
매칭은 쉽게 말해 ‘일치하는 객체 찾기’입니다.
템플릿과 일치하는 객체를 입력 영상에서 찾는 작업을 의미합니다.
지금부터 매칭의 여러 가지 방법을 소개하겠습니다.
Block Matching
Block Matching은 템플릿을 입력 영상에 포개서 밝기, 컬러 값 차이를 구합니다.
한 픽셀 씩 움직이면서 차이 구하는 것을 반복하다가 제일 차이가 적은 구간을 발견하면 중단합니다.

이 방식의 단점은 템플릿의 크기와 입력 영상에 있는 객체의 크기가 다르면 매칭이 안 된다는 것입니다.
크기 뿐만 아니라 회전된 상태여도 매칭이 되지 않습니다.
해결 방법으로는 Block matching을 하기 전에 템플릿을 스케일링하거나 로테이션하는 것입니다.
스케일을 한 경우(0.8배, 0.9배, 1.1배, 1.2배, 1.3배)
로테이션을 한 경우 (0도, 2도, 4도, 6도, 8도)
가 있다고 하면 템플릿의 수가 25개이고, 25개의 템플릿에 대해 Blcok matching을 하는 것입니다.
디스크립터를 이용한 매칭
입력 영상과 템플릿에서 디스크립터를 찾고 두 디스크립터의 유클리디안 거리를 구합니다.
이 거리가 작을수록 매칭이 잘 된 것으로 취급하는 방법입니다.

이 방법은 다시 두 가지로 나뉩니다.
BFMatcher: 디스크립터를 일일이 하나씩 모두 검사하여 가장 가까운 디스크립터를 찾는 방법
예를 들어 템플릿의 키 포인트가 3개, 입력 영상에는 100개가 있다고 하겠습니다.
템플릿의 키 포인트를 각각 a,b,c라고 하면 [a의 디스크립터와 100개의 키 포인트에 대한 디스크립터를 체크], [b의 디스크립터와 100개의 키 포인트에 대한 디스크립터를 체크], [c의 디스크립터와 100개의 키 포인트에 대한 디스크립터를 체크] 를 체크합니다.
이렇게 총 300번을 체크하면서 a,b,c 디스크립터 각각과 가장 가까운 디스크립터를 찾는 것입니다.
이 방법은 정확성은 높지만 속도가 매우 느립니다.
FlannBasedMatcher: 가장 가까운 이웃의 근사값으로 매칭을 수행함
이 방법은 정확하게 같은 점을 찾는 것이 아니라 근처를 찾는 방법입니다.
즉 하나의 키 포인트씩 따지지 않고 전체 object의 위치를 찾는 것에 초점을 맞춥니다.
(템플릿 키 포인트들을 묶은 다음 입력 영상 키 포인트들과 대략적으로 비교한다고 생각됨)
이 방법은 정확성은 낮지만 속도가 빠릅니다.
호모그래피와 매칭
호모그래피는 ‘두 영상 사이의 관계’를 의미합니다.
예를 들어, 3차원 공간상의 평면을 서로 다른 시점에서 바라봤을 때 획득되는 두 영상이 있다고 하겠습니다.
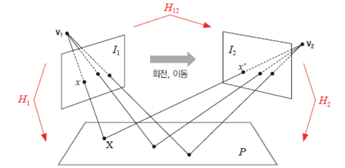
v1위치에서 본 (평면의 세 점의 위치)는 l1영상의 세 점과 매치가 됩니다.
v2위치에서 본 (평면의 세 점의 위치)는 l2영상의 세 점과 매치가 됩니다.
이 세 점간의 관계가 곧 호모그래피입니다.
이 호모그래피를 알면 [v1에서 보이는 오브젝트, v2에서 보이는 오브젝트]간의 변환 행렬을 구할 수 있습니다.
이 변환 행렬로 두 객체의 위치, 틀어진 정도, 크기 등을 파악할 수 있습니다.
이 호모그래피는 매칭으로 활용될 수 있습니다.
템플릿의 세 점, 입력 영상의 세 점이 있다고 가정하겠습니다.
이 세 점간의 관계를 알면(호모그래피를 알면) 객체가 틀어져 있더라도 같은 객체인지 확인할 수 있게 됩니다.
호모그래피의 특징
- 투시변환이므로 3×3행렬로 표현한다
- 네 개의 대응되는 점의 좌표 이동 정보가 있으면 행렬 계산 가능
이 호모그래피 행렬은 findHomography()함수로 계산할 수 있으며,
이 때 RANSAC메소드를 이용하면 이상치가 있어도 잘 작동한다고 합니다.
HOG
HOG는 물체 인식에 많이 사용되는 디스크립터입니다.

HOG방법으로 Feature Vector을 찾고 SVM을 이용하면 분류도 가능합니다.
아래는 HOG의 실행 과정입니다.
1. image roi crop후 종횡비가 1:2가 되도록 resize

2. 수평 수직 방향의 gradient를 계산하고 합쳐서 엣지 추출

3. 영상을 8×8 크기의 패치들로 나눔 -> 각 패치의 픽셀(8×8)을 확인 -> gradient magnitude, gradient direction로 히스토그램을 만듦 (x축은 magnitude, y축 값은 direction 값(10이면 linear하게 나눠서 처리))

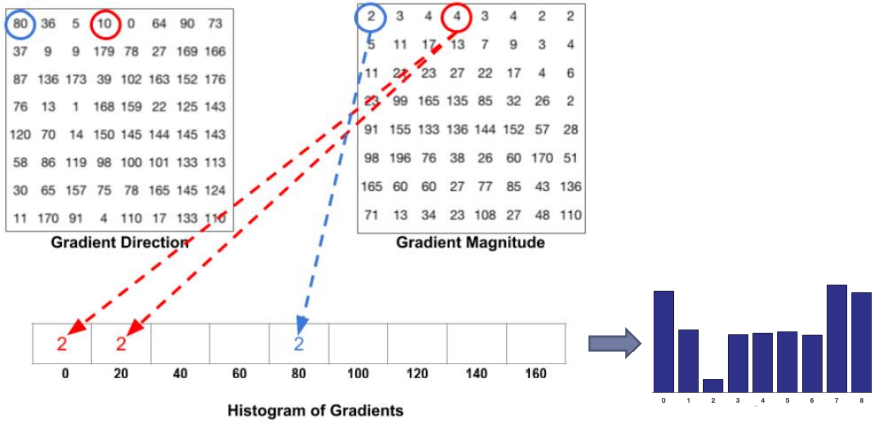
4. 각 셀 당 feature가 9개 -> 16×16크기의 블록으로 정규화 -> 36개의 특징을 정규화

5. 블록 당 36차원 feature가 나옴 -> 슬라이딩 윈도우 -> 36x7x15=3780차원의 feature vector을 얻음

6. 이 feature vector을 학습 데이터로 사용 (다르게 crop후 feature vector구한 것도 학습으로 사용)
7. 분류에 대한 학습을 하면, 새로운 데이터가 왔을 때 특정 클래스로 분류가 가능함
(영상의 크기가 다르다 -> 학습한 사람의 크기와 사람의 크기가 다르다 -> 사람을 못 찾을 수도 있음
- 피라미드 방식을 사용해서 처리하면 됨, hog.detectMultiScale함수를 이용해서 구함)
(패딩과 스트라이딩을 조정해서 영상 끝부분의 사람을 찾을 수 있고 사람을 촘촘히 찾을 수도 있음)
스티칭
스티칭은 여러 장의 영상을 서로 이어 붙여 하나의 큰 영상으로 만드는 기법입니다.
스티칭 결과 영상을 ‘파노라마 영상’이라고 합니다.
이 때 영상을 이어 붙일 때 매칭을 이용합니다.
‘디스크립터를 이용한 매칭’으로 가장 가까운 특징점을 찾고 이 부분을 이어 붙이는 것입니다.
유의미한 특징점이 많을수록 스티칭이 유리할 것입니다.

또한 호모그래피도 쓰입니다.
두 입력 영상의 관계를 알아야 얼마나 기울어져 있는지, 크기는 일치한지 등을 확인할 수 있겠죠.
아래는 스티칭의 실행 단계입니다.
- 입력 영상에서 특징점 검출 (가장 가까운 특징점)
- 호모그래피 계산
- 호모그래피 행렬을 기반으로 입력 영상을 변형하여 서로 이어붙이는 작업을 수행
- 이어 붙인 부분을 자연스럽게 보이기위해 블렌딩 처리
GitHub에 파이썬 코드를 제공하겠습니다.
필자의 GitHub는 메인 화면 배너에 있습니다.