
특징점 (keypoint)
특징점은 ‘영상에서 특징이 될 만한 지점’, ‘영상에서 중요 정보를 가지고 있다고 판단되는 지점’입니다.
특징점을 이용하면 (객체 검출 및 인식), (추적), (영상 간 매칭)이 가능합니다.
객체 검출과 추적 예시를 소개하겠습니다.
객체 검출: 사람의 눈,코,입, 이마의 경계 등 (다른 것과 구분지을 수 있는 점들)을 이용해서 객체를 알아낸다.
추적: 첫 프레임에서 객체를 찾고 다음 프레임부터는 이전 객체를 쫓아간다. (처음 찾은 객체를 이용)
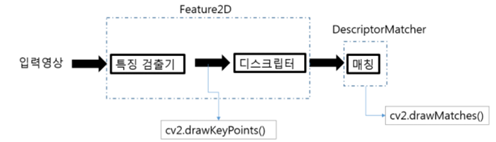
특징 검출기와 디스크립터
두 개의 영상에서 같은 객체를 찾기 위해 특징 검출기를 이용할 수 있습니다.
특징 검출기는 영상에서 특징점의 위치를 추출합니다.
그러나 위치는 랜덤 값이나 마찬가지여서 사실상 의미가 없습니다.
예를 들어, 그림 A의 컵 위치와 그림 B의 컵 위치가 다르면 각각 컵에 해당하는 특징점을 찾아도 같은 컵이라는 것을 증명할 수가 없습니다. (항상 컵의 위치가 같다면 (a,b)위치에 c한 특징점이 존재하면 같은 컵이라고 말할 수 있겠지만 이런 경우는 거의 없음)
이 때 특징점의 주변 밝기 값들을 비교했을 때 차이가 적으면 같은 컵이라는 것을 증명할 수 있습니다!!
이렇게 서로 다른 영상의 특징점이 서로 유사한지 비교할 수 있는 데이터를 Feature Vector라고 합니다.
그 예시로는 (특징점 주위의 밝기, 색상, 그래디언트 방향 등)이 있습니다.
Feature Vector는 다른 말로 디스크립터입니다.
그리고 디스크립터를 생성하는 함수도 쉽게 디스크립터라고 부릅니다.
이제 우리는 디스크립터를 이용해서 ‘유사한 특징점인지 비교할 수 있는 데이터’를 생성하고 매칭 과정을 통해 두 영상에서 같은 객체를 확인할 수 있습니다.
이번에는 특징 검출기의 종류를 소개하겠습니다.

특징 검출기마다 검출하는 특징점은 다릅니다. (하지만 주로 ‘코너’ 검출)
FastFeatureDetector는 지난 포스팅에서 다뤘으니 Pass하겠습니다.
1. MSER
-> (영상에서) 주변에 비해 밝거나 어두운 영역 중에 임계값을 변화시켰을 때 변화율이 작은 영역을 검출합니다.
이 때 임계값은 delta로 지정하며, delta가 클수록 검출되는 영역은 감소됩니다.
함수는 MSER_create, MSER_detectRegion를 이용합니다.
2. SimpleBlobDetector
-> 원을 이용해서 blob(주변보다 밝거나 어두운 영역)을 추출합니다.
함수는 SimpleBlobDetector_create를 이용합니다.
3. GFTTDetector
-> goodFeaturesToTrack 함수를 내부적으로 사용하여 특징을 검출합니다.
1. Harris나 MinEigenVal을 이용하여 코너점을 찾고 최대값을 측정합니다.
2. 최대값에 설정된 퀄리티 값을 곱하여 이보다 작은 코너 값은 모두 제거합니다.
예를 들어, 코너의 최대값이 100이고 퀄리티가 0.5면 50보다 작은 코너 값은 모두 제거됩니다.
함수는 GFTTDetecor_create를 이용합니다.
다음은 특징검출기+디스크립터의 종류를 소개하겠습니다.

위의 함수들은 특징검출기와 디스크립터의 역할을 모두 수행합니다.
1. ORB
-> fast 혹은 harris 방식으로 특징점을 찾고 brief 방식으로 디스크립터를 찾습니다.
fast는 피라미드 FAST 방식을 이용합니다.
피라미드란 ‘스케일 팩터를 줄이거나 변화를 주면서 코너를 찾는 것’을 의미합니다.
어떤 양을 늘리거나 줄이거나 또는 곱하는 수를 ‘스케일 팩터’라고 하는데,
예를 들어 256×256 영상을 128×128로 다운샘플링했다는 것은 스케일 팩터를 줄여서 영상을 작게 했다고 말할 수 있습니다.
다운샘플링을 하면 더 특징을 잘 찾을 수 있다고 합니다.
이 때 다운샘플링한 영상들을 겹쳐보면 피라미드 모양이 생성되는데
이 모양 때문에 피라미드 방식이라고 표현합니다.

brief는 특징점 주변의 픽셀 쌍을 미리 정하고 해당 픽셀 값 크기를 비교하여 0 혹은 1로 기술합니다.
두 점 x와 y에서 픽셀 값 크기 비교 테스트는 다음과 같이 정의합니다.
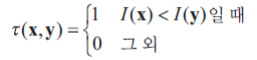
예를 들어, 아래 그림에서 특징점 p를 찾았습니다. 그리고 특징점 주변의 (a,b,c)점을 지정했습니다.
점 (a,b,c)는 픽셀 쌍 (a,b), (b,c), (c,a)로 나타낼 수 있습니다.
그렇다면 T(a,b)=1이고 T(b,c)=1이고 T(c,a)=0이니 디스크립터는 ‘110’이 됩니다.

orb의 특징은 속도가 빠르며 회전 불변성이라는 점입니다.
함수는 ORB_create를 이용합니다.
2. BRISK
-> Fast 혹은 AGAST 피라미드 기반으로 특징점을 검출합니다.

피라미드는 옥타브층과 인트라 옥타브층으로 구성됩니다.
BRISK 방식은 현재 옥타브와 위,아래 인트라 옥타브의 키포인트들을 이용해서 커브를 구합니다.
이 커브에서 Fast Score 값을 구한 것이 키포인트의 위치가 됩니다.

디스크립터 계산은 위처럼 특징점 근처에 동심원을 그리고 pair를 구성해서 계산한다고 합니다.
3. KAZE, AKAZE
-> 비선형 확산 필터링(nonlinear diffusion filtering)을 이용하고 특징점 검출 및 디스크립터를 찾는 방식입니다.
비선형 확산 필터링은 가우시안 피라미드 방식의 단점을 극복합니다.
가우시안 피라미드는 가우시안 필터링을 적용해서 부드러운 다운 샘플링을 만들고, 이렇게 만든 다운 샘플링을 이용해서 특징을 찾는 것입니다.
하지만 가우시안 필터링을 적용하면 특징점이 약화되는 경향이 있다고 합니다.
이러한 단점을 극복한 것이 ‘비선형 확산 필터링’ 입니다.
이 필터링은 키포인트를 보존하면서 노이즈를 제거시킵니다.
따라서 KAZE, AKAZE 방식은 ‘비선형 확산 필터링’을 이용해서 물체 경계가 유지되니 특징점 검출 정확도가 높아 집니다.
물론 속도는 준수하지 않는다는 점을 감안해야 합니다.
4. SIFT
-> Harris Corner Detection의 단점을 극복한 방법입니다.
Harris Corner Detection은 스케일 변환에 대응하지 못 합니다.
예를 들어 영상이 scale-up되면 잘못된 코너가 검출될 수도 있다는 것이죠.
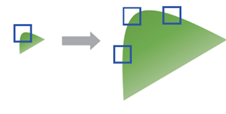
SIFT는 스케일 변환에 대응을 하면서 특징점을 찾을 수 있습니다.

인접한 가우시안 블러링의 차영상을 이용하면 DoG 구성이 가능해집니다.
이 DoG 영상을 이용해서 키포인트 후보군을 찾습니다.
이 때 엣지 성분이 강하거나 명암비가 낮은 지점은 제외합니다.
(정확하게 특징 지을 수 있는 지점을 확인)

디스크립터를 찾기 위해서는 특징점 주위로 16×16 윈도우를 설정하고 이를 다시 4×4 윈도우로 재구성합니다.
각 윈도우에는 8개의 bin값(방향 값)이 표현돼있습니다.
그러면 특징점 당 16×8=128개의 feature vector가 생성됩니다.
이 8개의 방향별로 누적을 해서 Gradient Histogram을 만들 수도 있습니다.
5. SURF
-> 박스 필터(Haar-like filter)와 적분 영상(Integral Image)을 사용하여 SIFT보다 강한 특징을 추출하는 방법입니다.
SURF는 키포인트가 있을만한 영역에 관심을 가집니다.
영역에 관심을 가지다 보니 영상에 필터를 포개서 Feature 값을 계산하는 과정을 반복합니다.
그 필터는 Haar-like라는 것인데,
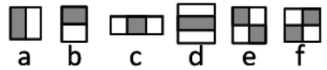
위와 같이 생겼습니다.
이 필터를 영상에 포갰을 때, 흰색 영역에 해당하는 밝기 값은 더하고, 검은 색 영역에 해당하는 밝기 값을 뺍니다.
이 값들을 Haar like Feature값으로 지정하는 것입니다.
이것이 가능하려면 각 영역에 존재하는 픽셀들의 밝기 합이 필요할 것입니다.
스캐닝 작업을 계속하면서 밝기 합을 계산하는데, 이전에 구한 밝기 합을 이용하면 더욱 효율적이겠죠?
그래서 적분 영상(Integral Image)이라는 것을 이용합니다.
적분 영상은 밝기 값이 누적된 영상입니다.
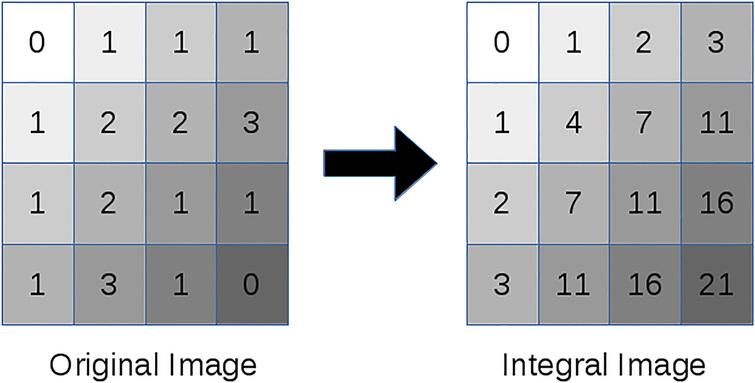
이 적분 영상을 이용하면 특정 영역의 밝기 값의 합을 빨리 구할 수 있습니다.
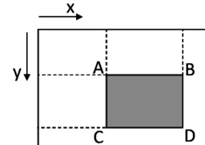
예를 들어, D의 영역에 해당하는 밝기 값의 합을 구해봅시다.
이것은 D-(B+C-A)를 하면 쉽게 구해집니다.
이러한 Haar-like 필터와 Integral Image를 이용해서 Dxx, Dyy, Dxy를 구하고 특징점을 구하는 방식이 SURF입니다.
Descriptor Matcher
Matcher는 두 영상에서 추출된 디스크립터의 유사도 비교합니다. (KNN 알고리즘 기반)
계산 방법은 Brute-force(정확도가 높지만 느림), Flann(정확도가 낮지만 빠름)방법을 제공합니다.
- 영상처리는 Flann방식을 많이 사용합니다.
GitHub에 파이썬 코드를 제공하겠습니다.
필자의 GitHub는 메인 화면 배너에 있습니다.