
머신러닝을 소개한 포스팅 글을 미리 보고 오시면 도움이 됩니다!
이번 시간에는 지식 기반 방식과 머신러닝 방식을 알아보고
왜 머신러닝이 쓰이는 것인지, 학습은 어떤 방식으로 진행되는지 간단히 알아보겠습니다!
먼저 지식 기반 방식입니다!
지식 기반 알고리즘
: 데이터의 패턴을 직접 알려주는 방식
예를 들어 8이라는 숫자를 인식시켜 봅시다.
패턴을 직접 알려준다는 것은 IF문 따위의 조건문을 제시하는 것과 같습니다.
ex) 8이라는 숫자는 동그라미 두 개가 위, 아래로 존재해! -> 이 조건을 만족하면 8이야!
이후 컴퓨터에 이미지가 입력으로 들어오면, 조건을 만족했을 때 8을 출력하게 됩니다!
하지만 이 방법은 정확하다고 볼 수 없습니다.

위처럼 단추도 조건문에 부합하기 때문입니다!
즉 8이라는 것을 정확하게 정의하는 것은 쉽지 않습니다.
다음은 머신러닝 방식입니다!
머신러닝 알고리즘
: 데이터의 패턴을 찾는 방법을 알려주는 방식
마찬가지로 8이라는 숫자를 인식시켜 봅시다.
머신러닝은 컴퓨터에게 패턴을 찾는 방법(학습 방법)과 학습 데이터만 준 다음 스스로 학습해보라고 맡기는 것입니다.
사실 [컴퓨터가 패턴을 찾는 방법]은 여러가지가 있습니다.
그 중 기초적인 KNN이라는 방식을 예시로 보여 드리겠습니다.
0. 비슷한 데이터를 묶어보라는 학습 방법을 제시함
1. 학습 데이터 제시 -> 컴퓨터는 스스로 비슷한 것끼리 묶음
[ 학습 데이터: (숫자 이미지 + 이미지 정답) 모음 ]

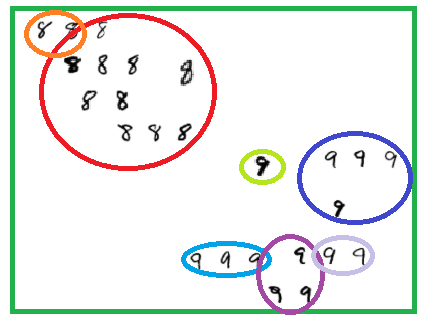
2. 새로운 데이터가 입력으로 옴 -> 학습한대로 묶움 -> 묶은 것을 기준으로 답을 제시
ex) 빨간 색 영역과 비슷한 것 같아 -> 빨간 색 영역으로 묶어야지 -> 빨간 색 영역은 8이라는 정답이네? -> 새로운 데이터도 8이야!
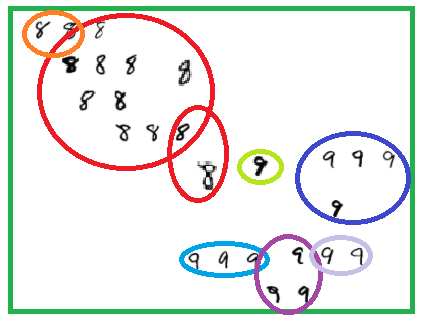
사실 이러한 방식은 [사람의 학습 방법]과 비슷한 측면이 있습니다.
바로 무언가를 알려줄 때 많은 데이터를 보여준다는 점입니다!
만약 아이에게 8과 9를 알려 준다면 위와 같이 숫자들을 많이 보여줄 것입니다!
ex) 이것은 8이야, 저것도 8이야, 이것은 9야, 저것도 9야
이런 식으로 말이죠!
물론 컴퓨터는 학습 알고리즘이 제시하는 방향으로 패턴을 찾고,
사람은 각자의 방법대로 학습을 할 것입니다!
다만 여기서 중요한 점은 사람의 학습 방법을 모방했을 때
즉 많은 데이터를 보여준다음 스스로 학습해보라고 했을 때
지식 기반 방식보다 성능이 더 높았다는 점입니다!
100% 정의할 수 있는 문제에 대해서는 지식 기반 방식이 압도적인 성능을 보이겠지만
세상에는 정의할 수 없는 문제가 너무나 많습니다.
하지만 우리 인간은 그것을 정의하지 않고도 알 수 있죠!
그래서 컴퓨터에게도 스스로 학습해보라고 하는 것입니다!
그저 학습 방향 제시와 데이터만 주고 말이죠!
하지만
사실 깊게 따지고 보면 복잡합니다.새로운 8이 기존의 8들과 비슷하다는 것을 컴퓨터에게 어떻게 알려줄까요?
사람처럼 생각을 하거나 느낌이 있는 것도 아니잖아요!
그래서 비슷하다는 것을 ‘수학적 계산’으로 알려줘야 합니다!
8이라는 그림에서 두 동그라미의 세로 길이 합, 각 동그라미의 가로 폭을 서로 비교하라고 하는 것이죠!
그렇게 해서 수치가 비슷하면 ‘아 이건 8이랑 비슷하구나!’ 라고 컴퓨터가 인식하게 하는 것입니다!
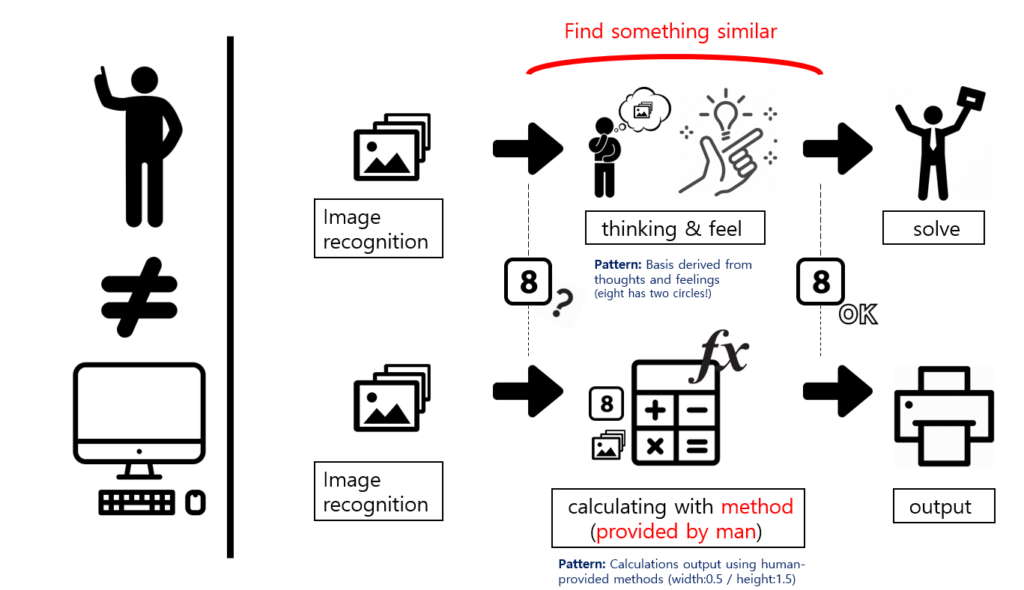
아래의 예시를 보고 자세히 이해해보세요!
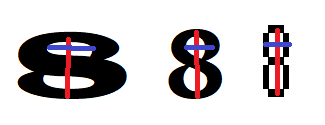


유클리드 거리 계산 식:
Dist(p,q) = { Sigma(i=1 -> n) (pi-qi)^2 } ^(1/2)
n: p,q의 좌표 개수

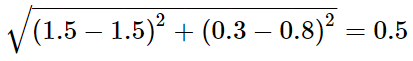


가장 거리가 작은 것이 비슷한 것이다.
학습 데이터 8(3)과 가장 비슷하다.
고로 새로 들어온 이미지는 ‘8’이다!
TMI
기존에 학습시킨 8의 이미지가 많을수록 8에 대한 수치 데이터가 많으니까 어떤 8이 와도 비슷한 것을 찾아낼 수 있습니다!
그래서 데이터가 많을수록 학습을 잘한다고 하는 것입니다!
결국 빅데이터와 인공지능(머신러닝)은 밀접한 관계라는 것이죠!
지금까지 간단하게 머신러닝 방식을 알아 보았습니다!
머신러닝 중 분류에 대한 학습을 한 것입니다!
머신러닝 알고리즘은 크게 (분류, 회귀)가 있습니다.
두 알고리즘 모두 크게 보면,
데이터를 많이 받았으니 스스로 패턴을 파악해봐!
입니다.
하지만 하나하나 세부적으로 따져 보면,
각자 방식으로 패턴을 알아보는 수학적 기법입니다.
따라서 머신러닝을 공부하다보면 (수학을 이용해서 스스로 학습을 어떻게 시킬까?) 에 대해 많이 고민하게 됩니다!
표면적으로는 사람의 학습법과 비슷하지만
세부적으로는 수학으로 해결해야 되죠?
그것이 바로 머신러닝의 특징입니다!
* 위 모든 내용은 학부생 수준인 필자가 주관적으로 작성한 글임을 밝힙니다. *