
비지도 학습에 대해 알아 보겠습니다.
비지도 학습은 출력 값(타깃 값)에 대한 정보 없이 학습을 진행하는 것을 말합니다.
정답이 주어지지 않을 때 학습을 하는 것으로, 학습이 끝난 뒤에도 정확성을 구할 수 없습니다.
따라 학습 결과를 직접 확인하여 평가해야 하는 방식입니다.
비지도 학습의 종류에는
비지도 변환과 군집화, 연관 규칙이 있습니다.
이번 포스팅은 비지도 변환에 해당하는 데이터 전처리를 다룹니다.
데이터 전처리는 기계 학습 모델의 성능을 높이기 위해 데이터를 변환하는 것을 의미합니다.
그렇다고 데이터 원본의 의미는 상실하지는 않기 때문에, 그저 데이터를 새롭게 표현한다고 생각하시면 됩니다.
이러한 전처리는 ‘스케일링’이라고 불리며 크게 4가지 종류가 있습니다.
StandardScaler: Feature의 평균을 0, 분산을 1로 변경
RobustScaler: 중간값과 사분위 값 사용 (Outlier 영향 덜 받음)
MinMaxScaler: feature 데이터 0~1 사이 정규화
Normalizer: feature의 크기를 1로 조정
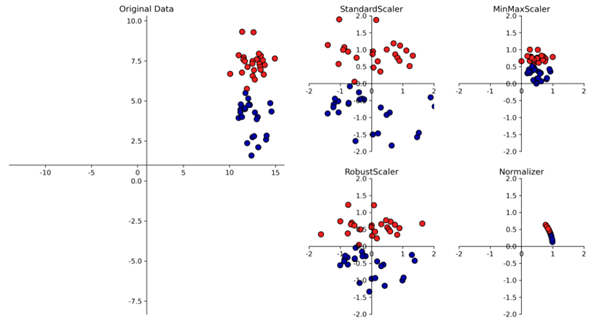
Normalizer 같은 경우 feature의 크기가 1이다 보니 반지름이 1인 원에 데이터가 놓인 형태가 됩니다. <2차원인 경우>
유방암 데이터를 이용해서 스케일링을 구현해보겠습니다!
from preamble import *
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import Normalizer
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
mglearn.plots.plot_scaling() # 스케일링 그려보기
cancer = load_breast_cancer() # 유방암 데이터 사용하기
X_train,X_test,y_train,y_test=train_test_split(cancer.data, cancer.target, random_state=1)
print(X_train.shape)
print(X_test.shape)
# 훈련 데이터 변환
scaler = MinMaxScaler()
scaler.fit(X_train) # 훈련 세트에 적용되는 스케일러 만들기 (훈련 데이터 가지고 비지도 학습을 통해 Scaler모델을 만든다고 생각해도 됨)
X_train_scaled=scaler.transform(X_train) # 훈련 세트 스케일링
#scaler.fit_transform(X_train) # 위 두 줄 대신 이 한 줄로 스케일링 가능
print("변환된 후 크기", X_train_scaled.shape)
print("스케일 조정 전 특성별 최소값:\n",X_train.min(axis=0)) # 열의 기준으로 min값을 구하라 <axis=0> -> 30개 값이 나옴
print("스케일 조정 전 특성별 최대값:\n",X_train.max(axis=0))
print("스케일 조정 후 특성별 최소값:\n",X_train_scaled.min(axis=0))
print("스케일 조정 후 특성별 최대값:\n",X_train_scaled.max(axis=0))

훈련 데이터는 총 426개의 레코드, 테스트 데이터는 총 143개의 레코드를 지닙니다.
스케일링을 통해 훈련 데이터가 변환돼도 이 수치는 변하지 않습니다.
다만 MinMax스케일링을 하였기 때문에 특성(feature) 별 최솟값과 최댓값은 변환됩니다.
최솟값이 0인 특성부터 185인 특성까지 다양했지만 이것들은 모두 0이 되었습니다.
최댓값이 0.03인 특성부터 4254인 특성까지 다양했지만 이것들은 모두 1이 되었습니다.
그렇다면 테스트 데이터는 스케일링을 하지 않을까요?
수치 차이가 많이 나기 때문에, 테스트 데이터도 스케일링을 적용해야 합니다.
그러나 같은 스케일러 모델을 사용해야 합니다.
즉 훈련 세트에 적용하는 스케일러 모델을 만들고, 이를 테스트 세트를 스케일링할 때도 사용하는 것입니다.
당연히 이렇게 하면 제대로 스케일링 되지는 않을 것입니다.
그러나 데이터 원본의 분포로 학습된 모델을 올바르게 사용하기 위해서는 같은 스케일러를 사용해야만 합니다!
# 테스트 데이터 변환
X_test_scaled=scaler.transform(X_test)
print("스케일 조정 후 특성별 최소값:\n",X_test_scaled.min(axis=0))
print("스케일 조정 후 특성별 최대값:\n",X_test_scaled.max(axis=0))

이제 정말로 모델 성능 향상이 되는지 살펴 보겠습니다.
모델은 추후 소개할 SVM으로 진행합니다.
# SVM 모델 이용해서 정확도 비교 < 스케일 전/ 스케일 후 >
from sklearn.svm import SVC
svm=SVC(C=100)
svm.fit(X_train,y_train)
print("테스트 세트 정확도: {:.2f}".format(svm.score(X_test,y_test)))
#0~1 사이로 스케일 조정
scaler=MinMaxScaler()
X_train_scaled=scaler.fit_transform(X_train)
X_test_scaled=scaler.transform(X_test)
svm.fit(X_train_scaled, y_train)
print("스케일 조정된 테스트 세트의 정확도: {:.2f}".format(svm.score(X_test_scaled,y_test)))
# 평균 0, 분산 1을 갖도록 스케일 조정
scaler= StandardScaler()
X_train_scaled=scaler.fit_transform(X_train)
X_test_scaled=scaler.transform(X_test)
svm.fit(X_train_scaled,y_train)
print("스케일 조정된 테스트 세트의 정확도: {:.2f}".format(svm.score(X_test_scaled,y_test)))
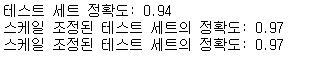
MinMax스케일링과 Standard스케일링을 진행해보았습니다.
스케일링을 진행하고 SVM모델에 적용했더니 정확도가 0.03씩 향상된 모습을 보입니다.
이렇게 모델 성능을 향상시키기 위해서는 스케일링 작업이 필수적입니다.
실제로 정확도를 높이기 위해 유용하게 쓰이는 방법이니 숙지하시는 편이 좋습니다!
감사합니다!