
다중키 파일
하나의 데이터 파일에 대해 여러 다른 탐색 키를 이용한 여러 개의 접근 경로를 제공
(기본 키로 파일을 접근해보고 보조 키로도 파일을 접근해보자)
- 한 파일에 대한 다수의 접근 경로를 구축해야 됨
Ex) (주민번호 키 파일)로부터 (실제 데이터 파일)로 가는 접근 경로를 구축,
(학번 키 파일)로부터 (실제 데이터 파일)로 가는 접근 경로를 구축 등등
-> 역 파일, 다중 리스트 파일이 사용됨
역 파일 구조
역 인덱스를 이용하는 구조
역: 인덱스와 데이터 파일을 연결
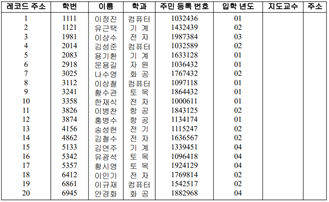
– 학번 순서대로 정렬된 순차파일
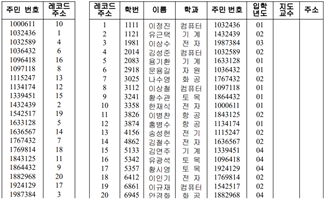
– 주민번호 역 인덱스
(인덱스 파일과 데이터 파일로 구성, 인덱스 파일의 한 행을 인덱스 엔트리, 데이터 파일의 한 행을 데이터 레코드)
Ex) 주민번호가 1000611인 학생을 찾고 싶음 -> 레코드 주소(10)을 찾아가면 됨
단점: 데이터 파일에 레코드가 삽입되면 역 인덱스도 갱신 -> 파일 관리 비용이 많이 듦
직접 파일 위나, 인덱스된 순차 파일 위에도 구성이 가능!
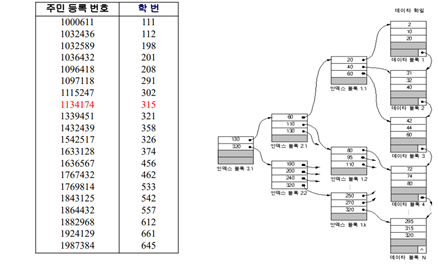
– 인덱스된 순차 파일 위에 구성

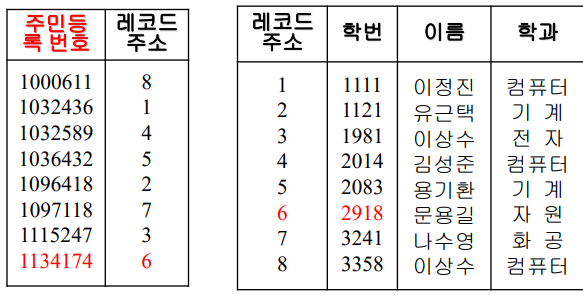
주민등록번호는 데이터 레코드에서 제외된 상태 ->
실제 데이터 파일에서 역 인덱스를 접근해야 됨 ->
학번으로 순차 탐색 -> 레코드 주소 찾기 -> 역 인덱스 접근 -> 주민등록번호 찾음
즉 검색이 비효율적!
역 인덱스가 만들어지는 수에 따라
1. 완전 역 파일
데이터 레코드의 모든 필드에 대한 역 인덱스
2. 부분 역 파일
몇 개의 필드에 대해서만 역 인덱스 구성
주소 기법
역 인덱스에서 직접 주소 기법(인덱스 엔트리가 레코드 주소를 가지고 있음)을 사용하면, 데이터 파일의 물리적 변화에 따라 역 인덱스 파일이 영향을 받음
->간접 주소 기법을 사용한다! 즉 ‘레코드 주소’ 대신 ‘기본키 or 보조키’를 사용한다.
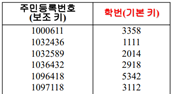
역 인덱스 파일에 영향을 주지 않고도 데이터 파일의 물리적 재구성이 가능해짐! (학번은 안 바뀌니까)
비유일 보조키에 대한 역 인덱스 <간접 주소 기법>
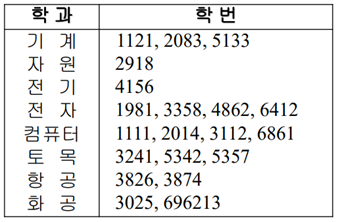
역 파일의 장점은 인덱스만으로 질의 응답이 가능하다!
<데이터 파일을 안 가봐도 응답이 가능>

역 파일의 연산
1. 레코드의 삽입
데이터 파일: 레코드 삽입,
역 인덱스 파일: 기존 인덱스 엔트리에 포인터만 첨가(비유일 보조키에서 같은 학과의 학생이 추가)하거나 새로운 인덱스 엔트리 삽입(비유일 보조키에서 없는 학과의 학생이 추가)
2. 레코드의 삭제
데이터 파일: 레코드 삭제, 역 인덱스 파일: 포인터 제거, 공백이면 엔트리 제거
3. 레코드의 갱신
데이터 파일: 레코드 갱신, 갱신 영향을 받은 모든 역 인덱스 파일에 삽입,삭제를 진행
(학번이 3241인 학생이 토목과에서 컴퓨터과로 전과하면 인덱스에서도 삽입,삭제)
다중 리스트 파일
– 연결 리스트처럼 생각, 다중 리스트 인덱스 각 열은 헤드 노드라고 생각하면 됨
– 링크(실제 주소)가 쓰일 수도 있고 키(간접 주소)가 쓰일 수도 있음
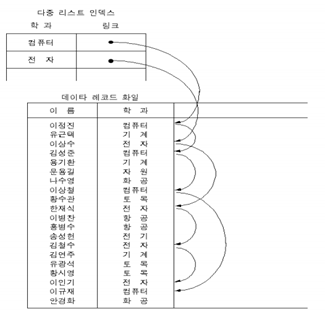
역 파일을 구성해도 데이터 파일 구조에 영향이 없음 (역 파일의 삽입,삭제 모두 상관 x)
다중 리스트 파일을 구성하면 데이터 파일 구조에 영향을 줌 (아래의 인덱스 엔트리에서
‘컴퓨터-1111’이 생기면 데이터 파일의 ‘1111’레코드부터 링크를 만들어야 됨)
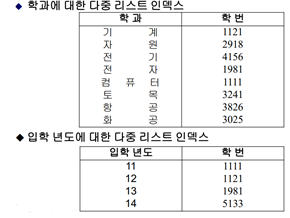
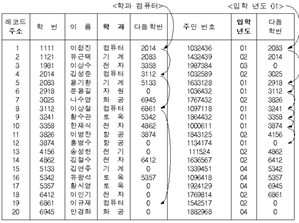
레코드의 검색 과정

역 파일 -> 인덱스만 접근해도 가능 (간접 주소 기법)
다중 리스트 -> 데이터 레코드를 접근해야 가능 (모든 링크들을 순회하면서 검색)
(1) 대안 -> 다중 리스트 인덱스에 길이를 주면 검색이 효율적이게 됨 (데이터 파일 안 가도 됨)
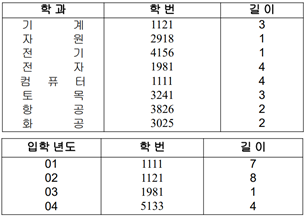
다중 리스트 파일의 연산

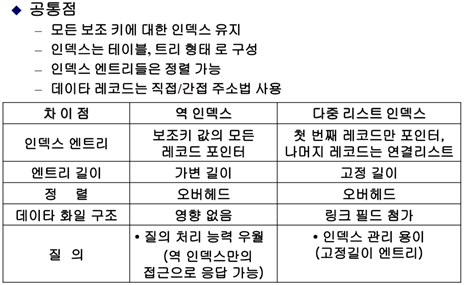
다중 리스트와 역 파일의 공통점과 차이점 정리
엔트리 길이[인덱스 파일에서 한 행의 길이]
-> ‘역 인덱스’는 ‘비유일 보조키에 대한 역 인덱스’를 생각하면 됨, 옆으로 계속 늘어남