
이번에는 여러 CNN Architecture에 대해 알아 보겠습니다.
이 Architecture들은 ILSVRC 대회에서 이름을 알린 유명한 네트워크들입니다.
(ILSVRC: 대용량의 이미지셋을 주고 이미지 분류 알고리즘의 성능을 평가하는 대회)
1. LeNet
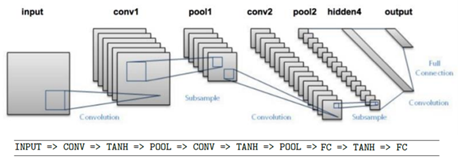
가장 초기에 이름을 알린 LeNet입니다.
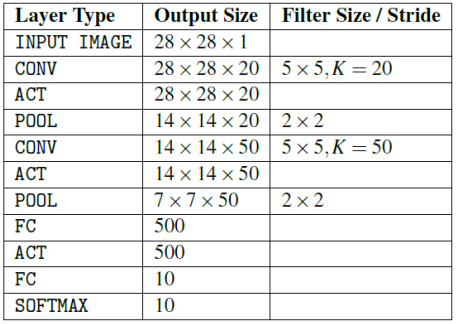
28x28x1 영상을 입력으로 받고 10개의 카테고리로 분류할 수 있습니다.
위 네트워크에서 TANH대신 RELU를 써도 무방합니다.
결국 CRP가 2회 있는 구조가 LeNet입니다.
전체 구조를 살펴 보면 아래와 같습니다.
2. AlexNet
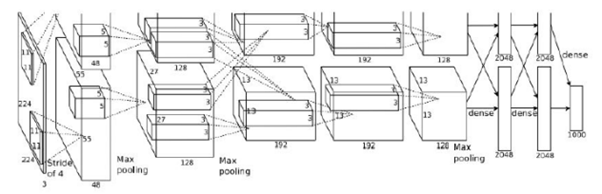
2012년 ILSVRC에서 낮은 에러율을 선보인 AlexNet입니다.
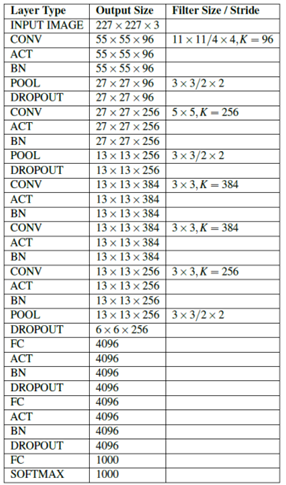
227x227x3 영상을 입력으로 받고 1000개의 카테고리로 분류할 수 있습니다.
첫 번째 레이어는 (컨볼루션 레이어)로 11×11 filter가 96개 쓰였습니다. 필터의 stride는 4입니다.
output size는 (227-11)/4+1=55가 96개 있으니 55x55x96이 됩니다.
parameter 수는 (11x11x3)이 96개 있으니 약 35,000개 정도가 됩니다.
두 번째 레이어는 (풀링 레이어)로 3X3 filter가 쓰였습니다. 필터의 stride는 2입니다.
output size는 (55-3)/2+1=27이니 27x27x96이 됩니다. (풀링은 서브 샘플링만 함)
parameter 수는 0개가 됩니다. (풀링은 학습을 하는 파라미터가 없음)
전체 구조를 살펴 보면 아래와 같습니다.
AlexNet의 특징
- 처음에 RELU 활성화 함수 적용
- Norm Layer 사용함
- 데이터 증대를 많이 적용함
- dropout 0.5
- batchsize 128
- SGD Momemtum 0.9
- learning rate 1e-2, reduced by 10
- L2 weight decay 5e-7
- 7 CNN 앙상블
Norm Layer – Local Response Normalization
-> weight가 작은 데이터는 무시하는 효과를 냄 (현재는 잘 안 쓰임)
3. ZFNet

AlexNet과 거의 유사한 네트워크입니다.
Conv1 레이어에서 (7×7 stride:2) 필터를 사용했고
Conv3,4,5 레이어에서 필터의 개수를 수정한 것밖에 없습니다.
그런데 에러율이 약 5%가 줄었다고 합니다.
4. VGGNet
작은 필터와 깊은 층을 지닌 네트워크입니다.
3×3 filter(stride:1, padding:1)를 사용하고 16~19개의 Layer를 지닙니다.
7×7 filter(stride:1, padding:1)를 사용한 것과 비교해보겠습니다.
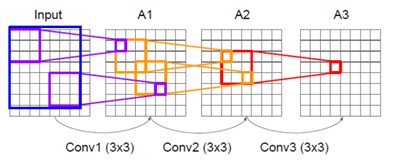
위 그림을 보면,
7×7 filter를 한 번 사용한 것과 3×3 filter를 3번 사용한 것은 Receptive Field가 같습니다.
7×7 filter를 썼을 때 구해야 되는 Parameter 수는 (7x7x1)이 됩니다. <채널 수를 1로 가정>
그런데 3×3 filter를 3번 쓰면 Parameter수가 (3x3x1)x3이 됩니다.
즉 같은 효과를 내면서 구해야 되는 parameter 수는 적은 것을 볼 수 있습니다.
결국 작은 필터를 여러 번 사용하는 효율적인 Architecture라고 말할 수 있습니다.
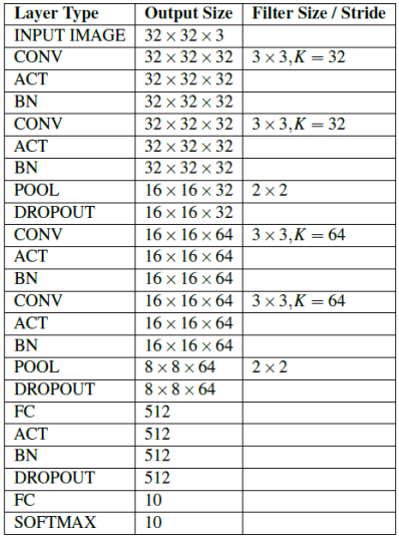
전체 구조를 살펴 보면 아래와 같습니다. (MiniVGGNet)
5. GoogleNet
Inception Module, 1×1 Convolution, Auxiliay Classifier가 특징인 GoogleNet입니다.
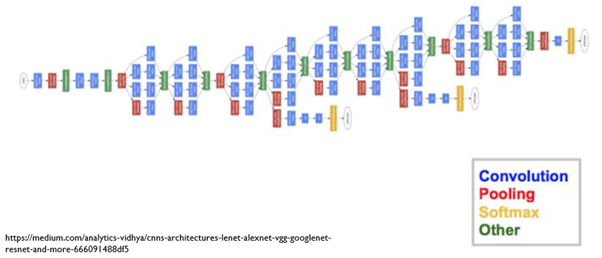
네트워크는 이전 모델이 비해 깊어 졌지만 Inception Module을 써서 Computational Efficiency는 좋아졌다고 합니다.
layer수가 22개지만 parameter수가 500만개로 AlexNet과 VGGNet보다 훨씬 적습니다.
FC Layer는 사용하지 않았습니다.
여기서 Inception Module이란 (network in network)를 말합니다.
큰 네트워크 안에 작은 네트워크가 있는 구조입니다.
아래의 (MLP in CNN)이 예시입니다.

GoogleNet에서 사용하는 Inception Module은 아래와 같습니다.

필터의 크기가 (1×1), (3×3), (5×5)인 모델에서 나온 feature를 합치고 출력하는 구조입니다.
각 conv레이어마다 Output 채널 수는 다르지만 concatenation하면 채널 수가 합쳐지게 됩니다.
그런데 이렇게만 하면 Computational Complexity가 너무 높아지므로
‘bottleneck‘ layer를 추가하였습니다. (1×1 conv layer)
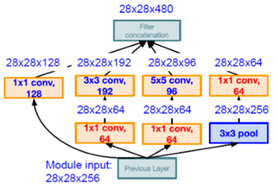
그렇게 한 결과 28x28x480이라는 output size를 가지며
computational complexity를 낮췄다고 합니다.
GoogleNet은 이러한 Inception Module이 9개 있는 구조입니다.

그리고 네트워크 사이에 있는 (파란 박스)가 Auxiliary Classifier입니다.
이것은 중간 네트워크의 결과물을 저장하고 역전파할 때 Gradient를 가져오는 역할을 합니다.
따라서 Vanishing문제를 예방할 수 있습니다.
현재 GoogleNet은 V4까지 발표되었습니다.
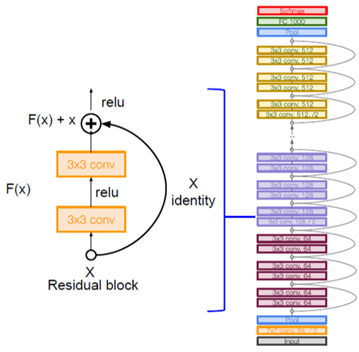
6. ResNet
Residual Block이 특징인 ResNet입니다.

Residual Block은 원본 데이터를 output feature에 넣어서 합치는 역할을 합니다.
아이디어는 이렇습니다.
‘모델이 깊을수록 학습이 제대로 되지 않으니까 output도 부실할 것이다. 따라서 원본 데이터를 output에 넘겨 줘서 중요한 정보를 계속 갖게 하자’
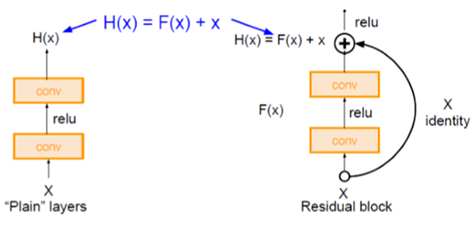
방법은 feature map에 해당하는 [ Output : H(x) ]를
[ Output : H(x) = feature map(F(x)) + 원본(x) ]로 대체하는 것입니다.
ResNet은 이러한 Residual Block이 여러 개 있는 구조입니다.
감사합니다.