에 넣어서 얻습니다.
yt는 출력 벡터로, (새로운 은닉 상태)에 가중치(W)를 곱한 형태입니다.
결국 ht(새로운 은닉 상태)는 아래와 같은 예시로 구해질 것입니다.
fw(h0,x1)=h1 -> fw(h1,x2)=h2 -> fw(h2,x3)=h3 -> fw(h3,x4)=h4 -> …
우리는 이 RNN으로 “hello”문자열을 학습할 수 있습니다.
(다음 문자 찾기)
학습은 아래와 같은 과정으로 진행될 것입니다.
1. 원핫 코딩으로 변경해서 입력으로 주기

일단 h는 (1,0,0,0), e는 (0,1,0,0)과 같이 원핫코딩한 것을 RNN 입력으로 주었습니다.
2. Training

위 예시는 ‘e’가 입력으로 들어올 때 output이 ‘o’가 나오면서 학습이 덜 된 상태입니다.
더 학습이 된다면 output이 ‘l’이 나오도록 w를 변경시킬 것입니다.
(backpropagation 알고리즘에 의해 업데이트)
RNN의 여러 종류
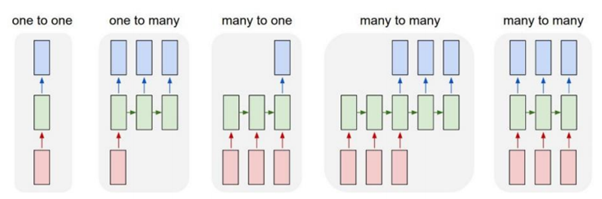
RNN은 여러 종류가 있습니다.
제일 왼쪽의 (one to one)이 앞에서 소개한 simpleRNN입니다.
입력 한 개가 들어와서 출력 한 개를 내보내는 RNN입니다.
각 RNN에 대한 예시는 아래에 정리하였습니다.
One to one: ex) 다음 단어 출력하기
One to many: ex) 한 단어를 보고 문장 출력하기
Many to one: ex) 여러 단어를 보고 공통된 특징 단어 출력하기
Many to many(1): ex) 번역기 (한글 문장 -> 영어 문장) <여러 입력이 들어가야 output이 나옴>
Many to many(2): ex) 비디오 분류 (프레임마다 분류)<입력으로 들어가자마자 output이 나옴>
LSTM과 GNU
simpleRNN은 입력 데이터가 길어질수록 학습 능력이 떨어진다는 단점이 있습니다.
학습을 할수록 이전 데이터에 대한 정보가 점점 상쇄되기 때문입니다.
그래서 ‘버스’라는 개념을 통해서 상태를 이어 나가는 RNN이 만들어졌습니다.
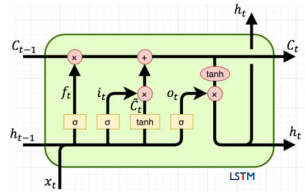
위는 LSTM인데, C라고 하는 버스를 통해 상태를 이어 나갈 수 있습니다.
버스는 이전 값이 없어지지 않도록 유지하는 역할을 합니다.
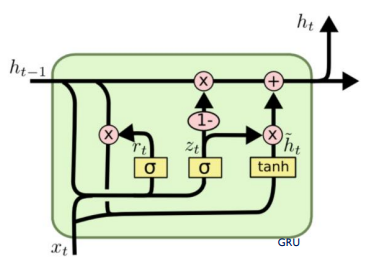
GRU는 LSTM과 비슷하지만 구조 상 더 간단해서 계산 상 이점을 가지는 모델입니다.
h가 cell state 역할을 대신하는 구조입니다.
이 모델은 sigmoid 2개를 사용해서 만들어 집니다. (lstm은 3개)
Embedding
Embedding Layer는 ‘문자열을 수치화된 정보로 변경하는 레이어’입니다.
예를 들어 ‘This is a big cat’이라는 문자열을 띄어쓰기 별로 구분해서
[0,1,2,3,4]라고 생각하겠습니다.
그럼 ‘This is big’이라는 문자열이 왔을 때,
[0,1,3]이라고 생각할 수 있습니다.
이 [0,1,3]을 원-핫 인코딩으로 표현한다면

처럼 0과 1로 이루어진 벡터로 표현이 됩니다.
그러나 Embedding방법으로 표현하면

처럼 실수 형태의 벡터로 표현이 됩니다.
‘이게 무슨 의미가 있어?’ 라고 생각할 수 있는데,
원-핫 인코딩은 벡터가 0과 1로 이루어져 각 단어들이 독립성을 이루지만
임베딩은 벡터가 실수로 이루어져 단어의 특성과 유사성도 지닙니다.
뿐 만 아니라, 경우에 따라 단어의 수보다도 적은 차원의 벡터로도 표현할 수 있습니다.
임베딩에 대한 더 많은 정보를 얻고 싶다면 ‘자연어 처리’를 알아 보시면 됩니다!!
-> https://www.tensorflow.org/text/guide/word_embeddings
감사합니다.