
KNN에 관한 포스팅:
https://shacoding.com/2019/12/07/mining-k-nearest-neighbor/
KNN을 이용해서
의료 데이터로 유방암 환자를 분류해보겠습니다.
# csv 파일 읽기
wbcd<-read.csv("wisc_bc_data.csv",stringsAsFactors = FALSE)
View(wbcd)
# 클래스 변수는 항상 요소형으로 잡아야함
# 요소의 수준은 B와 M, 화면에 찍을 때는풀네임을 보이게 했음
wbcd$diagnosis<-factor(wbcd$diagnosis,levels=c("B","M"),label=c("Benign","Malignant"))
# 비율 구하기 (소수점 첫 째자리까지)
# prop.table이 백분율 구하는 함수, round는백분율을 digits(1: 소수점 첫 째자리)만큼 나타내는 함수
round(prop.table(table(wbcd$diagnosis))*100,digits=1)
# 정규화
normalize<-function(x){
return ((x-min(x))/(max(x)-min(x)))
}
# 정규화 함수 테스트
normalize(c(1,2,3,4,5))
normalize(c(10,20,30,40,50))
# 테이블 정규화 (각 열 데이터를 정규화해서 리스트로 가지게 함, 이들을 합쳐서 데이터 프레임 형태로 만듦)
# 1열 id, 2열은 유방암 환자, 아닌 환자이므로 뺌
wbcd_n<-as.data.frame(lapply(wbcd[3:31],normalize))
View(wbcd_n)
# sample(range,x): 범위 중 랜덤 수를 x개 만큼 뽑아라
index<-sample(1:nrow(wbcd_n),nrow(wbcd_n)*0.7)
wbcd_train<-wbcd_n[index,]
wbcd_test<-wbcd_n[-index,]
# 시험문제의 답
wbcd_train_labels<-wbcd[index,2]
wbcd_test_labels<-wbcd[-index,2]
install.packages("class")
library(class)
# 룬련 데이터,시험 데이터,훈련 데이터 답
wbcd_test_pred<-knn(train=wbcd_train,test=wbcd_test,cl=wbcd_train_labels,k=21)
# 실제값과 예측값을 비교함
library(gmodels)
CrossTable(x=wbcd_test_labels,y=wbcd_test_pred,prop.chisq = FALSE)
# 최적의 k를 찾기
accuracy<-c()
for(i in 1:floor(nrow(wbcd)/2)){
wbcd_test_pred<-knn(train=wbcd_train,test=wbcd_test,cl=wbcd_train_labels,k=i)
rslt<-table(wbcd_test_pred,wbcd_test_labels)
accuracy<-c(accuracy,sum(diag(rslt))/sum(rslt))
}
# 벡터 내 가장 크기가 큰 요소의 번호
which.max(accuracy)
결과)
0) 의료 데이터 보기
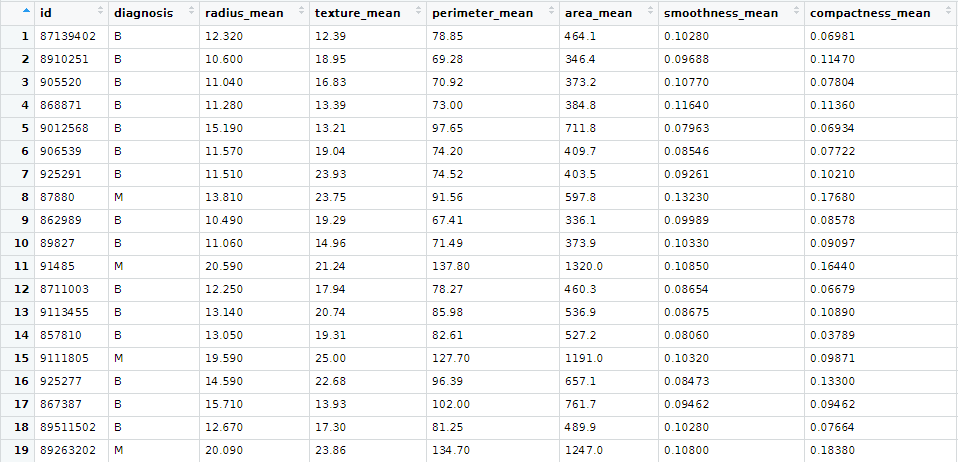
id는 환자의 id입니다. diagnosis는 양성인지,음성인지를 나타내는 변수로 양성은 B, 음성은 M입니다.
radius_mean부터는 의료 데이터 수치입니다.
diagnosis가 구하려는 답이 되고 , mean수치들을 이용해서 분류를 할 것입니다.
2) 화면에 보이는 데이터 다르게 하기
wbcd$diagnosis<-factor(wbcd$diagnosis,levels=c("B","M"),label=c("Benign","Malignant"))

B와 M을 요소로 가지는 diagnosis를 화면에 (“Benign”,”Malignant”)로 각각 보이게 수정하였습니다.
데이터 자체는 변하지 않고 화면에 보일 때만 위처럼 변합니다.
3) 유방암 환자의 비율보기
round(prop.table(table(wbcd$diagnosis))*100,digits=1)
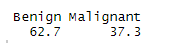
knn을 하기 전에 유방암 환자의 비율을 보며 데이터 분석도 실시해보았습니다.
4) 정규화
# 정규화
normalize<-function(x){
return ((x-min(x))/(max(x)-min(x)))
}
# 정규화 함수 테스트
normalize(c(1,2,3,4,5))
normalize(c(10,20,30,40,50))

거리 공식을 사용하는 knn을 사용하기 전에 정규화는 필수적입니다.
모든 x값이 0과 1사이에 오도록 정규화하는 함수 normalize를 만들어서 실험해보았습니다.
wbcd_n<-as.data.frame(lapply(wbcd[3:31],normalize)) View(wbcd_n)
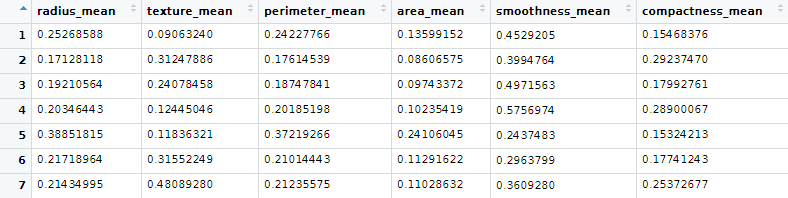
실험을 마쳤으니 실제 의료 데이터로 정규화를 하였습니다.
1열은 환자의 id고 2열은 정답이기 때문에 정규화하지 않았습니다.
5) 훈련 데이터와 시험 데이터 만들기
# sample(range,x): 범위 중 랜덤 수를 x개 만큼 뽑아라 index<-sample(1:nrow(wbcd_n),nrow(wbcd_n)*0.7) wbcd_train<-wbcd_n[index,] wbcd_test<-wbcd_n[-index,] # train 답, test 답 wbcd_train_labels<-wbcd[index,2] wbcd_test_labels<-wbcd[-index,2]
knn과 같은 지도학습은 train데이터와 test데이터를 필요로합니다.
지도학습에서 기계는 훈련 데이터(train)를 이용해 알고리즘을 훈련하고, 훈련된 모델을 만듭니다.
이후 시험 데이터(test)를 모델에 적용한 뒤 accuracy로 모델이 잘 만들어졌는지 평가합니다.
보통 훈련 데이터는 전체 데이터 중 70%를 이용하고
시험 데이터는 나머지 30%를 이용합니다.
지도학습은 ‘기계 학습을 통해 답을 내면( 훈련 데이터를 이용해 알고리즘을 훈련하면 ) 이 답이 맞았는지 틀렸는지를 컴퓨터가 알 수 있는 학습’ 입니다.
답이 맞았는지 틀렸는지를 알기 위해서는 실제 답이 필요하겠죠?
그래서 train의 답에 해당하는 train_labels가 만들어졌습니다.
위에서 wbcd_train은 훈련을 위해 의료 수치 데이터 중 70%를 가져온 데이터입니다.
wbcd_test는 모델이 잘 훈련됐는지 확인하기 위해 나머지 30%를 가져온 데이터입니다.
wbcd_train_label은 train으로 음성인지 양성인지 분류 학습한 것이 정답인지 알려주기 위한
데이터 (양성인지 음성인지 나타낸 데이터 중70%)입니다.
wbcd_test_labels는 기계학습 도중에는 쓰이지 않고, 모델을 평가할 때 사용됩니다.
6) KNN 학습 및 결과 도출
# 훈련 데이터,시험 데이터,훈련 데이터 답 wbcd_test_pred<-knn(train=wbcd_train,test=wbcd_test,cl=wbcd_train_labels,k=21) # 분류된 시험 데이터 평가 CrossTable(x=wbcd_test_labels,y=wbcd_test_pred,prop.chisq = FALSE)
다른 기계학습은 훈련 데이터를 이용해 모델을 만드는데 knn은 특별합니다.
코드 상 훈련 데이터와 시험 데이터를 한 번에 받습니다.
훈련 데이터는 그냥 저장만 하고, 시험 데이터가 왔을 때 훈련 데이터와 함께 knn알고리즘으로 분류하는 방식입니다.
위 과정으로 시험 데이터도 분류되면 wbcd_test에 결과가 저장됩니다.
이제 앞전에 만든 wbcd_test_labels데이터로 잘 분류됐는지 확인해봅시다!
보통 CrossTable이 모델이 잘 만들어졌는지 확인하는 용도지만,
knn은 모델이 없기 때문에 그냥 분류가 잘 됐는지 확인하는 용도입니다.
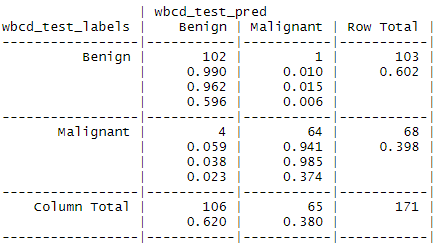
양성 102/106명 정답, 음성 64/65 정답
7) 최적의 k 찾기
# 최적의 k를 찾기
accuracy<-c()
for(i in 1:floor(nrow(wbcd)/2)){
wbcd_test_pred<-knn(train=wbcd_train,test=wbcd_test,cl=wbcd_train_labels,k=i)
rslt<-table(wbcd_test_pred,wbcd_test_labels)
accuracy<-c(accuracy,sum(diag(rslt))/sum(rslt))
}
# 벡터 내 가장 크기가 큰 요소의 번호
which.max(accuracy)
더 분류를 잘한다는 것은 accuracy가 높다는 의미입니다.
따라서 for문으로 k를 바꿔가며 knn을 여러 번 시행했습니다.
시행 결과는 wbcd_test_pred벡터에 저장되고,
분류 결과의 accuracy는 accuracy벡터에 저장됩니다.

정말 k=9일 때 최적인지를 알아보기 위해 knn을 시행하고 결과를 보았습니다.
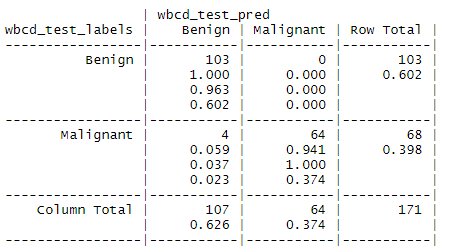
실제 유방암인 사람은 모두 유방암으로 판정된 결과가 도출됩니다!
지금까지 데이터 마이닝의 ‘K-NN’을 알아 보았습니다.