
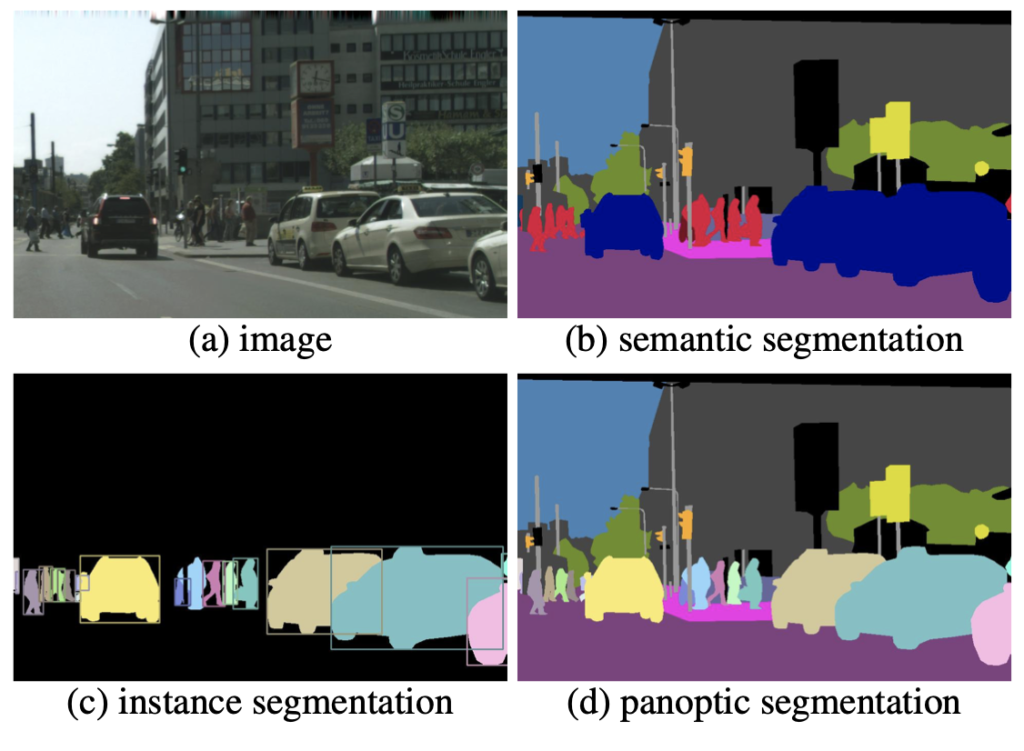
영상 분할은 입력 영상에서 픽셀 단위로 배경 및 객체를 분류하는 작업입니다.
영상 분할은 세 가지로 나뉘어 집니다.
semantic segmentation은 픽셀 단위로 객체와 배경을 분류하는데 종류까지 구분합니다.
instance segmentation은 픽셀 단위로 객체만 분류합니다. (종류는 구분 x)
panoptic segmentation은 픽셀 단위로 객체와 배경을 분류합니다. (종류는 구분 x)
본 포스팅은 영상 분할을 구분짓기 이전, 고전적인 알고리즘에 대해 간단히 다룹니다!
영상분할은 세 개의 방법론으로 나뉩니다.
Edge-based method는 edge정보를 주로 이용합니다.
로컬(주변) 정보를 이용해서 영상 분할을 한다는 의미입니다.
Region-based method는 region정보를 주로 이용합니다.
글로벌(멀리 있는)정보를 이용해서 영상 분할을 한다는 의미입니다.
마지막으로 Hybrid method입니다.
로컬 정보와 글로벌 정보를 모두 이용해서 영상 분할을 한다는 의미입니다.

(a)에 위치한 오브젝트를 분할한다고 가정하겠습니다.
(b)는 Region-based mehod를 이용한 결과입니다.
멀리 있는 밝은 영역도 이용하므로, 밝기 값이 유사한 영역으로 묶이는 문제가 발생합니다.
(c)는 Edge-based method를 이용한 결과입니다.
원하는 형태로 분할된 것을 보니 정확도는 Edge방법이 더 좋은 것을 확인할 수 있습니다.
하지만 위에서 말한 단점/장점은 일반적인 이야기이고,
지금부터 method들을 자세히 살펴 보고 설명하겠습니다.
1. Thresholding
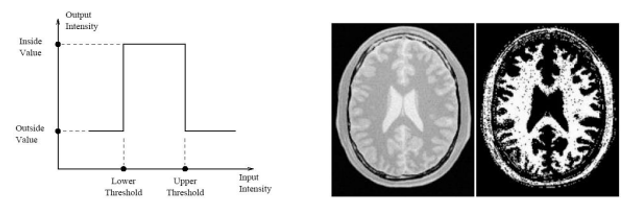
Thresholding은 기준 값(threshold)을 정하고, 기준 값에 따라 분할하는 개념입니다.
만약 어떤 ‘컵’ 영상에서 컵의 밝기 값은 128이고 나머지는 128보다 작을 때, segmentation을 하면
128을 기준으로 128보다 작은 픽셀은 모두 0으로 처리하는 방법으로 segmentation이 가능합니다.
그러면 컵 주위가 전부 검정색이 돼서 영상 분할을 성공적으로 할 수 있습니다.
그리고 Threshold(기준 값)을 여러 개 이용하면 영상도 여러 영역으로 분할할 수 있습니다.
(위 영상은 같은 회색으로 분할된 것처럼 보이지만 약간의 밝기 차이가 있습니다)
예를 들어 threshold가 2개면 영상은 세 영역으로 분할됩니다.
threshold가 3개면 영상은 네 영역으로 분할됩니다.
하지만 영상을 분할하는 ‘Threshold’를 찾는 일은 쉽지 않습니다.
따라서 영상을 두 개의 클래스(foreground,background)로 나누는 최적의 Threshold를 찾는 알고리즘이 있습니다.
바로 Otsu입니다.
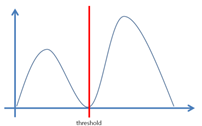
두 개의 클래스로 잘 나눈다는 것은
클래스 간 분산을 최대화한다는 것과 같습니다.
또한 수학적으로 ‘클래스 내 분산 최소화’를하면 ‘클래스 간 분산 최대화’ 가 이루어 진다는 것이 증명되어 있습니다.
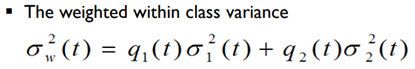
따라서 클래스 내 분산(within class variance)을 최소화하는 t를 찾는 방식으로 otsu알고리즘이 이루어집니다.

그렇게 한 결과 위 사진처럼 두 개의 클래스로 잘 분할된 것을 확인할 수 있습니다.
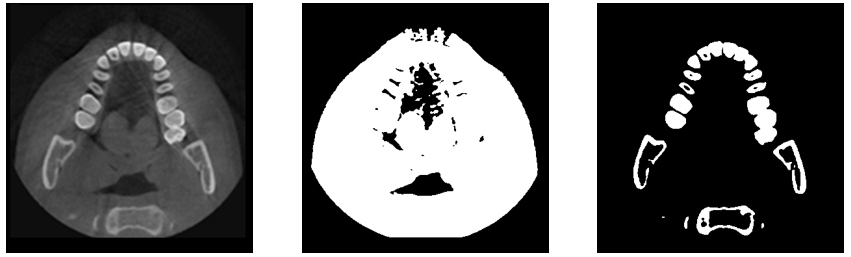
또한 Otsu를 여러 번 적용하는 Iterative otsu threshold를 이용하면 더 세분화된 분할도 가능합니다.
두 번째 사진은 foreground와 background 두 구간으로 분할된 영상입니다.
이 영상의 foreground 부분에 다시 otsu를 적용하면 세 번째 사진과 같이 ‘치아’만 확인할 수 있다는 것입니다.
2. Seed Region Growing
이 방법은 시드(seed)를 정한 다음 region을 growing하는 방식입니다.
시드는 찾으려고 하는 오브젝트 위의 점으로 여러 개를 지정할 수 있습니다.
region을 growing할 때는 4or8 neighbor 중 가까운 이웃들로 growing을 하는데,
거리의 기준은 사용자가 지정할 수 있습니다.
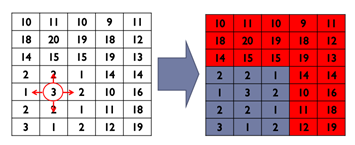
위 그림은 4-neighbor 중 밝기 값의 차이(거리)가 5이하인 것들만 묶은 결과입니다.
이 작업을 영상의 픽셀을 모두 확인할 때까지 진행하였습니다.
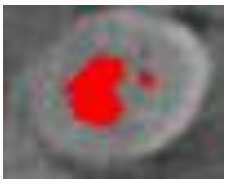
3차원 영상에서 region growing을 하면 위의 결과도 볼 수 있는데
‘reigion을 growing하는 개념이니 당연히 빨간 색 영역이 붙어 있어야 되지 않을까?’ 라는 의문이 생길 수 있습니다.
하지만 이런 경우, 2차원으로 봐서 안 보일 뿐이지 밑으로 붙어 있는 구조에 해당됩니다.
3. Watershed
watershed는 ‘오브젝별로 구분하는 선’을 의미합니다.
개념만 살펴보면 이렇습니다.
영상에 계속 물을 부으면서 높이를 한 칸씩 늘리는데, 두 오브젝트가 겹칠 것 같으면 watershed를 만드는 것입니다.
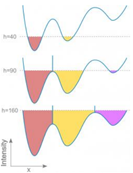
이 때, 오브젝트가 모이는 구간은 Catchements Basin이라고 불립니다.

이 방법은 빠르고 직관적입니다. 또한 Contrast가 poor일 때도 쓸 수 있고 closed contour를 제공한다고 합니다.
하지만 노이즈에 매우 취약하고 Over Segmentation(너무 잘게 분할됨)이 이루어질 수 있다고 합니다.
물론 open연산을 하고 region merging을 하면 극복할 수 있는 단점입니다.
4. Rain Simulation

Rain Simulation은 Immersion Simulation(watershed 방법)의 단점을 해결하기 위해 나온 방법입니다.
Immersion 방식은 여러 장점이 존재하지만 Watershed가 남아 있다는 단점을 해결할 수 없습니다.
Rainfall 방식은 catchments Basin을 계속 찾아 나가면서 region을 확대하는 개념입니다.
모든 픽셀을 확인하면서 자기보다 작은 값들을 묶은 결과를 catchments basin이라고 보는 것입니다.

ex) (10->9->8->7->1이 catchment basin) -> 모든 픽셀에 대해 적용하면 두 영역으로 나뉨
5. meanshift (피라미드 분할 이용)
데이터 분포의 무게 중심을 찾는 방법입니다.
현재 위치의 주변에서 가장 데이터가 밀집된 방향으로 이동했을 때, 처음 위치를 최종 영역과 같게 분류한다고 생각하면 됩니다.

과정은 아래와 같습니다.
1. ROI 설정 (radius 설정)
2. ROI에서 가장 밀도가 큰 곳을 찾고 중심으로 설정
3. 중심을 기준으로 ROI 다시 설정
4. 중심 위치의 변화가 없을 때까지 위의 단계 반복
5. 중심을 찾았으면 다음 픽셀을 기준으로 ROI설정하고 (1~4)과정 반복 [처음 위치 초기화]
최종 중심 영역의 평균 컬러 값은 처음 위치의 컬러 값으로 사용됩니다.
그래야 같은 클러스터에 있는 레코드의 색이 같아지게 됩니다.

하지만 이 방법을 원본 영상에 대해 적용하면 많은 시간이 소요됩니다.
따라서 피라미드에서 해상도가 가장 작은 영상에 meanshift를 적용하고,
그 결과를 이전 레벨에도 계속 적용하는 과정을 거칩니다.

6. General Curve Evolution
영상에서 객체가 있으면 객체 주위로 임의의 curve를 설정합니다.
이 초기 curve들은 어떤 식에 의해 객체로 다가갑니다.
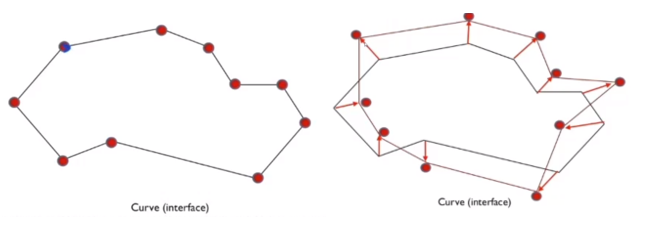
즉 curve점들이 찾고자 하는 오브젝트를 향해서 움직이는 개념입니다.
이 때 필요한 식은 아래와 같습니다.
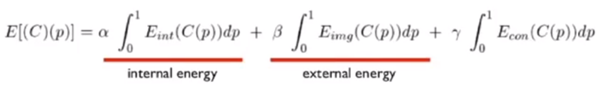
internal energy는 curve 모양을 유지하도록 하는 힘입니다.
external energy는 오브젝트를 향해 움직이는 힘입니다.
즉 curve점들은 energy function에 위치한 두 energy에 의해 움직이게 됩니다.
그리고 energy function이 줄어드는 방향으로 점들이 움직인다고 합니다.
Active Contour Model (Explicit Curve Model)
curve evolution을 적용한 모델을 Active Contour Model이라고 합니다.
그 결과는 아래와 같습니다.

(d)에 보이는 curve가 (f)에서는 오브젝트를 잘 찾아서 수축된 형태가 됩니다.
이 방법의 장점은 속도가 빠르고 끊어져 있는 object도 잘 찾는다는 점입니다.
예를 들어 아래 팬더 오브젝트를 잘 찾는다는 것입니다.
단순하게 region growing을 한다면 밝기 값의 차이가 적은 것끼리 묶일테니 팬더 형태를 유지할 수가 없습니다.

단점으로는 정확하게 오브젝트를 찾을 수가 없다고 합니다.
이 단점을 극복하기 위해 level set이라는 방법이 나왔다고 합니다.

7. k-means clustering
마지막 방법은 k-means입니다.
k-means는 ‘거리 기반 클러스터링’을 하는 방법입니다.
이 방법 소개는 ‘Machine Learning’ 카테고리에서 작성한 글을 그대로 가져 오겠습니다.

다시 영상처리 입장에서 살펴 보겠습니다.
k=3이면 세 영역으로 분할됩니다. 즉 세 개의 색으로 Segmentation됩니다.
K=7이면 일곱 영역으로 분할됩니다. 즉 일곱 개의 색으로 Segmentation됩니다.

GitHub에 파이썬 코드를 제공하겠습니다.
필자의 GitHub는 메인 화면 배너에 있습니다.