
입출력 제어 시스템의 기능
1. 파일의 디렉토리를 유지
2. 주기억장치와 보조기억장치의 이동 통로(pathway)를 확립
3. CPU와 보조기억 장치 사이의 통신 조정 기능
(속도 차이를 조정, 송/수신자 사이의 데이터 전송 제어)
4. 입/출력으로 사용되는 파일 준비
5. 입/출력 완료 후 파일 관리
파일 디렉토리
: 파일의 이름, 저장 위치, 파일 크기, 파일 타입을 갖고 있음
파일 디렉토리의 구조: 계층 디렉토리
디렉토리 구조를 이용한 기본 연산
탐색(파일을 찾기 위해 디렉토리 탐색)
파일 생성(디렉토리에 첨가(트리에 첨가))
파일 삭제(디렉토리에서 삭제)
리스트 디렉토리(디렉토리 내용을 표시)
백업
입출력 장치 제어
– 데이터를 판독/기록하기 위한 작업
- 요구된 파일의 위치 탐색 (디렉토리 트리에서)
- 주기억장치와 접근 장치 사이의 통로 설정
- 입출력 연산 신호를 보냄
– 신호를 받는 장치
- 장치를 준비
- 입출력 작업 도중 오류 조치
- 작업의 성공 여부 전달
입출력 채널: < CPU,메인메모리 – 장치 제어기>의 중개자
- 제어 명령어(cpu->채널)
Test(지정된 통로까지 사용 여부 검사)->start-halt - 인터럽트(채널->cpu)
입출력 작업 완료 혹은 오류 검출 시 발생
프로그램의 파일 READ 요청 시 작업
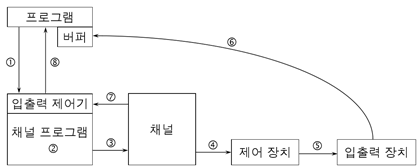
- 프로그램의 read명령을 만나면 파일 관리자(입출력 제어기)에게 인터럽트 발생
- 파일 관리자가 메인 메모리에 채널 프로그램 구성, I/O 채널 지정
- 지정 채널은 채널 프로그램을 읽어서 실행
- 지정된 디스크 제어 장치로 적절한 신호 전달 (디스크 이용해서 데이터 판독해보라는 신호)
- 디스크 제어기는 신호를 해석해서 요청한 데이터를 판독할 장치를 제어 (디스크 제어기가 보조기억장치 제어)
- 디스크 드라이브는 경로(pathway)를 따라서 주기억장치의 버퍼 영역으로 이동 (디스크 드라이브가 보조기억장치의 데이터를 pathway를 통해 ram으로 옮김)
- 채널은 인터럽트를 걸어서 입출력 연산 완료를 알림. 프로그램 수행을 재개하도록 OS에 전송
- 파일 관리자는 실행을 계속되게 함
Unix에서의 입출력
디스크 파일, 키보드, 콘솔 장치도 파일로 취급
파일 기술자: 파일 세부 정보를 저장한 배열의 인덱스 역할

커널의 I/O시스템이 관리하는 테이블
- 파일 기술자 테이블 – 프로그램 당 하나
(각 프로세스가 사용하는 파일을 기록하는 테이블) - 개방 파일 테이블 – 유닉스 전체에 하나
(현재 시스템이 사용 중인 개방 파일의 정보 저장) - 인덱스 노드 테이블
(파일의 위치,크기,타입,권한,소유자 등 기록) - 파일 할당 테이블
(파일이 실제로 저장된 디스크 블록의 리스트 (자기 디스크 001 같은 것))
– 파일 기술자 값이 3인 파일의 레코드 판독 명령
1. 프로그램의 ‘파일 기술자 테이블’에서 ‘개방 파일 테이블’을 이용
(개방 파일 테이블 중 [3번:일반파일]엔트리 검색)
2. ‘개방 파일 테이블’에 inode 테이블 포인터(루틴 포인터)가 있음.
그 포인터로 inode 테이블 엔트리를 확인함 (아래 그림은 ‘파일할당테이블(7)’)
3. ‘파일 할당 테이블’에서 디스크 블록 주소를 확인
4. 데이터 블록을 판독
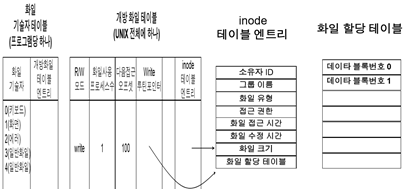
< 개발 파일 테이블 – 3번 엔트리 내용 >
버퍼 관리
버퍼
데이터를 읽어들이는 주기억장치 내의 일정 구역
버퍼 관리의 목적
CPU와 보조기억장치의 성능과 활용을 최대화
(둘 다 동시다발적으로 일을 하게 만듦)
버퍼 관리자가 하는 일
버퍼공간 할당, 사용하지 않는 버퍼 공간 관리
버퍼 요구량이 할당 가능 공간을 초과 시 -> 우선순위가 낮은(사용도가 낮은) 프로세스에 할당된 버퍼 공간을 회수
메모리 할당 기법
(아래는 버퍼에 16M을 저장하는 방식임)
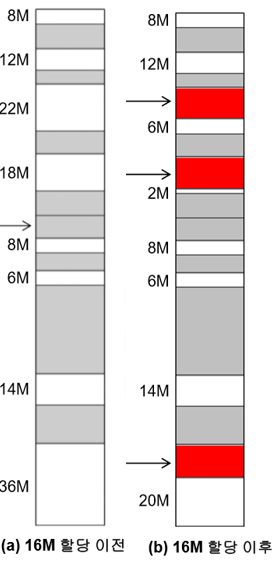
최초적합: 16MB를 담을 수 있는 공간을 위부터 찾아서 첫 번째 공간에 할당 <빨간 박스1>
최적적합: 16MB보다 크면서 가장 작은 공간에 할당 <빨간 박스2>
순환적합: 왼쪽 그림 화살표(마지막으로 할당된 블록 포인터)에서 시작해서 16MB를 담을 수 있는 공간을 찾아서 할당 <빨간 박스3>
<블록 요청 처리 과정>
– (버퍼에) 블록 테이블에서 요청한 블록이 있는가를 조사
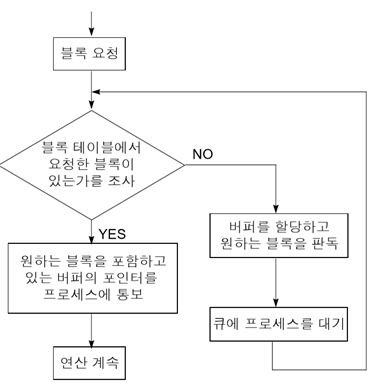
버퍼의 데이터 구조 (가정1)
하나의 레코드 = 하나의 블록 [NON-BLOCKING], 하나의 파일에 하나의 버퍼, 프로그램의 요구에 따라 버퍼가 채워짐
– 예상 버퍼링
프로그램이 필요로 할 데이터를 미리 예측(연속된 블록일 경우 -> 버퍼에 미리 채워 넣음)-> cpu가 버퍼에 꽉 찰 때까지 기다리는 시간을 조금이라도 줄임
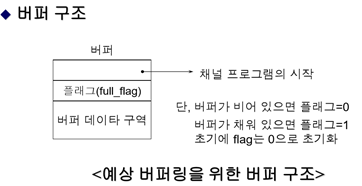
– 예상 버퍼링의 채널 프로그램 (가정에 근거함)
< 생산자 루틴과 소비자 루틴이 교대로 수행됨/ 채우자->비우자->…(반복) / flag 0과 1이 반복됨 >
1. 생산자 루틴

<공백이 될 때까지 대기=소비자가 갖다가 써서 비워질 때까지 대기>
2. 소비자 루틴

<공백이면 대기=생산자가 버퍼를 가득 채울 때까지 대기>
버퍼의 데이터 구조 (가정2)
N개의 레코드 = 하나의 블록 [BLOCKING], 하나의 파일에 하나의 버퍼, 프로그램의 요구에 따라 버퍼가 채워짐
매 n+1번째 READ에만 디스크에 접근하여 물리적 판독/기록 (블록1처리하고 다음 블록은 n+1번째 접근함)
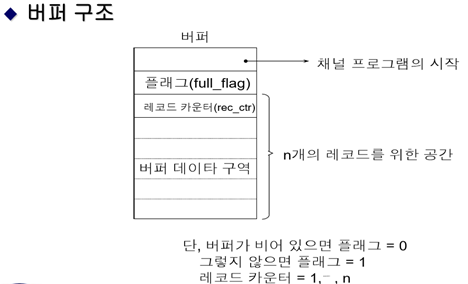
1. 생산자 루틴

레코드 카운터는 1로 초기화 (rec_ctr=1)
<버퍼에 블록을 다 채웠고 첫 번째 레코드부터 사용하면 된다.>
2. 소비자 루틴

1번 레코드를 작업 구역으로 가져와서 사용 -> counter 1증가 -> counter가 n일 때까지는 비우는 역할을 하고 n+1일 때는 다 비웠다고 알림 (플래그0)
<카운터가 k면 k번째 레코드를 사용하고 있다는 의미>
– 단순 버퍼 시스템의 단점
한 개의 버퍼에 n개의 레코드를 채우고 비우는 방식
1. n+1번째 READ를 요청할 때마다 CPU는 버퍼가 다 채워질 때까지 대기 상태
(n+1번째 READ가 돼야 새 블록을 접근하잖아 -> 새 블록을 버퍼에 넣고 작업 공간에 넣을 때까지 CPU는 대기해야지!)
2. 버퍼가 채워지는 동안 생산자는 버퍼를 채우기 위해 대기 상태
이중 버퍼 시스템
두 개의 버퍼에 각각 n개의 레코드를 채우고 비우는 방식, 하나를 비우는 동안 나머지 하나를 채움
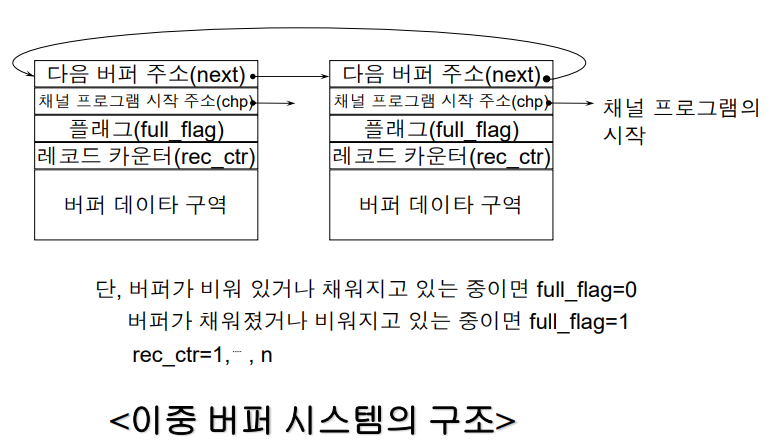

< 알고리즘 말로 설명 >
이중 버퍼 시스템은 to_fill과 to_empty라는 포인터를 사용한다. to_fill은 ‘현재 채워지고 있거나 다음에 채워야 할 버퍼의 포인터’로써 생산자 프로그램에서 사용한다. to_empty는 ‘현재 비워지고 있거나 다음에 비워져야 할 버퍼의 포인터’로써 소비자 프로그램에서 사용한다.
버퍼의 상태를 나타내는 플래그와 레코드를 가리키는 레코드 카운터도 버퍼 개수만큼 두 개를 가진다.
생산자와 소비자 입장에서 어떻게 버퍼 구조를 사용하는지 예시를 보이겠다.
초기 생산자 입장에서 to_fill은 첫 번째 버퍼를 가리키고 to_fill.flag는 0을 가진다. 버퍼를 채운 다음 flag를 1(다 채움)으로 바꾼다. 이후 두 번째 버퍼를 채워야 되니 to_fill은 다음 버퍼 포인터가 되는 것이다.
초기 소비자 입장에서 to_empty은 첫 번째 버퍼를 가리키고 flag가 0이니 대기한다. 만일 flag가 1이 되면 record n개를 work area로 이동하는 작업을 한다. 레코드 카운터가 (n+1)이 되면 버퍼에 담긴 n개의 레코드를 모두 처리했으니 flag를 0(다 비움)으로 바꾼다. 이후 두 번째 버퍼를 비워야 하니 to_empty는 다음 버퍼 포인터가 된다.
< 알고리즘 >

처음에는 flag는 모두 0 (empty_flag,fill_flag), to_fill은 1번 버퍼 가리킴 -> 버퍼 채움 -> full_flag =1 -> to_fill을 다음 버퍼 가리키게 함 (다음 버퍼 채워야 되니) -> 다음 버퍼의 flag도 0이면 일 진행, 1이면 대기

Full_flag =0 이니까 기다림, to_empty가 버퍼 1이고 채워짐 -> record를 n개 빼는 처리(작업 구역으로 이동) -> record_counter가 n+1이면 다 처리했다는 것이니 full_flag=0 -> to_empty는 다음 버퍼 가리키게 함 (다음 버퍼 빼야 되니) -> 다음 버퍼의 flag도 1이면 일 진행, 0이면 대기
< 이중버퍼시스템의 반복 >
생산자가 버퍼1을 채움
->
소비자가 버퍼1 다 쓰는 동안
생산자는 버퍼2 채우고 있음
->
소비자가 버퍼2 다 쓰는 동안
생산자는 버퍼1 채우고 있음 -> (반복)
단 생산자와 소비자의 일 처리 속도는 다를 수 있다.
(다 찰 때까지 기다리거나 다 비울 때까지 기다려야 됨, 그러나 대기시간을 훨씬 줄일 수 있음)
다중 버퍼 시스템의 장점
- CPU의 대기 시간을 줄일 수 있다
다중 버퍼 시스템의 단점
- 생산자나 소비자 루틴의 실행 시간 증가
- 메인 메모리의 소요량이 증가